分库后如何处理分页?
在数据量过大以后,通常都会进行分库操作,把一张表拆分到不同数据库中
例如 tb1 表被拆分到3个库中,分库1、分库2、分库3
现在想执行分页操作
SELECT c1 FROM tb1 ORDER BY c1 LIMIT 4, 2
如何处理呢?查了一些数据库中间件的资料,有一个通用的思路:
到每个分库中取出从0开始、到目标结果集的最后一条记录,汇总到一起,进行排序,然后再取出目标位置的记录集合
例如上面的sql是根据 c1 排序,要取得第5、6两条记录
那么就会对每个分库的 tb1 表执行下面的语句

假设结果分别为
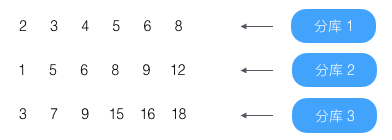
开始按顺序查找
第0条(结果为1)没到第4条,略过
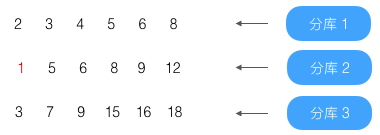
第1条(结果为2)没到第4条,略过
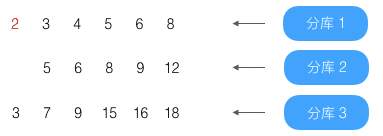
第2条(结果为3)没到第4条,略过
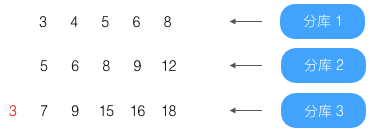
第3条(结果为3)没到第4条,略过
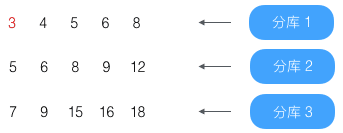
第4条(结果为4)已到第4条,放入结果集

第5条(结果为5)已到第4条,放入结果集
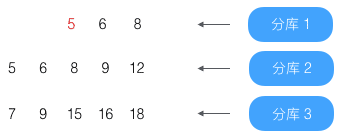
这时结果集合为:4、5,已经达到目标条数2,结束查找
这个思路很简介,实现起来也不复杂,缺点就是当起始位置很大时,所有分库的查询数据将非常大
例如
select c1 from tb1 order by c1 limit 100000000, 2
所有分库都要查询 100000002 条数据,然后再进行汇总排序操作,这个性能很难接受
这个情况也没有特别好的解决办法,但如果各个分库数据分布大致一样,那么可以减少分库大部分结果集
例如sql
select c1 from tb1 order by c1 limit 9999999, 4
现在有3个分库,因为数据分布大致一样,那么可以等分查询
9999999 / 3 = 3333333
各分库执行

假设结果为
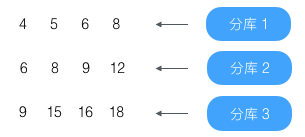
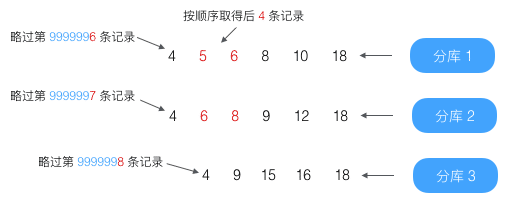
找出查询结果中最小和最大值,4、18
以最小值和最大值为界再查询各库,结果为:
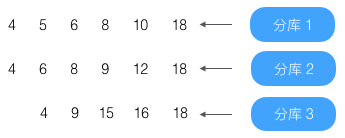
查出返回结果中第一条的offset,例如

那么第 3333331 条相当于第 9999996(3333331 + 3333332 + 3333333)条记录,从它开始按顺序查找
略过前3条,取得后面的4条记录,查询完成
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

