干货|语音识别框架最新进展——深度全序列卷积神经网络登场
导读:目前最好的语音识别系统采用双向长短时记忆网络(LSTM,LongShort Term Memory),但是,这一系统存在训练复杂度高、解码时延高的问题,尤其在工业界的实时识别系统中很难应用。科大讯飞在今年提出了一种全新的语音识别框架——深度全序列卷积神经网络(DFCNN,Deep Fully Convolutional NeuralNetwork),更适合工业应用。本文是对科大讯飞使用DFCNN应用于语音转写技术的详细解读,其外还包含了语音转写中口语化和篇章级语言模型处理、噪声和远场识别和文本处理实时纠错以及文字后处理等技术的分析。
人工智能的应用中,语音识别在今年来取得显著进步,不管是英文、中文或者其他语种,机器的语音识别准确率在不断上升。其中,语音听写技术的发展最为迅速,目前已广泛在语音输入、语音搜索、语音助手等产品中得到应用并日臻成熟。但是,语音应用的另一层面,即语音转写,目前仍存在一定的难点,由于在产生录音文件的过程中使用者并没有预计到该录音会被用于语音识别,因而与语音听写相比,语音转写将面临说话风格、口音、录音质量等诸多挑战。
语音转写的典型场景包括,记者采访、电视节目、课堂及交谈式会议等等,甚至包括任何人在日常的工作生活中产生的任何录音文件。 语音转写的市场及想象空间是巨大的,想象一下,如果人类可以征服语音转写,电视节目可以自动生动字幕、正式会议可以自动形成记要、记者采访的录音可以自动成稿……人的一生中说的话要比我们写过的字多的多,如果有一个软件能记录我们所说过的所有的话并进行高效的管理,这个世界将会多么的让人难以置信。
基于DFCNN的声学建模技术
语音识别的声学建模主要用于建模语音信号与音素之间的关系, 科大讯飞继去年12月21日提出前馈型序列记忆网络(FSMN, Feed-forward Sequential Memory Network)作为声学建模框架后,今年再次推出全新的语音识别框架,即深度全序列卷积神经网络(DFCNN,Deep Fully Convolutional NeuralNetwork) 。
目前最好的语音识别系统采用双向长短时记忆网络(LSTM,LongShort Term Memory),这种网络能够对语音的长时相关性进行建模,从而提高识别正确率。但是双向LSTM网络存在训练复杂度高、解码时延高的问题,尤其在工业界的实时识别系统中很难应用。因而科大讯飞使用深度全序列卷积神经网络来克服双向LSTM的缺陷。
CNN早在2012年就被用于语音识别系统,但始终没有大的突破。主要的原因是其使用固定长度的帧拼接作为输入,无法看到足够长的语音上下文信息;另外一个缺陷将CNN视作一种特征提取器,因此所用的卷积层数很少,表达能力有限。
针对这些问题,DFCNN使用大量的卷积层直接对整句语音信号进行建模。首先,在输入端DFCNN直接将语谱图作为输入,相比其他以传统语音特征作为输入的语音识别框架相比具有天然的优势。其次,在模型结构上,借鉴了图像识别的网络配置,每个卷积层使用小卷积核,并在多个卷积层之后再加上池化层,通过累积非常多的卷积池化层对,从而可以看到非常长的历史和未来信息。这两点保证了DFCNN可以出色的表达语音的长时相关性,相比RNN网络结构在鲁棒性上更加出色,同时可以实现短延时的准在线解码,从而可用于工业系统中。
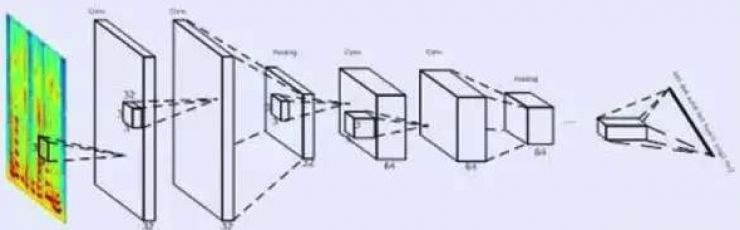
(DFCNN 结构图)
口语化和篇章级语言模型处理技术
语音识别的语言模型主要用于建模音素与字词之间的对应关系。由于人类的口语为无组织性的自然语言,人们在自由对话时,通常会出现犹豫、回读、语气词等复杂的语言现象,而以文字形式存在的语料通常为书面语,这两种之间的鸿沟使得针对口语语言的语言模型建模面临极大的挑战。
科大讯飞借鉴了语音识别处理噪声问题采用加噪训练的思想,即在书面语的基础上自动引入回读、倒装、语气词等口语“噪声”现象,从而可自动生成海量口语语料,解决口语和书面语之间的不匹配问题。首先,收集部分口语文本和书面文本语料对;其次,使用基于Encoder-Decoder的神经网络框架建模书面语文本与口语文本之间的对应关系,从而实现了口语文本的自动生成。
另外,上下文信息可以较大程度帮助人类对语言的理解,对于机器转录也是同样的道理。 因而,科大讯飞在去年12月21提出了篇章级语言模型的方案,该方案根据语音识别的解码结果自动进行关键信息抽取,实时进行语料搜索和后处理,用解码结果和搜索到的语料形成特定语音相关的语言模型,从而进一步提高语音转写的准确率。
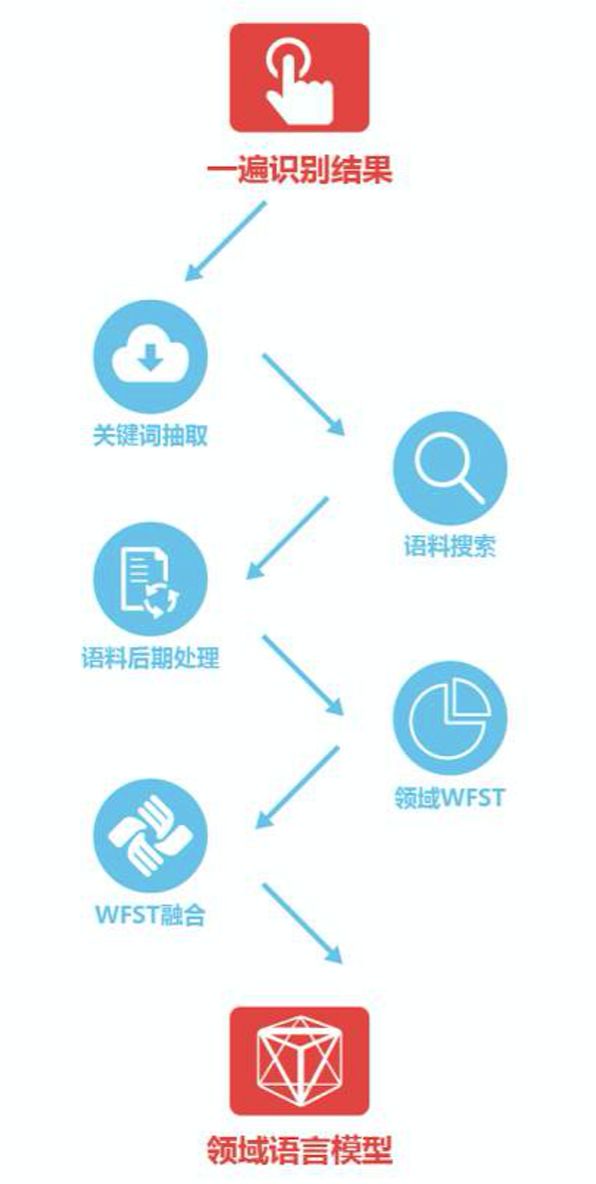
(篇章级语言模型流程图)
噪声和远场识别技术
语音识别的应用远场拾音和噪声干扰一直是两大技术难题。例如在会议的场景下,如果使用录音笔进行录音,离录音笔较远说话人的语音即为远场带混响语音,由于混响会使得不同步的语音相互叠加,带来了音素的交叠掩蔽效应,从而严重影响语音识别效果;同样,如果录音环境中存在背景噪声,语音频谱会被污染,其识别效果也会急剧下降。科大讯飞针对该问题使用了单麦克及配合麦克风阵列两种硬件环境下的降噪、解混响技术,使得远场、噪声情况下的语音转写也达到了实用门槛。
-
单麦克降噪、解混响
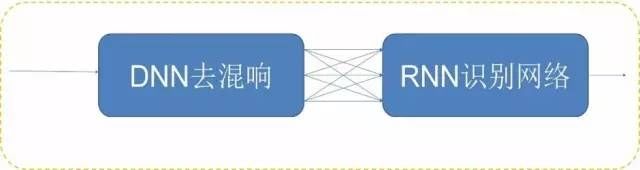
对采集到的有损失语音,使用混合训练和基于深度回归神经网络降噪解混响结合的方法。即一方面对干净的语音进行加噪,并与干净语音一起进行混合训练,从而提高模型对于带噪语音的鲁棒性(编者注:Robust的音译,即健壮和强壮之意);另一方面,使用基于深度回归神经网络进行降噪和解混响,进一步提高带噪、远场语音的识别正确率。
-
麦克风阵列降噪、解混响
仅仅考虑在语音处理过程中的噪音可以说是治标不治本,如何从源头上解决混响和降噪似乎才是问题的关键。面对这一难题,科大讯飞研发人员通过在录音设备上加上多麦克阵列,利用多麦克阵列进行降噪与解混响。具体地,使用多个麦克风采集多路时频信号,利用卷积神经网络学习波束形成,从而在目标信号的方向形成一个拾音波束,并衰减来自其他方向的反射声。该方法与上述单麦克降噪和解混响的结合,可以进一步显著的提高带噪、远场语音的识别正确率。
文本处理实时纠错+文字后处理
前面所说的都只是对于语音的处理技术,即将录音转录成文字,但正如上文所述人类的口语为无组织性的自然语言,即使在语音转写正确率非常高的情况下,语音转写文本的可阅读性仍存在较大的问题,所以文本后处理的重要性就体现了出来。所谓文本后处理即对口语化的文本进行分句、分段,并对文本内容的流利性进行处理,甚至进行内容的摘要,以利于更好的阅读与编辑。
-
后处理Ⅰ:分句与分段
分句,即对转写文本按语义进行子句划分,并在子句之间加注标点;分段,即将一篇文本切分成若干个语义段落,每个段落描述的子主题各不相同。
通过提取上下文相关的语义特征,同时结合语音特征,来进行子句与段落的划分;考虑到有标注的语音数据较难获得,在实际运用中科大讯飞利用两级级联双向长短时记忆网络建模技术,从而较好的解决了分句与分段问题。
-
后处理Ⅱ:内容顺滑
内容顺滑,又称为不流畅检测,即剔除转写结果中的停顿词、语气词、重复词,使顺滑后的文本更易于阅读。
科大讯飞通过使用泛化特征并结合双向长短时记忆网络建模技术,使得内容顺滑的准确率达到了实用阶段。
来源:科大讯飞公众号
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

