码说MapReduce
MapReduce框架作为Hadoop发展初期的核心计算框架,为大数据处理技术飞速演进提供了基石。在Hadoop生态圈中,MapReduce框架由于其成熟稳定的性能,仍然是离线批处理技术的主力。以我们的北京移动大数据集群为例,Hive、SparkSql是支撑探索性数据查询的主要工具,其简单易懂的SQL语句查询,可以使具备基础数据库管理能力的人员轻松上手,完美地支撑了实时数据查询需求。
在我最初使用Java写MapReduce程序之前,总有一个疑问:既然可以用SQL这么通俗易懂的语句直接操作数据,而且不需要过多了解MapReduce执行过程,为什么还要费力地用Java垒代码,去了解MapReduce的底层执行过程。什么样的应用场景需要我们来开发MapReduce呢?
首先,Sql非常适用于处理结构化数据,对于非结构化数据以及需要特殊函数处理的数据比如文本数据,Sql则会力不从心。举一个小例子,从海量文本数据中提取各种字符编码并翻译为中文,过程中还涉及自动识别是utf-8还是ANSI亦或是其他编码格式,这个需求用MapReduce程序实现起来更为合理;另外,在处理业务逻辑较为复杂的任务时,使用Sql很难实现,其执行效率方面也很难满足业务需求。举例来说,我们需要将业务日志中的域名识别为相应的互联网应用,现实操作中需要分多种情况使用多重判断进行规则匹配,并剔除钓鱼网站和fake url,使用SQL很难实现业务逻辑。再例如,使用Sql进行多表join并叠加复杂的数学运算时,其效率也很难满足业务需求。
在我们的机器学习工具开发过程中,为了使用原有数据建立特征向量,我们需要对原有表结构进行转化,需要迭代原始数据生成具有较多特征值的特征向量。原始数据量为13亿条,共13.2GB,我们尝试使用Hive SQL进行实现,经过测试,任务执行时间过长无法满足需求。而使用MapReduce编写两个Job实现业务逻辑,同时使用哈希算法优化字符串查询效率,最终处理时长为15分钟。应对这些复杂情况,使用MapReduce编程可以使我们获得更多对程序实现的控制和方法选择,通过底层算法优化实现效率提升。
基于不同的业务场景,结合不同工具特点,我们采用SQL脚本和MapReduce开发程序结合的策略,使日常数据处理任务在效率上得到了很好地满足。在我们平台中,MapReduce程序承担了如关键字提取、应用匹配和标签规则运算等近30%的日常数据处理任务。
总之,我们在实际应用中依据灵活性和效率来选择是否自己开发程序。
概览MapReduce
认识MapReduce先从架构入手,在此我们一图以蔽之:
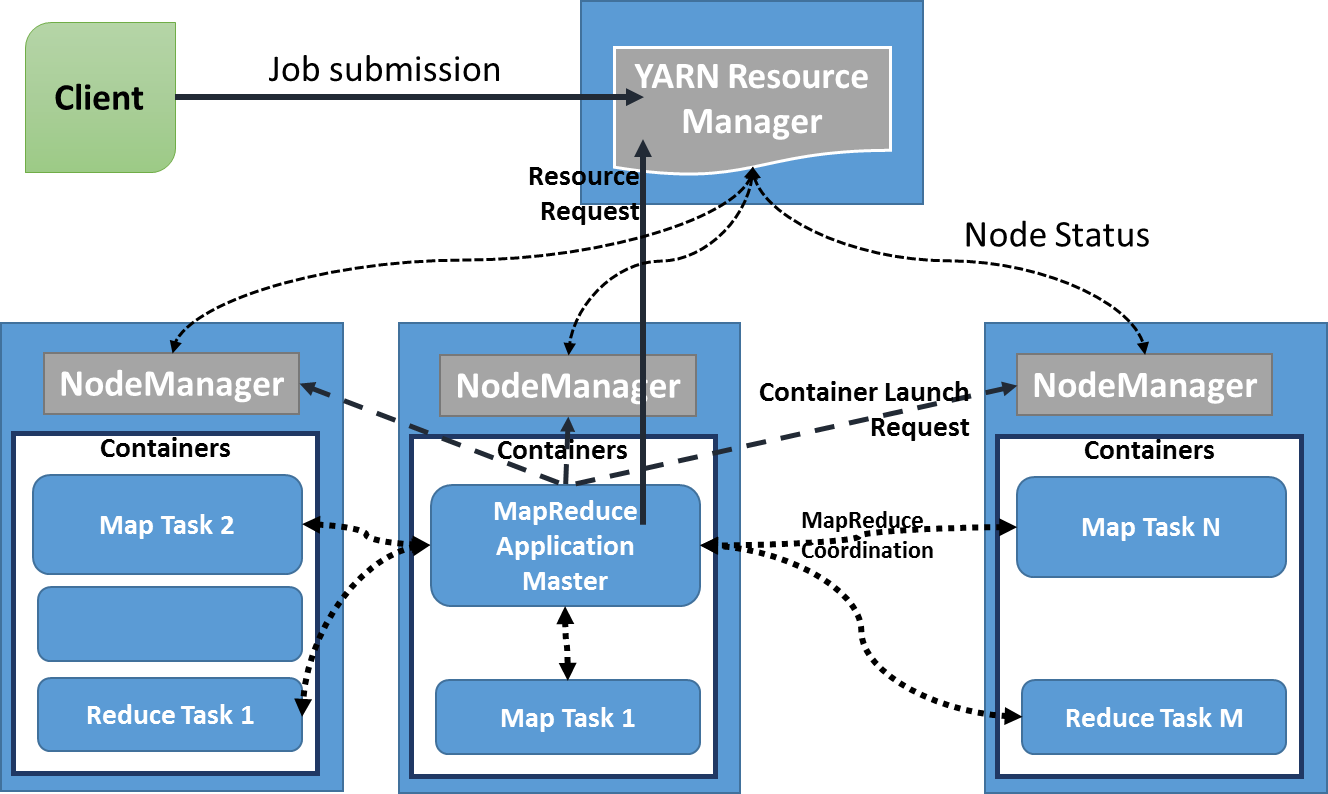 图 1
图 1
现在广泛使用的MapReduce v2基于YARN架构,其角色包括Resource Manager(RM)、NodeManager(NM)、Application Master(AM)。RM由Master主机承担,主要负责任务调度和资源调配,NM和AM由各工作节点Slave承担,负责任务的处理和资源读写,其计算单位抽象为container。MapReduce的计算流程可以抽象为Splitting、Mapping、Shuffling、Reducing阶段,其中shuffling包括了Grouping、Sorting、Partitioning过程。以WordCount为例,如下图:
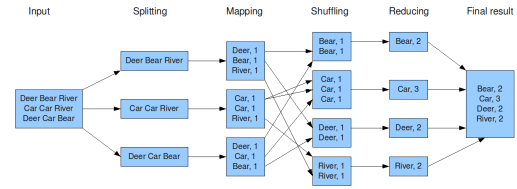 图 2
图 2
在掌握了MapReduce架构和原理的基础上,从代码的角度认识MapReduce才是程序员的正确打开方式。
开发MapReduce
MapReduce程序中,Map和Reduce逻辑功能分别通过扩展Mapper类和Reducer类实现。具体在实现过程中,我们在主类中将Mapper和Reducer类扩展并作为内部类调用,最后通过main函数定义输入输出以及Job配置,从而作为程序主入口。
Map实现
Mapper类扩展需要实现map方法,如下:
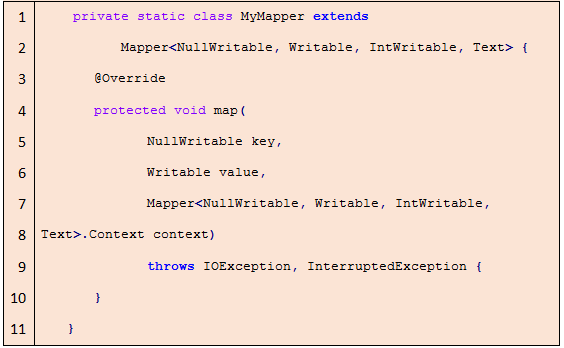
根据需求可以扩展setup、cleanup和自定义方法等,扩展Mapper类时需要声明键值对类型,如 Mapper< NullWritable,Writable,IntWritable,Text >,依次分别为输入输出< key,value >类型,其中< NullWritable,Writable >是orc文件格式输入< key,value >类型。
需要强调的是,MapReduce中所有输入输出字段类型都必须实现Writable或者WritableComparable类型,这是因为MapReduce中磁盘读写和节点数据传输过程涉及到数据的序列化和反序列化,需要通过这两类来实现。经常用到的IntWritable、LongWritable、Text等都是实现自WritableComparable类,如果需要,我们也可以扩展这两类实现自定义数据类型。例如,在通过MapReduce实现两表和多表Join的过程中,我通过实现WritableComparable类自定义Map输出的key字段类型,来实现对于Grouping和Sorting阶段不同比较字段的控制。
setup方法在类调用起始阶段运行,可以实现初始阶段对于参数读取和变量赋值的操作。在app应用识别案例中,我们在setup阶段实现对于平台DPI文件的读取操作,以在之后的map阶段实现MapJoin操作,代码如下:

其中DPIMap是需要在主类中定义的HashMap变量,在map阶段将使用HashMap实现快速查找。
map方法是实现Mapper类的核心方法,map阶段主要逻辑都需要在map方法中实现。map方法参数定义包括输入< key,value >和上下文对象context声明。Context对象负责在MapReduce执行过程中平台配置和Job配置的传递。Job执行过程中,写入的业务逻辑会对每一条数据进行操作,并将中间结果< key,value >值通过context对象写入后台进行之后的shuffle和reduce操作。
例如我需要将业务数据中的host字段与DPI数据的host字段进行等值连接,统计出使用app的次数。我们可以在map方法中实现如下:

在此默认输入数据为ORC格式,代码中涉及对ORC文件读取方法。
Reduce实现
同Mapper类类似,扩展Reducer类需要实现reduce方法。继续以统计app次数为例,Reducer类扩展实现为:

其中reduce方法实现的逻辑为对依据key值group之后的value值集合进行加和,并写入HDFS。
在reduce方法中,接收到的value集合通过Iterable接口实现,我们可以通过iterator对象提供的API实现对value值集合的遍历。Reduce的输出我们最终写为ORC格式。
程序主入口main()方法
通过在主类中定义main()方法作为程序的入口,我们需要在此完成对程序参数传递、输入输出配置和HDFS平台配置声明等工作,以app应用识别为例,代码如下:

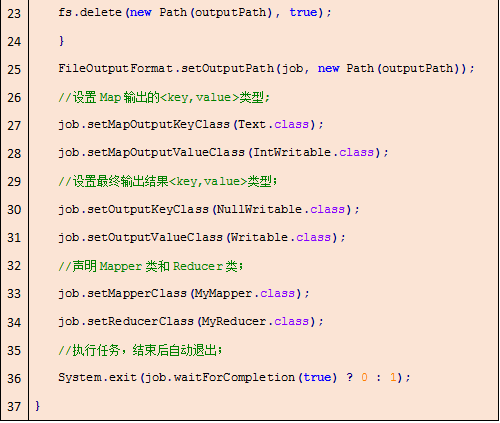
此例main()方法主要完成了对输入输出类型和路径的配置、任务执行队列和资源配置的定义。main()方法主要完成对程序接口的定义和资源调配,以上代码展示了一个最基本main()方法的定义。如果任务需要,我们还可以完成诸如自定义Group Comparator、Sort Comparator、Partitoner等对象的定义,并在main()方法中声明,作为MapReduce程序的comparator。
在我们平台的日常任务中,我们放弃使用占用空间较大的Text和Sequence文件格式,完全使用ORC文件格式作为数据存储格式。这样可以实现自定义MapReduce程序与Hive平台的无缝结合,更重要的是,可以为平台节省十倍的存储空间。
ORC存储方法
ORC File是Optimized Row Columnar (ORC) file的简称,它基于RCFile格式进行了优化。ORC文件格式的设计初衷是为了提高Hive数据读写以及数据处理能力,由于其实现了一定的数据压缩,可以占用更小的数据存储。
我们使用ORC格式作为MapReduce和Hive工具的统一存储格式,可以节省平台大量的存储空间,同时也实现了MapReduce程序与Hive的更好结合。
经过我们平台日常任务的实测积累,ORC文件格式可以为Hive提供稳定快速的数据读写,并且与Text文件存储相比,可以节省十倍的存储空间,可以大幅提升平台数据存储和处理能力。对于MapReduce程序读写ORC文件,无法像未压缩的Text文件一样直接读写,还需要做关于表数据结构声明等工作。
读ORC文件
仍然以app应用识别为例,主类中需要定义变量SCHEMA,声明读入表结构:

读取ORC文件格式的代码如下:
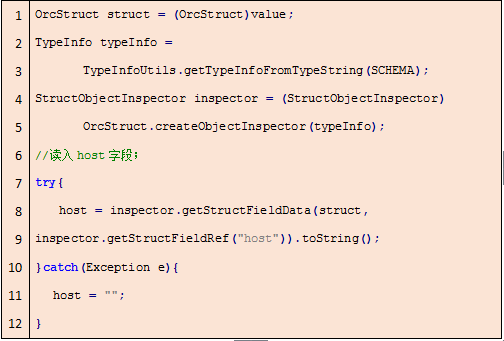
首先,需要将读入的value值强制类型转换为OrcStruct,然后根据表结构实例化StructObjectInspector对象为inspector,最后使用StructObjectInspector类提供的API对字段进行读取。
写ORC文件
与读入过程相对应,写ORC文件代码如下:

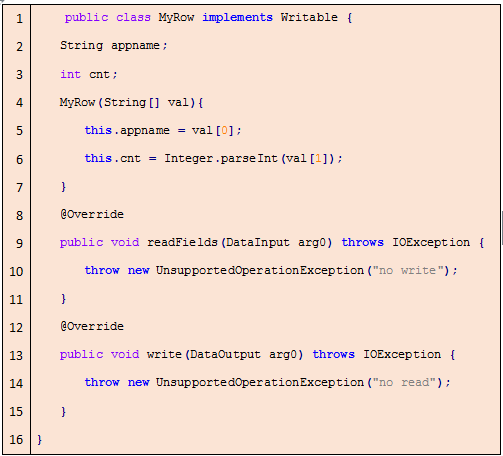
我们需要根据自定义的数据类型MyRow类实例化StructObjectInspector为inspector,然后使用OrcSerde对象将最终计算结果进行序列化并写入HDFS。其中MyRow类是通过扩展Writable类,对输出数据类型进行了定义,在类中完成了对输出表结构字段的定义和赋值,代码如下:
在上面的章节中,我们介绍了MapReduce开发在北京移动大数据平台上的应用背景和部分应用案例。尽管MapReduce由于处理机制中大量的磁盘读写带来了数据处理效率的瓶颈,但在日常离线数据处理任务中由于其成熟稳定的性能,MapReduce仍然扮演着十分重要的角色。
随着技术的不断发展,诸如Spark等更加快速的计算引擎也将逐步取代MapReduce的地位,我们也在一步步尝试替换和优化我们的应用场景,也欢迎大家多提意见和建议,谢谢!
作者简介:孙昊,毕业于Auburn Univeristy,获得EE工程硕士学位,专攻信息论与信息安全,现就职于北京移动网运中心。熟悉信息论与数理统计,善用Java、Scala语言编程,熟悉C、C++、Python语言以及H5、Javascript等网络编程语言,精通MapReduce编程框架,熟悉Storm、Spark Streaming大数据实时处理技术。2014年底加入北京移动eBDA大数据分析团队,担任团队大数据软件开发工程师,参与完成了搜索关键字产品、互联网流量视图、应用匹配产品、用户标签体系产品等大数据项目。eBDA大数据分析团队是一支扎根于北京移动网运中心,致力于提升数据价值、改善用户体验,取之于民用之于民的有理想有能力的团队。

正文到此结束
- 本文标签: 大数据 域名 软件 Word java struct HDFS 数据 空间 value http mapper ip 集群 时间 key 主机 ORM 占用空间 网站 UI 需求 实例 统计 JavaScript node cat 配置 代码 遍历 src scala tab 产品 map SDN 程序员 schema Job Hadoop 互联网 sql API App 开发 任务调度 测试 数据库 安全 管理 CTO 参数 python 翻译 apr
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

