读paper: Wide & Deep Learning for …
1.背景介绍
推荐系统重要问题之一,解决memorization和generalization。memorization主要是基于历史数据 学习频繁共同出现的item,并且探索他们之间的相关性;generalization主要是基于相关性之间的传递, 探索历史上没有出现的新的特征的组合。memorization根据历史行为数据,推荐相关的item,generalization 实现了推荐的多样性问题。 google提出基于wide和deep结合的深度学习算法,解决google play中的app推荐。主要工作如下:
- deep neural networks和linear model的combination,l1-ftrl classifier,deep formard neural networks
- 将该算法应用在google play的apps中应用
- 基于tensorflow实现该算法,并且开源该算法的api接口
2.算法框架
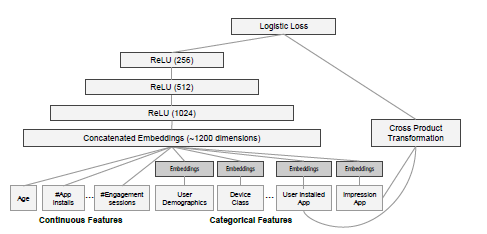
-
wide组件 y = wx + b, 特征组合cross,基于l1规范化的ftrl classifier.This captures the interactions between the binary features, and adds nonlinearity to the generalized linear model.
-
deep组件 deep forward neural network,激活函数是relu
- Joint Training of Wide & Deep Model
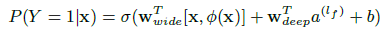
3.基于wide&deep的谷歌app推荐系统架构
app 推荐系统架构
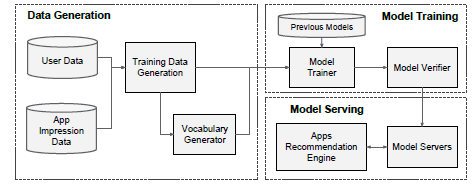
- 数据准备,数据离散化,转化成类别型变量处理
- 模型训练,We concatenate all the embeddings together with the dense features, resulting in a dense vector of approxi- mately 1200 dimensions. The concatenated vector is then fed into 3 ReLU layers, and nally the logistic output unit.
- 模型服务,将模型load到生产服务器,提供打分服务,从而进行app推荐
4.算法实现
code 基于tensorflow实现算法,提供开源的api接口。实例代码如下,基于开源数据集测试,
from __future__ import absolute_import from __future__ import division from __future__ import print_function import tempfile import urllib import pandas as pd import tensorflow as tf flags = tf.app.flags FLAGS = flags.FLAGS flags.DEFINE_string("model_dir", "", "Base directory for output models.") flags.DEFINE_string("model_type", "wide_n_deep", "Valid model types: {'wide', 'deep', 'wide_n_deep'}.") flags.DEFINE_integer("train_steps", 200, "Number of training steps.") flags.DEFINE_string( "train_data", "", "Path to the training data.") flags.DEFINE_string( "test_data", "", "Path to the test data.") COLUMNS = ["age", "workclass", "fnlwgt", "education", "education_num", "marital_status", "occupation", "relationship", "race", "gender", "capital_gain", "capital_loss", "hours_per_week", "native_country", "income_bracket"] LABEL_COLUMN = "label" CATEGORICAL_COLUMNS = ["workclass", "education", "marital_status", "occupation", "relationship", "race", "gender", "native_country"] CONTINUOUS_COLUMNS = ["age", "education_num", "capital_gain", "capital_loss", "hours_per_week"] def maybe_download(): """May be downloads training data and returns train and test file names.""" if FLAGS.train_data: train_file_name = FLAGS.train_data else: train_file = tempfile.NamedTemporaryFile(delete=False) urllib.urlretrieve("https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data", train_file.name) # pylint: disable=line-too-long train_file_name = train_file.name train_file.close() print("Training data is downlaoded to %s" % train_file_name) if FLAGS.test_data: test_file_name = FLAGS.test_data else: test_file = tempfile.NamedTemporaryFile(delete=False) urllib.urlretrieve("https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.test", test_file.name) # pylint: disable=line-too-long test_file_name = test_file.name test_file.close() print("Test data is downlaoded to %s" % test_file_name) return train_file_name, test_file_name def build_estimator(model_dir): """Build an estimator.""" # Sparse base columns. gender = tf.contrib.layers.sparse_column_with_keys(column_name="gender", keys=["female", "male"]) race = tf.contrib.layers.sparse_column_with_keys(column_name="race", keys=["Amer-Indian-Eskimo", "Asian-Pac-Islander", "Black", "Other", "White"]) education = tf.contrib.layers.sparse_column_with_hash_bucket( "education", hash_bucket_size=1000) marital_status = tf.contrib.layers.sparse_column_with_hash_bucket( "marital_status", hash_bucket_size=100) relationship = tf.contrib.layers.sparse_column_with_hash_bucket( "relationship", hash_bucket_size=100) workclass = tf.contrib.layers.sparse_column_with_hash_bucket( "workclass", hash_bucket_size=100) occupation = tf.contrib.layers.sparse_column_with_hash_bucket( "occupation", hash_bucket_size=1000) native_country = tf.contrib.layers.sparse_column_with_hash_bucket( "native_country", hash_bucket_size=1000) # Continuous base columns. age = tf.contrib.layers.real_valued_column("age") education_num = tf.contrib.layers.real_valued_column("education_num") capital_gain = tf.contrib.layers.real_valued_column("capital_gain") capital_loss = tf.contrib.layers.real_valued_column("capital_loss") hours_per_week = tf.contrib.layers.real_valued_column("hours_per_week") # Transformations. age_buckets = tf.contrib.layers.bucketized_column(age, boundaries=[ 18, 25, 30, 35, 40, 45, 50, 55, 60, 65 ]) # Wide columns and deep columns. wide_columns = [gender, native_country, education, occupation, workclass, marital_status, relationship, age_buckets, tf.contrib.layers.crossed_column([education, occupation], hash_bucket_size=int(1e4)), tf.contrib.layers.crossed_column( [age_buckets, race, occupation], hash_bucket_size=int(1e6)), tf.contrib.layers.crossed_column([native_country, occupation], hash_bucket_size=int(1e4))] deep_columns = [ tf.contrib.layers.embedding_column(workclass, dimension=8), tf.contrib.layers.embedding_column(education, dimension=8), tf.contrib.layers.embedding_column(marital_status, dimension=8), tf.contrib.layers.embedding_column(gender, dimension=8), tf.contrib.layers.embedding_column(relationship, dimension=8), tf.contrib.layers.embedding_column(race, dimension=8), tf.contrib.layers.embedding_column(native_country, dimension=8), tf.contrib.layers.embedding_column(occupation, dimension=8), age, education_num, capital_gain, capital_loss, hours_per_week, ] if FLAGS.model_type == "wide": m = tf.contrib.learn.LinearClassifier(model_dir=model_dir, feature_columns=wide_columns) elif FLAGS.model_type == "deep": m = tf.contrib.learn.DNNClassifier(model_dir=model_dir, feature_columns=deep_columns, hidden_units=[100, 50]) else: m = tf.contrib.learn.DNNLinearCombinedClassif
5.参考资料
Wide & Deep Learning for Recommender Systems
tensorflow
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

