性能测试中服务器关键性能指标浅析

关于CPU资源,有三个重要概念是我们需要关注的:使用率、运行队列和上下文切换,这里借助一张描述进程状态的图来进行简要说明:
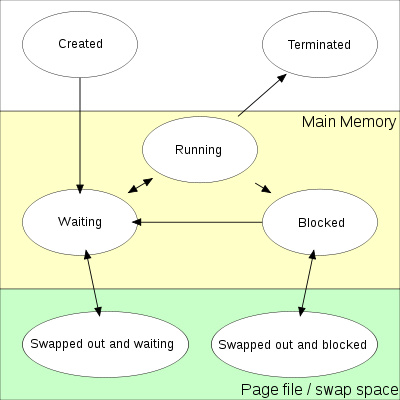
图1 Process state -via wikipedia
- Running :正在运行的进程
- Waiting :已准备就绪,等待运行的进程
- Blocked :因为等待某些事件完成而阻塞的进程,通常是在等待I/O,如Disk I/O,Network I/O等。
这里的Running和Waiting共同构成Linux进程状态中的 可运行状态(task_running) ,而Blocked状态可以对应Linux进程状态中的 不可中断睡眠状态(task_uninterruptible)
在Linux可以使用 vmstat 来获取这些数据:
[hbase@ecs-097 ~]$ vmstat 1 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 6 0 0 4591436 176804 1185380 0 0 0 0 7915 10357 83 5 12 0 0
CPU使用率(CPU Utilization Percentages):有进程处于Running状态的时间/总时间。在vmstat主要通过 us 、 sys 和 id 三列数据来体现:
- us:用户占用CPU的百分比
- sy:系统(内核和中断)占用CPU的百分比
- id:CPU空闲的百分比
性能测试指标中,CPU使用率通常用us + sy来计算,其可接受上限通常在70%~80%。另外需要注意的是,在测试过程中,如果sy的值长期大于25%,应该关注in(系统中断)和cs(上下文切换)的数值,并根据被测应用的实现逻辑来分析是否合理。
运行队列进程数(Processes on run queue):Running状态 + Waiting状态的进程数,展示了正在运行和等待CPU资源的任务数,可以看作CPU的工作清单,是判断CPU资源是否成为瓶颈的重要依据。vmstat通过 r 的值来体现:
- r: 可运行进程数,包括正在运行(Running)和已就绪等待运行(Waiting)的。
如果r的值等于系统CPU总核数,则说明CPU已经满负荷。在负载测试中,其可接受上限通常不超过CPU核数的2倍。
上下文切换(Context Switches):简单来说,context指CPU寄存器和程序计数器在某时间点的内容,(进程)上下文切换即kernel挂起一个进程并将该进程此时的状态存储到内存,然后从内存中恢复下一个要执行的进程原来的状态到寄存器,从其上次暂停的执行代码开始继续执行至频繁的上下文切换将导致sy值增长。vmstat通过cs的值来体现:
- cs:每秒上下文切换次数。
另外还有一个指标用来作为系统在一段时间内的负载情况的参考:
平均负载Load Average:在UNIX系统中,Load是对系统工作量的度量。Load取值有两种情况,多数UNIX系统取运行队列的值(vmstat输出的r),而 Linux系统取运行队列的值 + 处于 task_uninterruptible 状态的进程数(vmstat输出的b) ,所以会出现CPU使用率不高但Load值很高的情况。Load Average就是在一段时间内的平均负载,系统工具top、uptime等提供1分钟、5分钟和15分钟的平均负载值。
[hbase@ecs-097 ~]$ top top - 19:23:28 up 18:05, 3 users, load average: 0.80, 0.60, 0.53
上面示例中的0.80即是1分钟内的Load average,以此类推。
当我们需要了解当前系统负载情况时,可以先查看Load average的值,如果系统持续处于高负载(如15分钟平均负载大于CPU总核数的两倍),则查看vmstat的r值和b值来确认是CPU负荷重还是等待I/O的进程太多。
二. Memory
Memory资源也有三方面需要重点关注:可用内存,swap占用,页面交换(Paging),仍然借助一张图来说明:
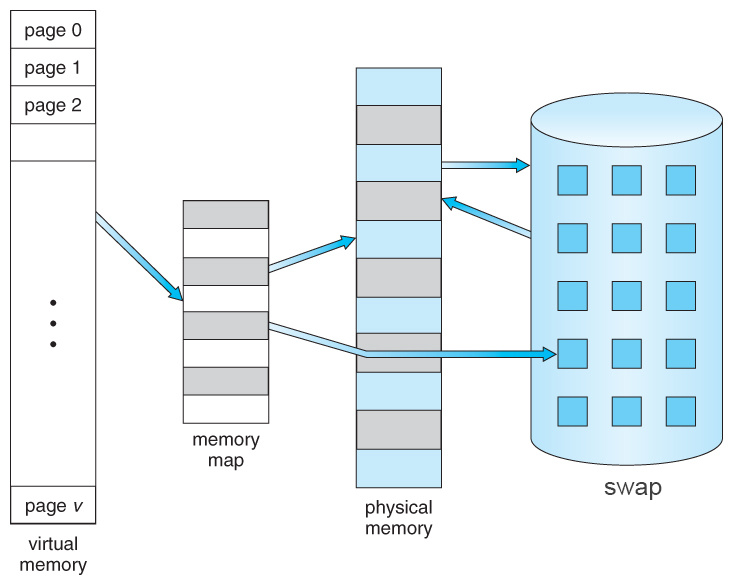
图2 Virtual Memory
这里讲到的内存,包括物理内存和虚拟内存,如上图所示,物理内存和硬盘上的一块空间(SWAP)组合起来作为虚拟内存(Virtual Memory)为进程的运行提供一个连续的内存空间,这样的好处是进程可用的内存变大了,但需要注意的是,SWAP的读写速度远低于物理内存,并且物理内存和swap之间的数据交换会增加系统负担。虚拟内存被分成页(x86系统默认页大小为4k),内核读写虚拟内存以页为单位,当物理内存空间不足时,内存调度会将物理内存上不常使用的内存页数据存储到磁盘的SWAP空间,物理内存与swap空间之间的数据交换过程称为页面交换(Paging)。
可用内存(free memory):内存占用的直观数据,vmstat输出free的值,可用内存过小将影响整个系统的运行效率,对于稳定运行的系统,free可接受的范围通常应该大于物理内存的20%,即内存占用应该小于物理内存的80%。在压力测试时,系统内存资源的情况应该用可用内存结合页面交换情况来判断,如果可以内存很少,但页面交换也很少,此时可以认为内存资源还对系统性能构成严重影响。
页面交换(Paging):页面交换包括从SWAP交换到内存和从内存交换到SWAP,如果系统出现频繁的页面交换,需要引起注意。可以从vmstat的si和so获取:
- si:每秒从SWAP读取到内存的数据大小
- so:每秒从内存写入到SWAP的数据大小
SWAP空间占用:可以从vmstat的swpd来获取当前SWAP空间的使用情况,应该和页面交换结合来分析,比如当swpd不为0,但si,so持续保持为0时,内存资源并没有成为系统的瓶颈。
三. Disk
磁盘通常是系统中最慢的一环,一是其自身速度慢,即使是SSD,其读写速度与内存都还存在数量级的差距,二是其离CPU最远。另外需要说明的是磁盘IO分为 随机IO 和 顺序IO 两种类型,在性能测试中应该先了解被测系统是偏向哪种类型。
- 随机IO:随机读写数据,读写请求多,每次读写的数据量较小,其IO速度更依赖于磁盘每秒能IO次数(IOPS)。
- 顺序IO:顺序请求大量数据,读写请求个数相对较少,每次读写的数据量较大,顺序IO更重视每次IO的数据吞吐量。
对于磁盘,首要关注使用率,IOPS和数据吞吐量,在Linux服务区,可以使用iostat来获取这些数据。
[hbase@ecs-097 ~]$ iostat -dxk 1
Linux 2.6.32-504.3.3.el6.x86_64 (ecs-097) 08/01/2016 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.52 0.00 0.13 0.06 0.00 99.28
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
xvda 0.10 6.63 0.40 2.57 6.22 36.80 29.00 0.04 14.63 1.19 0.35
(设备)使用率:统计过程中处理I/O请求的时间与统计时间的百分比,即iostat输出中的%util,如果该值大于60%,很可能降低系统的性能表现。
IOPS:每秒处理读/写请求的数量,即iostat输出中的r/s和w/s,个人PC的机械硬盘IOPS一般在100左右,而各种公有云/私有云的普通服务器,也只在百这个数量级。预先获取到所用服务区的IOPS能力,然后在性能测试中监控试试的IOPS数据,来衡量当前的磁盘是否能满足系统的IO需求。
数据吞吐量:每秒读/写的数据大小,即iostat输出中的rkB/s和wkB/s,通常磁盘的数据吞吐量与IO类型有直接关系,顺序IO的吞吐能力明显优与随机读写,可以预先测得磁盘在随机IO和顺序IO下的吞吐量,以便于测试时监控到的数据进行比较衡量。
四. Network
网络本身是系统中一个非常复杂的部分,但常规的服务端性能测试通常放在一个局域网进行,因为我们首先关注被测系统自身的性能表现,并且需要保证能在较少的成本下发起足够大的压力。因此对于多数系统的性能测试,我们主要关注网络 吞吐量 即可,对于稳定运行的系统,需要为被测场景外的业务流出足够的带宽;在压力测试过程中,需要注意瓶颈可能来自于带宽。
在Linuxf服务器,可以使用iptraf来查看本机网络吞吐量,如:
[root@ecs-097 ~]# iptraf -d eth0 x Total rates: 67.8 kbits/sec Broadcast packets: 0 x x 54.2 packets/sec Broadcast bytes: 0 x x x x Incoming rates: 19.2 kbits/sec x x 25.4 packets/sec x x IP checksum errors: 0 x x Outgoing rates: 48.7 kbits/sec x x 28.8 packets/sec
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

