SAP Anywhere产品背后CD的实现
分享主题
SAP Anywhere产品背后CD的实现
个人简介
陈贇喆 (Miles Chen),资深开发工程师、全栈工程师、系统架构师。从业十年有余,目前就职SAP中国研究院,担任架构师一职,负责SAP Anywhere产品的CI/CD工作。
正文
- SAP Anywhere产品特性及开发团队简介 - CD需要解决的问题是什么
大家好,我是来自SAP中国研究院SME部门的系统架构师,目前从事SAP Anywhere产品的CI/CD工作。今天的分享主题是SAP Anywhere产品背后CD的实现。我们在这方面还刚起步,分享内容颇有疏漏,还请见谅。
首先,请允许我使用只言片语介绍一下SAP Anywhere的产品特性,以及CD需要解决什么样的问题。我们的产品SAP Anywhere是一套基于Cloud的ERP SaaS解决方案,产品UI是纯HTML5实现的WebUI以及Hybrid模式的MobileUI,后端由接近三十个微服务组成,通过API-Gateway向外统一暴露。
由于大公司的原因,我们的开发团队分散在世界各地,总共有超过200人提交代码,平均每天提交300多次。CI要解决的问题是提供一个稳定高效的平台使每一位开发人员的每一次提交可以得到即时的构件,进而阻挡那些“有害”提交。当代码通过CI自动构件及测试后,会被合并到主分支,下一步是自动化搭建一个DEMO系统以供开发及测试人员进一步测试。
而搭建DEMO系统的难点在于微服务化的架构 – 部署一个巨石服务(Monolithic)相比部署一堆分布式“微服务”是要简单很多的。事实上,当引入服务之间的依赖关系和服务发现之后,会把问题更加复杂化。
为了解决这些问题,我们引入了Jenkins Pipeline, Kubernetes等一系列组建来帮助我们搭建CD系统。
- Jenkins, Docker, Kubernetes - CD基础部件的组成
再来介绍一下组成CD的基础部件。我们搭建了多套Kubernetes集群,分别用于跑Jenkins,跑CI的slow-test,以及部署DEMO环境。所以我们的基础组建是Docker, Jenkins和Kubernetes。除了Jenkins集群使用的是物理机,其他机器全部是vSphere的虚拟机。此外,我们也在AWS上搭建了集群。
使用物理机是为了得到更好的IO性能(从而加速构件过程),而使用虚拟机是为了得到更方便的管理能力。这里是一处典型的需要平衡考虑的地方。
操作系统方面我们选择了CoreOS及少量的Ubuntu用做build machine。网络方案是常用的flannel overlay network,backend是vxlan。
Kubernetes Admission Controller使用了推荐的ServiceAccount, LimitRanger及NamespaceLifecycle。Addon选择了dashboard, heapster, grafana monitoring以及skydns。
事实上,我们强制要求每个微服务必须至少使用HTTP协议提供REST API,且其端口必须是80,这样我们可以让服务之间相互发现变得简单及统一 – 使用skydns作为服务发现!(比如获取所有未开发票可以调用 http://invoice:80/api/v1/Invoices?status=open ,按地区查询客户信息则调用 http://customer:80/api/v1/Customers?location=CN ,当然,端口号80可以省略)
与zookeeper解决方案不同的是,我们并没有使用服务注册机制来实现服务发现,算不上是创新,只是另一种思路而已。
- Jenkins Pipeline, 自动化测试, 自动化部署 - CD的实现
跑题了,我们继续讲CD。为了使得每一位开发人员的每一次提交能快速准确的通过CI构件及自动化测试,我们在Jenkins 2.0 Pipeline插件的基础上,构件了我们自己的CD Pipeline,用于验证我们的每一次提交。
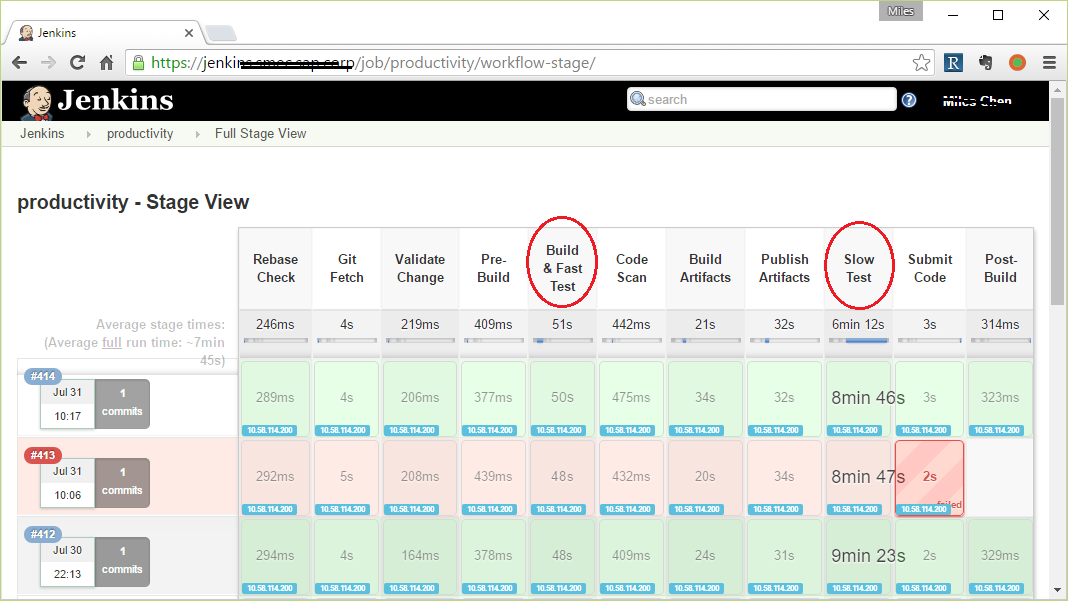
如图,每一横条代表一次代码提交的完整过程。核心步骤是Build & Fast Test及Slow-Test。前者负责构件及单元测试(通常是mvn install, gradle build, gulp build),后者负责搭建一个“半完整”环境执行“集成测试”。任何一步失败会导致当前这次提交被拒绝。我们为60多个git repo分别搭建了对应的CD pipeline,上图是其中一个微服务,名字叫productivity。
CD pipeline的最后一步post-build里面,我们会触发一次基于当前提交的DEMO系统搭建。通常10分钟左右就可以部署出一套完整的DEMO系统交付给开发测试人员了。通过这种方式,可以大幅度缩短我们的开发迭代周期。
- 排错, 诊断, 监控, 分析 - CD的后勤保障
任何系统都少不了监控,尤其是分布式系统。为了帮助开发人员在DEMO系统中快速定位问题,我们使用了ELK系统来回收并展现微服务日志。与此同时,我们把大量的日志文件扔进HADOOP系统做大数据分析以进而优化产品本身。
我们还使用Kubernetes原生的health check机制来监控服务健康状况,这意味着每个微服务必须要提供一个HTTP REST API,如/health,以告知其健康情况。当/health返回非200状态码时,服务会被杀掉并重启。
通常,一套30个节点的集群可以跑20套DEMO系统,我们使用Kubernetes namespace隔离每个系统。前面有提到LimitRanger,我们为每个namespace分配一个默认的resource limits,比如执行每个container至少需要64M内存及0.2个逻辑cpu,而每个container最多只能消费1G内存及1个逻辑cpu。自从使用LimitRanger以来,我们的集群稳定性大为提升。
经过长期的运维观察,我们发现节点上的Docker daemon会时不时死亡。其表现为不能创建销毁container,不能docker ps。为了缓解这个问题,我们使用Kubernetes DaemonSet开发了watchdog跑在每个节点上,但凡遇到daemon死亡就暴力重启节点。
- Q&A
好了,分享到此结束,下面是问答时间。
Q1:您好,我想了解下你们开发的daemonset可不可以用supervisor这样的去替代,如果可以需要注意些什么,之前监控web 遇到过web 服务200,实际web 服务已经挂起的情况,如何监控类似事件?
A1:DaemonSet是k8s的一种功能,用来把POD调度到所有满足条件的节点上。我们的使用场景是把看家狗程序调度到每一个集群里的节点,以起到监控作用。
Q2:你们主要跑的什么类型的应用?
A2:我们的业务是基于WEB-UI的ERP产品
Q3:请问k8s使用health check http请求的时候有没有遇到容器可能本身需要好久才能启动完毕那么这个人机制就会一直死循环…请问这个有没有好的方式解决?
A3:k8s health check分成readinessProbe和livenessProbe。前者决定容器是否ready,后者当检查失败后直接暴力杀死容器。某些容器启动较慢,所以需要设定一个等待时间。我们的容器等待时间是readiness->15s, liveness->2min
Q4: 后来,我们按功能把原先的一个集群拆分成了多个,分别运维,如此一来,稳定性大为提升 ”,这个怎么拆的呢?
A4: 根据功能拆。比如一个集群专门跑Jenkins,另一个集群专门跑slow-test。BTW,slow-test是用来进一步验证当前提交是否存在bug的一种测试,由于跑的时间比较长,所以叫slow-test
Q5: k8s api-server经常宕机?到规模上限了?api-server可以起多个做负载均衡吧,apiserver宕机的时候scheduler和controller-manager到瓶颈了么?
A5: 早期的宕机可能是我们自己使用不当,比如把api-server交给每一个开发人员(我们有200多人),然后大家都去玩kubectl各种命令,里面有几个命令比较吃资源,一种是port-forward,另一种是watch kubectl get pod ...
Q6: 对于应用的配置你们如何管理?
A6: 这是个好问题。我们内部讨论的比较激烈。目前有两种极端,一类人倾向于每个服务自己管理配置;另一类人倾向提供一个专门的配置微服务。各有利弊吧。
Q7: 一个DEMO系统是否包括依赖的服务?如果依赖,那假如DEMO系统中多个服务需要发布,要每个都起一套DEMO系统吗?
A7: 前文提到我们有接近30个微服务,是的,每一套DEMO系统都包含那么多微服务,所以做一套DEMO系统挺“重”的。当然我们在搭建DEMO系统时,主要还是利用了K8S的调度能力来并行处理任务的。
Q8: web-ui应用有没有涉及到负载均衡可以介绍一下的?
A8: 我们使用nginx作为反向代理,k8s的deployment/rs作为负载均衡。nginx upstrea/server编写服务的内部域名,被skydns解析成cluster ip, 再被ip tables做round robin路由到真实pod
Q9: 根据功能拆。比如一个集群专门跑Jenkins,另一个集群专门跑slow-test。BTW,slow-test是用来进一步验证当前提交是否存在bug的一种测试,由于跑的时间比较长,所以叫slow-test
你们原来是混在一个集群里的啊?
A10: 是的,早期我们是跑在一个集群里的。那时候我们膜拜k8s,认为谷歌大师级的产品一定能很好的利用异构系统组成集群,并且良好的管理里面的应用的。事实比较令人遗憾,当然不排除我们自己代码的问题,总之跑在一起比较不稳定,而且遇到故障时比较难恢复(因为影响面比较大)
Q1:您好,我想了解下你们开发的daemonset可不可以用supervisor这样的去替代,如果可以需要注意些什么,之前监控web 遇到过web 服务200,实际web 服务已经挂起的情况,如何监控类似事件?
A1:补充一下第一个问题的答复:监控web服务,这个需要服务自己暴露(实现)一个特殊的API,通常可以是 /heath,然后服务自己在API里面完成健康扫描。那么k8s就知道服务是否处于僵尸状态了。
Q10: 你们的k8s api有没开启https?如果开启是否有在pod访问api的案例介绍一下?
A10: 事实上,我们开启了https,但是在大部分情况下,我们仍然使用http端口连接api-server。我们下一个目标就是全面启用授信的安全模式。至于pod访问api-server只要有service token即可。
Q11: 你好,把Jenkins和slowtest拆分集群是按命名空间分了,还是再单独部署了另外一套k8s
A11: 我说的拆分是指物理上的拆分,变成两个k8s集群了。这方面我们仍然在摸索,到底是多个小集群容易管理还是一个大集群容易管理。
Q12:有考虑过使用docker官方的swarm吗?新手,不知道该选择哪个
A12:k8s和docker swarm天生就是两种教派,有点“正邪不两立”的味道。事实上,我们早期做原型的时候有考虑过mesosphere。
A12补充:个人观点:从目前的发展来看k8s和swarm很难走到一起去,这意味着选择其中之一必然会放弃另一个。而k8s是谷歌主推的,考虑到谷歌内部borg系统是k8s的原型,每天跑着百万级的应用,应该不会有错的
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

