光音网络的存储容器化方案探索
【编者的话】本文是 @Container容器技术大会·北京站 上 光音网络 带来的分享 -- 光音网络的存储容器化方案探索 ,实际的业务不仅需要无状态的容器,更需要有状态的数据。如何把无状态特性的容器引入有状态的数据存储呢?本文的主题是存储容器化方案的探索,即如果使用Docker的话,数据存储会变成什么样子?
对于传统的项目,要对Docker进行改造的话,就会涉及存储方面的问题。 首先需要解决的就是容器中有状态的文件数据 。程序要存储一些文件,如附件、图片等,一般存放到文件系统里面,而Docker是无状态的,所以不能把它存到Docker内部。一种方案是依托共享的文件系统,把有状态的内容以外挂的形式解决;另一种方案就是改造代码,把它存到数据库里面。
下面我们分别从硬件、操作系统、软件部署、调优、扩容、负载、灾备、基准测试等角度去分析,我们都遇到了什么样的问题,又是如何通过容器化的改造来解决的。
一般都会遇到这样的困境,每一次采购设备的批次不一样,如果有新的型号我们就采购新的型号,但是这样就会带来新的问题:会有一些存储设备的型号以及配置不一样。

上图是我们生产线上投入使用的服务器配置示例。比如说我们有3U的刀片,配有1块SSD和4块普通盘;6U的话会有1块SSD和1块普通盘;4U的硬盘会比较多一些,专门做存储用的。这样问题就来了,我们如何综合利用这些硬盘,使资源利用最大化?我们不可能只跑Container这种无状态的业务,还要考虑CPU和内存以及存储的合理分配。容器化以后,这些资源可以很方便地转移,切换,而达到充分利用不同配置的服务器。
我们操作系统也是多样的。目前主要的操作系统是CoreOS,因为CoreOS更加适合跑容器,省去了我们很多的维护成本。还有一部分机器在使用Debian和CentOS,因为某些业务的特殊需求和设备驱动的问题。容器化以后,所有的部署方法不会因为操作系统的差异而改变,即可以自由地在这些操作系统之间转移。

上图是我们线上使用的数据库,还有一些数据文件系统。由于微服务的推动,服务的数据和数据库的数量也野蛮地增长,虽然在某种程度上加速了业务的迭代,但是也带来了数据库管理成本的急剧上升。每个项目都会有一个库,这样的话,库会越来越多,而且因为业务类型不一样,对数据库种类的需求也就多样化起来,所以说数据库的种类也很多。我们最终使用容器化改造来解决这些问题。
我们对有状态的存储分为三种分类:
- 分布式文件系统
- 数据库系统
- 无状态的本地系统。例如:Kafka,它是存硬盘上的,那我们Volume Mount到本地硬盘就行了。为什么无状态呢?因为我们有副本集,我挂掉一个的话数据是不会丢的,随时可以迁移走。
根据这三种分类,我们分别从部署、扩容、负载、灾备、基准测试方面,探讨一下容器化之后给我们带来了哪些变化。
先说一下部署,在常规的部署中,我们会遇到以下的困惑:
- 下载慢,安装麻烦。如果做缓存还好一些,没做缓存的话本身就下载会比较慢,导致每个机器安装部署时间会比较长。
- 安装过程比较复杂,因为有些库用到一些依赖,这个根据不同的机器情况会略有不同。
- 版本控制问题。每个业务线要求的版本不一样,会导致每种数据库要维护多个版本。
- 数据库各类不一样。有些数据库你接触过就会装,没接触过可能就不会装了或者可能装不好。
- 操作系统不同,因为每个操作系统安装方法也不一样。
- 同一宿主机只能运行一个版本的数据库。
- 数据库的调优方案很难做到统一。
Docker化以后这些就很简单了。因为数据库特别多,以MongoDB为例,做为切入点,阐述一下我们的用法。
我们以MongoDB为例,直接拉取需要的镜像即可。一般情况会做一个私有仓库,所以说镜像的拉取会非常快,安装的话几乎就是几秒的样子,下载完就等于安装好了,所以安装这些问题都不是问题了。
版本号就不用说了,因为镜像也有版本,打tag就行了。再一个是操作系统,Docker已经做好各种操作系统的适配了,所以操作系统的差异化就没了,对于环境依赖自然就解决了,由于Docker本身的隔离性,在同一个机器跑不同版本也没问题。
在调优的时候,我们会对不同的数据库做不同的优化,这个可以写在Docker的Dockerfile里或者镜像里面完成。对外部来说,不管是什么数据库,操作方式都是一样的了。运行起来后,所有的数据库镜像都有了统一的优化方案,于是操作方式就简化成了如何操作容器。
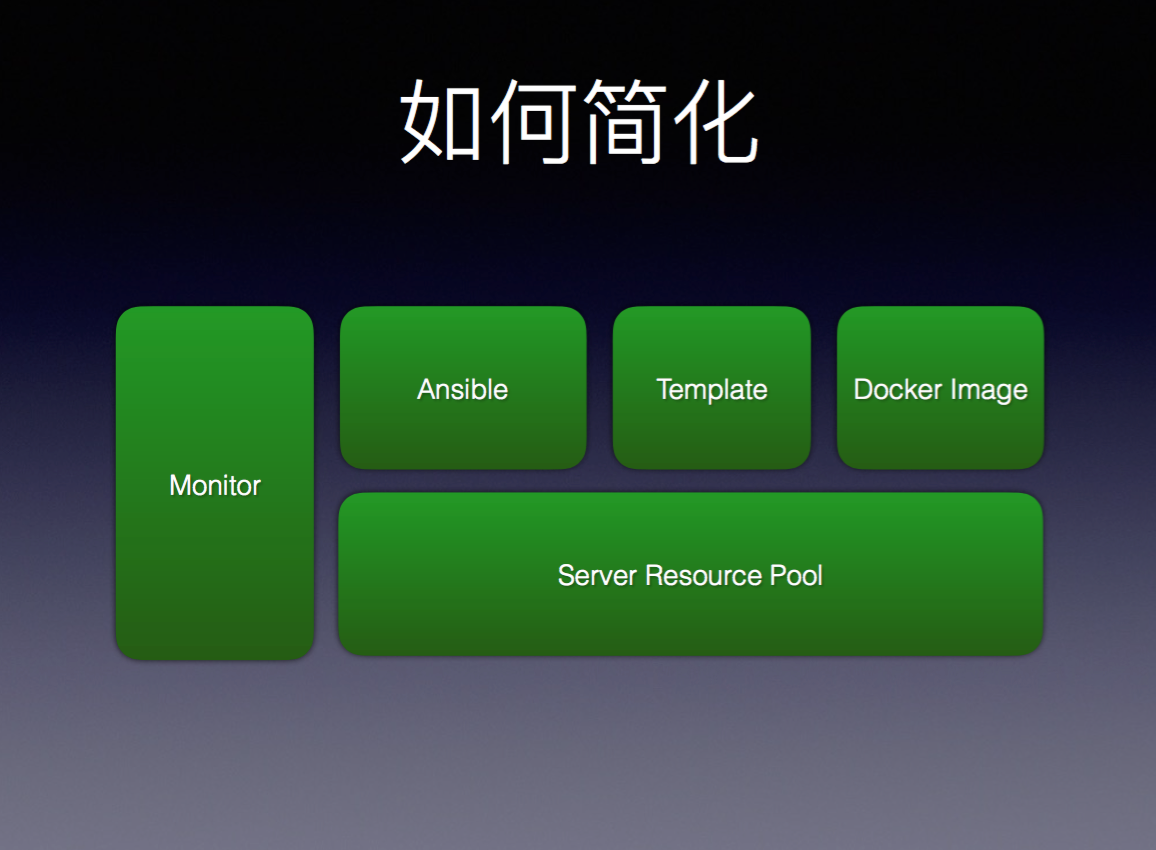
那我们如何来简化这些操作呢?部署工具我们选的是Ansible,选择Ansible是因为它不用安装Agent,加机器会非常容易,只需要知道节点的Key,就能把那个机器加到集群里。这样,利用Ansible就可以远程部署任意容器了。
服务器统一资源管理池里记录了有多少服务器,是什么配置。对不同的数据库我们会有不同的模板,比如你可以选择MongoDB, MySql以及Hadoop的模板。配套会加上Monitor,监控整个池子所有资源是否工作正常。这些模块在一起,就形成了完整的一套系统。
我们还是以MongoDB为例,这个是个Template脚本,我们使用systemd来做为启动守护进程,大家可以看一下只有一个"mongo"是不一样的,其他模板都是一样的,我们启动、删除、重启方法在外部表现是一样的。
在实际的应用中,平台就要做到可视化,通过可视化,不仅可以简化操作难度,而且最终执行的结果也是可以预知的。对于执行者来说,只要会填数,那么最终部署的数据库以及配置都是一模一样的,也就是说不同的运维人员或者不同的开发者去操作,得到的结果都是一样的。
我们举一个例子,MongoDB的副本集一般部署3个,再加上2个Arbiter,然后根据业务量来决定是否做Shard。另外,还要看业务上有多少Client,每秒大概有多少的操作量,这个关系到Proxy的连接处理能力,知道这些指标后,我们会根据这些指标来决定分什么样的机器。另外还有一个很重要的就是Service Domain,也就是内部域名,因为硬件本身的损坏率,机器的硬件以及操作系统也随时有可能挂掉,那么对于域名来说,我们随时可以切换而不用改动线上的业务代码,这样的话就简化了整个部署的操作。
升级也是经常遇到的情况。我们用的是CoreOS操作系统,CoreOS帮助我们做了很多容器方面的适配并提供最新的系统内核和Docker版本。线上有500多个节点在使用CoreOS,用起来还算挺好的,版本也会经常去更新,比如1.9对网络上有一些新的特性,我们就可以轻松去升级测试了,对我们来说,更新成本变低了。
如果要用到数据库的新特性,就肯定要做升级的。在升级的实际操作过程中会遇到一系列问题,比如说数据库是否可以试升级,即试着把它拷贝过来然后去升级,然后看一下业务是不是正常,Docker化后,这种操作就变得简单起来。
还有,如果升级失败怎么进行回滚,环境依赖以及不同版本的数据库共存的问题。由于这是Docker本身的特性,因为它已经做了隔离,在不同的Docker实例之间是隔离的。还有一些复杂的升级过程我们可以脚本化,就升级来说也是非常容易的。
举个例子,比如说MongoDB 3.0升3.2,直接改版本号升级就可以了。当然实际操作中会有一些问题,比如MongoDB 3.0到3.2,引擎还是一样的话,中间不会出任何问题的,MongoDB自己解决了一些兼容以及升级的问题。如果是2.6到3.0,由于它的引擎发生了变化,文件格式都不一样,一个是基于MMAP,一个是基于WiredTiger的,但是这种怎么升级呢?我们用的三个副本集都是一模一样的,我把一个宕掉,然后再把新版本的加进去,它自己会同步,因为通信协议是一样的,剩下的操作,MongoDB可以自动去完成。所以这种版本的升级也是没问题的。还有一个要注意的是业务方的数据库驱动,是否兼容新版本,把这个控制好就可以。
还有一种升级方案是数据的重新导入,这个适用范围就广泛了。数据库导出来然后再导进去。如果数据库量大的话,可能会比较慢的。如果想把这个特性自动化处理,可以做一个升级脚本放到Docker里面,这样的话,就成为了一种规范,不管谁去使用,升级都不会出现任何问题。这样就不会因为人员水平的参差,而导致整个操作部署水平的差异。
数据库的水平扩展。一般情况下,并发太大,扛不住了,那我们就会多加几个节点来提高吞吐能力,那数据库能不能做到呢?现在基本上大部分数据库都支持分布式的,我们也可以通过增加节点的形式来提高它的吞吐能力。Docker化后,它对我们的操作带来不少方便。
对于MongoDB来说,前面有一个Proxy,后面有一些节点,当业务量扩展的时候我们会横向加一些节点,这个对Docker来说本来就是它的专长,直接可以加就行了。例如,我们通过监控系统发现一些性能瓶颈,这样就可以通过增加节点的方式来增加吞吐能力。但是这里面的水平扩展也需要根据业务的情况来进行调整。利用Key的哈希方法,数据分配得就非常均匀,每个数据块都会分到不同的机器上面,这样整体的抗压能力会强一些,但是这个对于Range查询是非常不友好的。所以要根据业务的特点去选择不同的库和不同的Shard的方式,水平扩展并不是万能的,要结合业务的实际需求来改进。

我们看一下实际的Shard操作。上图是MongoDB Shard的一个Example文件,跟上一个MongoDB的区别不大,就是多了一些Shard的相应参数。像这种数据库支持的也比较多,比如说Elasticsearch直接加节点就行了,Hadoop 也可以动态去加。但是加节点的时候,它会自动的均衡数据,这个时候可能对你业务的性能会产生一些影响。这样的方法同样适用于Kafka,NSQ。Redis横向扩展可以采用Codis的方案或者Redis Cluster的方案,通过Redis集群的方式,我们可以通过分片的方式,把内存分配到不同的机器上面去,来达到扩大整体数据吞吐的能力。
下面讲一下容灾和备份这一块。因为数据敏感性及安全性,所以说容灾和备份非常重要。那么怎么实现呢?因为我们想充分利用每台机器的资源,并把它的资源用到极致,所以我们把一些无状态的计算业务和有状态的数据混着排。根据需要,我们会限制CPU或者内存,来减少业务之间的干扰。
在实际的运维中,会经常遇到硬盘故障。我们现在的操作方式就比较轻松了,一般操作是把机器关掉,把刀片抽出来然后直接更换新硬盘。整个过程,因为有了调度系统的参与,你不用关心业务的具体状态,因为它在关机之前会通知调度系统这个机器要关了,前端有一个负载,会把量切走,就不用它了。但是对于数据库来说它的有状态的,那你切掉怎么办,这种情况下我们高可用的副本集就发挥作用了。
举个例子,比如一个 MongoDB机器坏了,我们可以把机器关掉或者记录下来,然后从资源池里面找一个能用的。由于MongoDB是硬盘IO密集型的,一般情况下是不把两个MongoDB装在同一台机器上 ,我们需要找到一台没有MongoDB的设备,把它运行起来,而且尽量分配到SSD上面去,这样性能才会得到最大的发挥。然后我们把坏的节点删除,然后把新启动的这个节点加进去,这时,MongoDB会自动把数据同步过来。这个同步速度非常快,比直接拷文件都要快得多。整个过程中,线上业务没有中断,因此它能做到业务的无缝迁移,对业务是无感知的,这一点体验特别好,我们用起来也很爽。像这种支持的数据库也是比较多的。
下面讲一下备份,刚才提到副本集的方式,还有就是冗余,比如说文件系统可以写两份。 如Ceph和GlusterFS,它们会有副本集的配置。我们对于文件系统,保存了三个副本来提高它的安全备份级别。还有一些是延时同步,MongoDB在同步时,它是通过读操作日志的形式去同步数据。这就避免什么情况呢?比如说有一个DBA或者开发者,不小心把库Drop掉了,那副本集要做同步,瞬间也会被同步完成。这个时候延时同步就起到了缓冲作用,避免此类灾难的发生。对于一些实时的业务,昨天的数据对于今天来说,可能就没有什么太大意义了,所以说这种副本集方案是非常好的备份解决方案。需要说明的是,延时同步并不会增加查询的负载,它只会做数据的同步。
大家可以根据自己的业务场景进行选型,这里给大家提供一个思路,看有没有其它的最佳实践。
还有一个很重要的东西,就是备份策略和监控要配套执行,比如平台创建好一个数据库,备份和监控一定要自动地加进来。
Docker化后,基准测试也就更加便利了。对于数据库的测试,我们以前就是凭感觉,没有一套标准去执行。使用了Docker后,我们做一个测试的脚本,用Docker封装起来,基于Docker的特性,我们可以利用闲时的服务器资源来做一些Benchmark。一个客户端的测试量不够的话,我可以启10个或100个,这样并发打过来的话,可以模拟高并发的业务量对整个数据库冲击。虽然测试的数据库版本不一样,但是我们客户端是一样的,所以我们可以充分的利用这个测试镜像,构建一次可以终生使用。
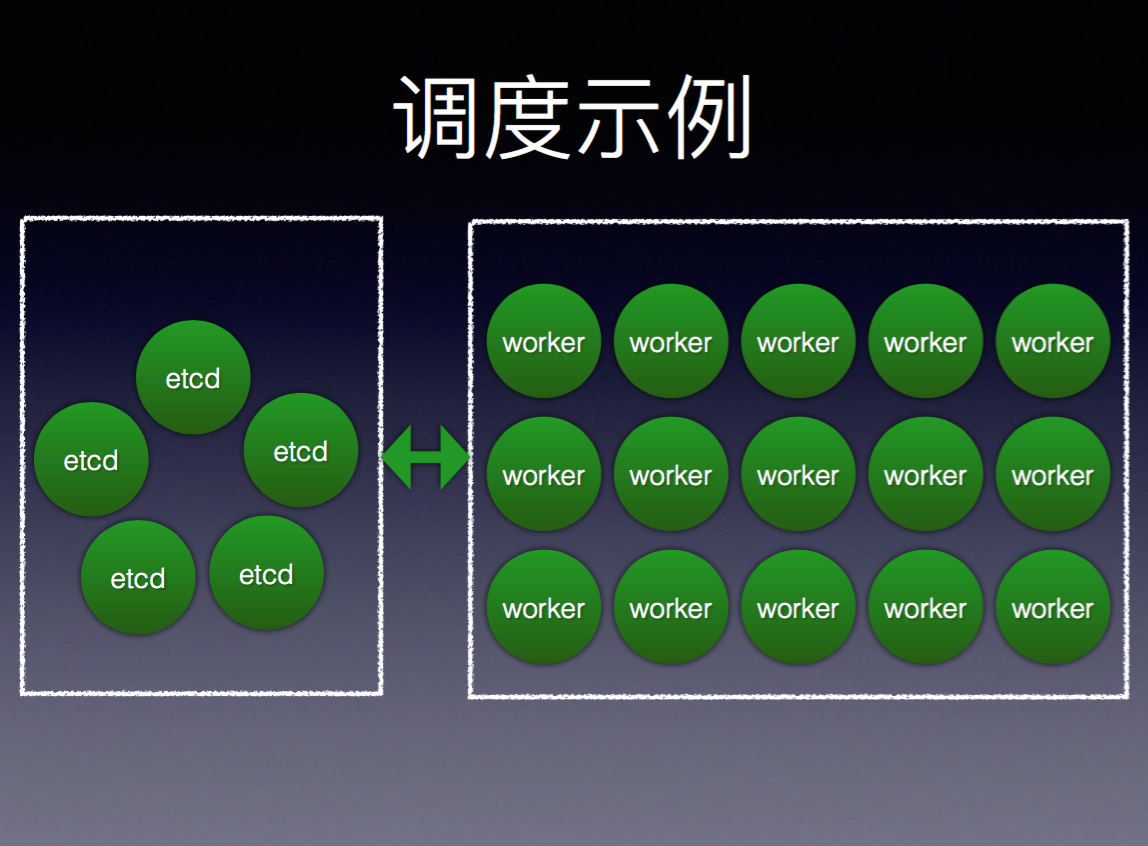
上图就是整个调度系统示例,五个节点的etcd为服务发现的控制核心,可以容忍2个节点挂掉,在worker区里,我们可以通过加节点的方式来动态扩大资源池。

那使用容器化有什么优势呢?我们来总结一下:
第一不限于操作系统。所有操作都一样的,根据业务需求,可以提供不同的数据库,不管谁来进行操作,最终得到的标准是统一的。
第二可以充分利用存储资源。 无状态和有状态的数据混用,充分利用线上资源。比如说我们线上的Redis集群,因有些机器内存用得不多,我可以部署到这些机器上来,把整个内存给用起来,这样就可以避免资源浪费。
第三调优的一致性。因为安装的模板都是统一的,操作起来就是标准化的东西。假如说某个数据库需要进一步优化的话,那我们可以统一地修改,然后批量地升级。
第四动态的扩容缩容。
其实数据库还是那些数据库,并不是说通过Docker,使数据库变得强大了或是性能更高了。其实我们做的只是一个简化或说是归一化,方便了数据存储的统一管理,降低了我们的维护成本。
下面分享一下我们踩过的坑。
自动化。其实我们可以自动化的,但是我们自动化的时候出现一个问题,比如说网络的波动以及业务突发状况,这些会导致判断的错误,迁移成本很高,最终导致整个迁移的失败,所以我们没有全过程的自动化。
关于Ceph和GlusterFS可能大家比较关注,我们也测了,它并不像官方说的能横向地增加机器做到横向扩展。机器增加到一定程度后,性能就不能提升了。我们对它们的处理也比较慎重,因为要保证数据的安全,我们最终的策略就是分小区来服务。如果有更好的分布式文件系统的话,我们也会不断地尝试,因为有这样一个平台,尝试的成本并不高。
点击下载PPT, 观看视频 。
本文由 李加庆 根据2016年1月24日 @Container容器技术大会·北京站 上 王鹏 的演讲《光音网络的存储容器化方案探索》整理而成。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

