storm基础框架分析
背景
前期收到的问题:
1、在Topology中我们可以指定spout、bolt的并行度,在提交Topology时Storm如何将spout、bolt自动发布到每个服务器并且控制服务的CPU、磁盘等资源的?
2、Storm处理消息时会根据Topology生成一棵消息树,Storm如何跟踪每个消息、如何保证消息不丢失以及如何实现重发消息机制?
上篇:storm是如何保证at least once语义的
回答了第2个问题。
本篇来建立一个基本的背景,来大概看下构成storm流式计算能力的一些基础框架,并部分回答第一个问题。
worker、executor、task的关系
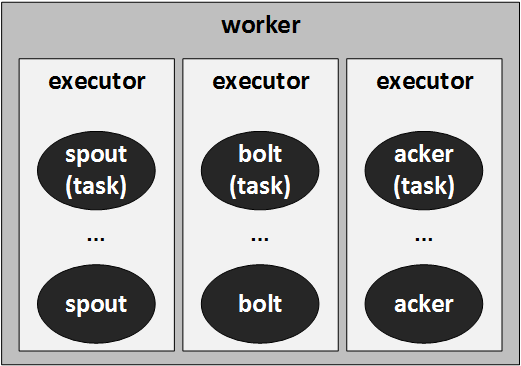
worker是一个进程.
executor是一个线程,是运行tasks的物理容器.
task是对spout/bolt/acker等任务的逻辑抽象.
supervisor会定时从zookeeper获取拓补信息topologies、任务分配信息assignments及各类心跳信息,以此为依据进行任务分配。
在supervisor同步时,会根据新的任务分配情况来启动新的worker或者关闭旧的worker并进行负载均衡。
worker通过定期的更新connections信息,来获知其应该通讯的其它worker。
worker启动时,会根据其分配到的任务启动一个或多个executor线程。这些线程仅会处理唯一的topology。
如果有新的tolopogy被提交到集群,nimbus会重新分配任务,这个后面会说到。
executor线程负责处理多个spouts或者多个bolts的逻辑,这些spouts或者bolts,也称为tasks。
具体有多少个worker,多少个executor,每个executor负责多少个task,是由配置和指定的parallelism-hint共同决定的,但这个值并不一定等于实际运行中的数目。
如果计算出的总的executors超过了nimbus的限制,此topology将不会得到执行。
并行度的作用:

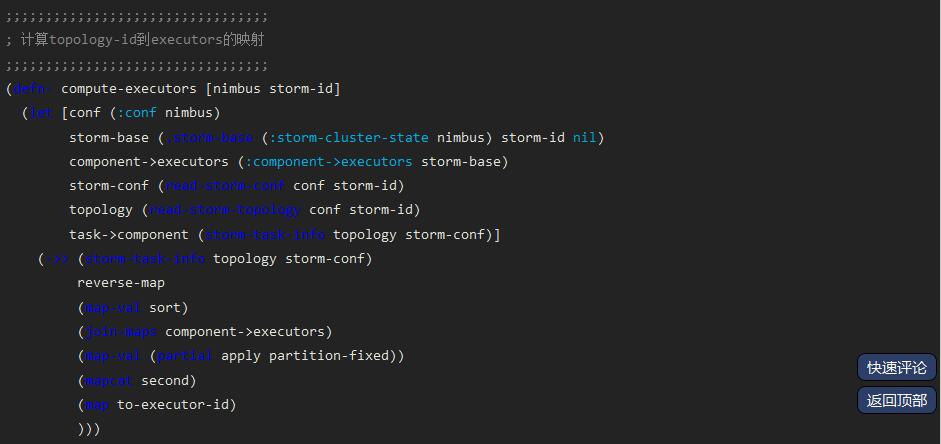
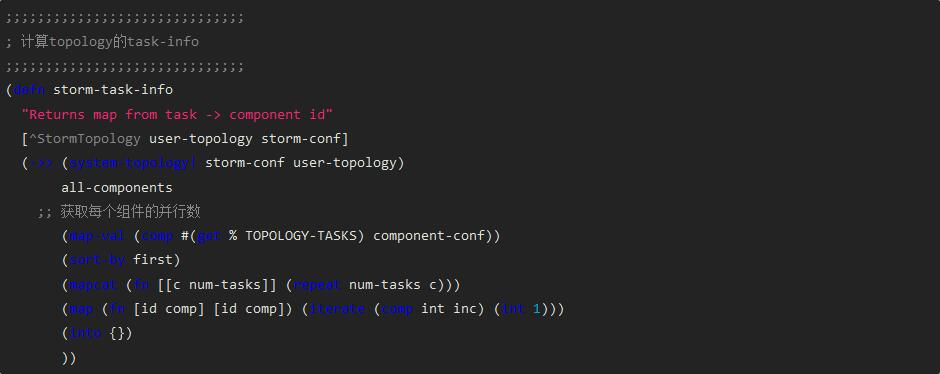
上述代码会在nimbus进行任务分配时调用:

线程模型及消息系统
基本关系如下所示:
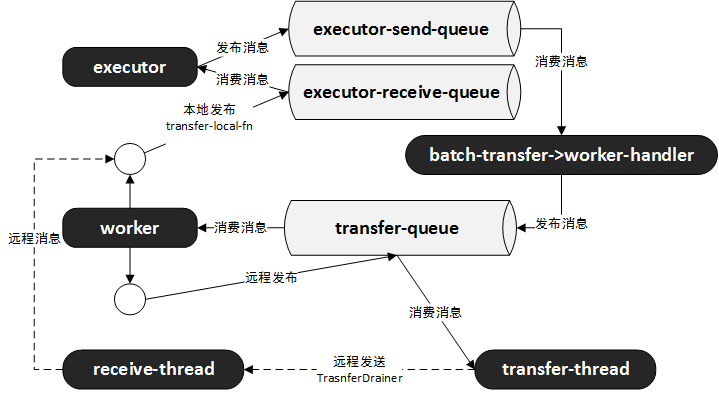
worker启动时,除了启动多个executor线程,还会启动多个工作线程来负责消息传递。
worker会订阅到transfer-queue来消费消息,同时也会发布消息到transfer-queue,比如需要进行远程发布时(某个bolt在另一个进程或者节点上)。
executor会发布消息到executor-send-queue比如emit tuple,同时会从executor-receive-queue消费消息,比如执行ack或者fail。
batch-transfer-worker-handler线程订阅到executor-send-queue消费消息,并将消息发布到transfer-queue供worker消费。
transfer-thread会订阅到transfer-queue消费消息,并负责将消息通过socket发送到远程节点的端口上。
worker通过receive-thread线程来收取远程消息,并将消息以本地方式发布到消息中指定的executor对应的executor-receive-queue。executor按第3点来消费消息。
以上所有的消息队列都是Disruptor Queue,非常高效的线程间通讯框架。
所谓本地发布,是指在worker进程内及executor线程间进行消息发布。
所谓远程发布,是指在worker进程间、不同的机器间进行消息发布。
任务调度及负载均衡
任务调度的主要角色
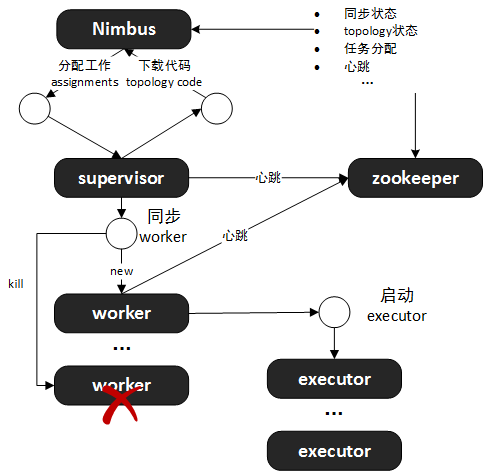
nimbus将可以工作的worker称为worker-slot.
nimbus是整个集群的控管核心,总体负责了topology的提交、运行状态监控、负载均衡及任务重新分配,等等工作。
nimbus分配的任务包含了topology代码所在的路径(在nimbus本地)、tasks、executors及workers信息。
worker由node + port唯一确定。
supervisor负责实际的同步worker的操作。一个supervisor称为一个node。所谓同步worker,是指响应nimbus的任务调度和分配,进行worker的建立、调度与销毁。
其通过将topology的代码从nimbus下载到本地以进行任务调度。
任务分配信息中包含task到worker的映射信息task -> node + host,所以worker节点可据此信息判断跟哪些远程机器通讯。
集群的状态机:
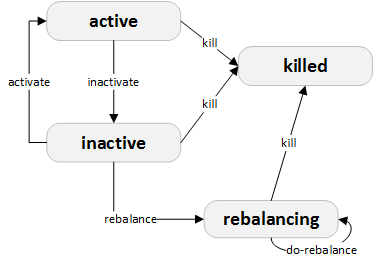
集群状态管理
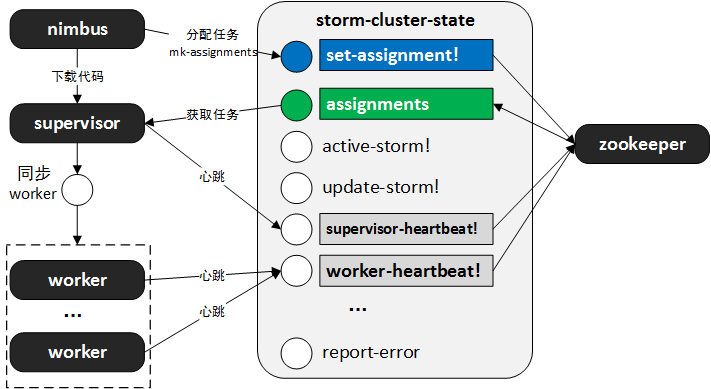
集群的状态是通过一个storm-cluster-state的对象来描述的。
其提供了许多功能接口,比如:
zookeeper相关的基本操作,如create-node、set-data、remove-node、get-children等.
心跳接口,如supervisor-heartbeat!、worker-heatbeat!等.
心跳信息,如executors-beats等.
启动、更新、停止storm,如update-storm!等.
如下图所示:
任务调度的依据
zookeeper是整个集群状态同步、协调的核心组件。
supervisor、worker、executor等组件会定期向zookeeper写心跳信息。
当topology出现错误、或者有新的topology提交到集群时,topologies信息会同步到zookeeper。
nimbus会定期监视zookeeper上的任务分配信息assignments,并将重新分配的计划同步到zookeeper。
所以,nimbus会根据心跳、topologies信息及已分配的任务信息为依据,来重新分配任务,如下图所示:

任务调度的时机
如上文的状态机图所示,rebalance和do-reblalance(比如来自web调用)会触发mk-assignments即任务(重新)分配。
同时,nimbus进程启动后,会周期性地进行mk-assignments调用,以进行负载均衡和任务分配。
客户端通过storm jar ... topology 方式提交topology,会通过thrift接口调用nimbus的提交功能,此时会启动storm,并触发mk-assignments调用。
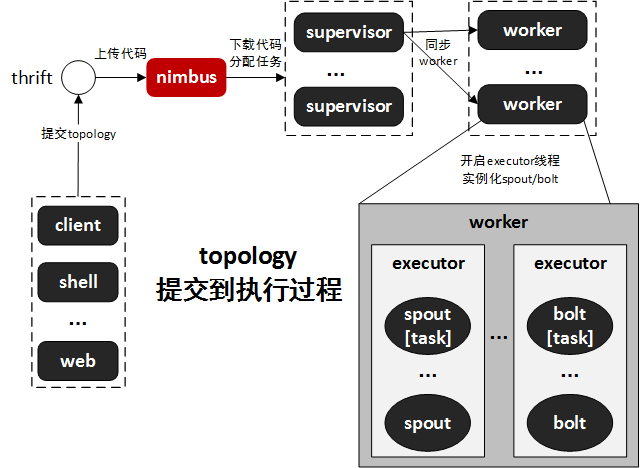
topology提交过程
一个topology的提交过程:
非本地模式下,客户端通过thrift调用nimbus接口,来上传代码到nimbus并触发提交操作.
nimbus进行任务分配,并将信息同步到zookeeper.
supervisor定期获取任务分配信息,如果topology代码缺失,会从nimbus下载代码,并根据任务分配信息,同步worker.
worker根据分配的tasks信息,启动多个executor线程,同时实例化spout、bolt、acker等组件,此时,等待所有connections(worker和其它机器通讯的网络连接)启动完毕,此storm-cluster即进入工作状态。
除非显示调???kill topology,否则spout、bolt等组件会一直运行。
主要过程如下图所示:
结语
以上,基本阐述了storm的基础框架,但未涉及trident机制,也基本回答了问题1。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

