解读calvin
注:阅读本文需预备 2pc ,分布式时钟,分布式一致性,事务边界等相关知识。
当前,很多的分布式数据库系统,为了高扩展性,高系统吞吐,而放弃事务支持。而calvin利用了明确事务的确定性的方式实现了满足acid的分布式事务,同时,使系统事务吞吐随着集群的扩展达到了接近线性的增长。
calvin中最大的特点在于它的事务处理的机制。从这个角度出发,我们需要先明确的阐述,calvin中的确定性事务到底是个什么东西。有别于传统数据库的事务模型,calvin的事务归类为确定性的,可以简单的理解为事务是作为一个类似存储过程的方式提交给数据库进行的。一个存储过程必须是一个事务,当客户端发起事务时,直接调用这个存储过程。(是不是感觉在描述voltdb的事务)
为了方便理解calvin中的事务,我们引入了图1,图2。

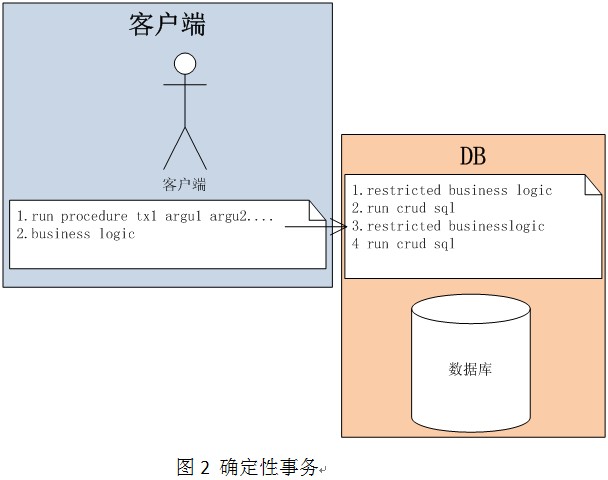
注:restricted business logic ,这里指的是用存储过程可以写出的逻辑,例如,判断库存是否为0。在这里我们假定的是远程服务调用,是不被restricted business logic 所支持的。
基于图1,图2 ,我们来做一个传统事务与calvin确定性事务间的对比
| 传统事务 | Calvin事务 | |
| 事务的begin,commit | 发生在客户端业务逻辑中 | 没有事务begin,commit的过程,只有事务执行 |
| 读写记录集 | 事务中涉及到的所有读写记录集,只有在事务提交时,才能明确范围 | 事务执行前,就能确定读写记录集 |
| 根据读的业务逻辑判断(例如:减库存时,是否可减) | 此判断发生在业务逻辑代码中 | 此判断放置在存储过程中 |
| 分布式事务支持 | 依赖xa,或类似2pc的协议,来协调分布式事务中每个分支的提交 | 由于,执行前确定了读写记录集,分支的数量也就确定了,所以事务中的分支,可以仅仅等待其他分支的消息,就能决定最终的事务状态 |
由上述描述对比,我们现在可以给出calvin的事务模型定义。
calvin 的事务模型: 有别于传统数据库的事务模型,calvin采用的类似存储过程的确定性事务,
确定性指的是在事务未执行时,就可以明确的确定事务边界,读写操作的记录集。
阅读过前面的文章后,我相信读者一定有个疑问,这和传统事务操作比起来,这样做的好处是什么?其实,当数据库能够明确知道事务的边界,事务操作的记录集的时候,完全通过数据库的排队处理,可以避免事务死锁,事务异常终止,网络延时等造成的事务延时增加,吞吐下降的情况。同时,由于锁竞争的避免,可以让数据库拥有水平扩容的能力,并在扩容的同时,达到一个接近线性的性能提升。
接下来,让我们走进calvin的实现。首先,我们先上一张calvin的架构图。
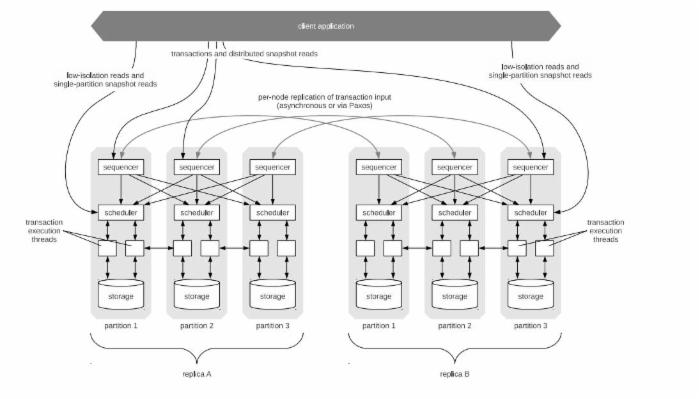
从上图,我们可以一览calvin的整体架构。N个集群,都是active,一个集群是一个replica。每个replica里面的每个节点,都有三层:sequencer、scheduler、storage。例如图中,replica B中 partition 1和replica A中的partition 1是互为备份的。Calvin是通过在sequencer上建立同步机制,来进行互备过程,scheduler通过,执行相同的事务序列,以达到storage层的数据状态的一致。
客户端会将写入请求,发送至 sequencer ,sequencer会收集发至本机的事务请求,每隔10ms(每隔10ms生成一个epoch id)将事务进行batch并为每一个batch事务进行编号(编号原则:sequencer id + epoch id,这样可以保证事务编号唯一,且可以比较大小), calvin采用paxos同步或异步来复制batch后的事务,并在同步完成之后,递交给scheduler。
calvin的原始论文,在此处出现了一个断档。论文并没有描述scheduler如何保证按照sequencer决定的事务编号的排队顺序进行执行,这个顺序如果得不到保证,则在两个副本中,内容就可能产生不一致的现象。我们为了能够在博文里建立完整的calvin执行过程,在这里补充一个脑补的执行方式,用来保证scheduler的执行一致性。具体如下:
我们假定每个scheduler明确的知道当前replica有几个sequencer节点。
sequencer在每个epoch的行为遵守如下约定:
将当前epoch内的事务请求,发送至与这些事务请求相关的scheduler,同时向剩余的scheduler发送epoch id,明确的通知这些节点当前epoch不需要这些节点处理(如果当前epoch无事务请求,则只做后一步)
scheduler在每个epoch的行为遵守如下约定:
每个周期,必须收到所有的sequencer发来的消息,才对当前epoch进行处理.
遵守以上条件,就可以保证一致了,我们脑补的这种执行方式,从原理上讲也是符合calvin所提的确定性。看起来这样的方式会降低当前replica的可用性,不过我理解可用性可以由当前集群的replica保证。
当 Scheduler 接收sequencer递交过来的batch事务,并单线程的对所有sequencer递交过来的事务,使用事务编号进行排序(sequence id + epoch id)。Scheduler上还存在一个lock管理器,用以管理本scheduler对应的storage所持有的记录的锁。 calvin严格保证当一个事务和另一个事务,有冲突的时候,事务编号靠前的先获取锁。 当一个事务拿到全部锁(事务内的所有分支,均在自己的分片上拿到了响应的本地资源的锁)后,则递交给工作线程进行事务执行.此处的锁机制,由于是确定性事务和这个条件的存在,直接解决了死锁循环等待条件,即在calvin中,不会有分布式死锁的存在。
事务分支递交到工作线程后,在工作线程中执行步骤:
(1)分析当前scheduler的本地读写,及当前事务会发生在其他数据分片的集合。
(2)执行本地读。
(3)等待远程读(只去等那些将写的节点的消息,纯读的节点不管);
(4)汇总读结果;
(5)在 storage 执行事务,本地写(不管远程写,因为远程写会被别的节点认为是本地写,从而执行)。在第5阶段,各节点不需要交互。
当第(4)执行过后,每一个写分支都在自己本地建立起来了全局的写事务状态视图。论文中,虽然没有明确的说(4)结束后,如果有逻辑通不过的情况,例如,库存已为0后,是否终止abort.根据论文前后内容的推敲,这里应该会进行这个判断,当一个写分支逻辑失败后,所有的其他分支,根据失败信息决定(5)中的行为。
说到这里,可能有的同学又不理解了,没关系,配上我们脑补的执行过程。如下:
//例如这是下订单的存储过程 if(inventory num > 0){ inventory num = inventory num – 1; }else{ throw exception; } insert new order;
//订单partition上对应的scheduler可能的执行过程 try{ try{ if(inventory num > 0){ inventory num = inventory num – 1; //忽略 }else{ //忽略 throw exception; //忽略 } insert new order; //执行,但不刷入storage send yes message to inventory partition }catch(exception e){ Send no message to inventory partition throw e; } wait inventory message; //如果等到错误消息,或超时,则抛出异常,终止事务 flushTo Storage ; }catch(excepton e){ Abort Transaction; }
//库存partition上对应的scheduler可能的执行过程 try{ try{ if(inventory num > 0){ inventory num = inventory num – 1; //执行,但不刷入storage }else{ //执行 throw exception; //执行 } insert new order; //忽略 send yes message to order partition }catch(exception e){ Send no message to order partition throw e; } wait order message; //如果等到错误消息,或超时,则抛出异常,终止事务 flushTo Storage ; }catch(excepton e){ Abort Transaction; }
最终,事务的写入要刷入 Storage .Storage是一个存储抽象层,下层才是真正的存储,可能是mysql,磁盘文件,或者是内存。
上面,我们从一个事务执行的角度,从这个事务在calvin 各个组件的传播,依次的介绍了各个组件。可能一部分读者已经看到了一个疑问,先做一个范围读取,然后根据这个结果再做一个写入,在上述的流程中,是很难确定读写记录集的。那这种类似的事务操作,calvin是如何支持的?
从calvin的事务处理流程上,确实不支持如此的操作。它换了另外一种思路解决这个问题。它提供了一种机制,来改变客户提交的事务代码的实现,Optimistic Lock Location Prediction (OLLP)。基本做法是,在真正的事务,被添加sequece,并被执行之前,就使用读请求,来探测这次事务所有的读写记录集,并在执行之前,再次检查,如果读写集变化了,则这个过程要重新执行。
另外,还记得前面描述过的 calvin 严格保证当一个事务和另一个事务,有记录冲突的时候,事务编号靠前的先获取锁 的条件 , 在事务冲突的情况下,在scheduler的工作线程中执行的事务,有可能由于磁盘延时(冷数据load到内存的时间,这个在传统数据库中,可以参考索引b+树的加载,当加载树的一个在磁盘上的节点时)造成处理的停止。calvin会通过在sequencer中采用一个 磁盘延时预测 的数据集预热过程来减轻这种磁盘延时造成的scheduler中的处理停止。当sequecer发出预热storage的数据请求后,再制造一个人为的延时在这个延时过后,在分配事务编号,并提交给scheduler,读者应该注意到,在等待延时的时候,这个事务是没有获取锁的,其他的可能与其冲突的事务是可以继续下放到scheduler执行的,那这种延时影响的仅仅是本次事务的延时,而从数据库本身而言,并不影响scheduler的效率,但是当事务请求并发量固定时,吞吐会随着这个延时增加而降低,所以当这个延时稍微大于预热的开销时间时,整体效率和吞吐达到最高。
论文,还介绍了一些calvin处理 checkpoint 的细节 ,当数据库重启恢复过程中,不可能将sequecer中,记录的redo log,从头进行回放,所以要记录checkpoint点。
制作checkpoint点的时候,需要对storage所管理的存储,进行一个快照读。这里的快照读,提供了3种方式:
- 悲观的方式,当前这个分片,干脆不让写了。这有可能造成,这个分片落后其他分片非常多。甚至是,当这个分片进行catch up的时候,根本就无法catch up成功。(这个原因应该是replica删掉了废弃的日志)
- Zig zag算法,这个基本上,就是一个只有两个版本的mvcc。
- 底层存储本身就是一个多版本的数据存储。
以上,我们介绍了calvin的整体架构,和事务处理的过程,并且脑补了一些论文中没有详述的断档。原始论文中,还有部分关于测试的,性能的部分,我们就不在此罗列了。
正文到此结束
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

