浅谈Raft
本博客采用创作共用版权协议, 要求署名、非商业用途和保持一致. 转载本博客文章必须也遵循 署名-非商业用途-保持一致 的创作共用协议.
工作忙了,总是骗自己说的没时间写博客,其实都是自己懒癌发作而已。题目写了浅谈,肯定文章是不够深入透彻的,刚刚爬进分布式门槛的婴儿,需要慢慢的学会走路。希望后面能通过自己总结再来一篇 深入理解Raft (显然又在挖坑
一致性算法特性
-
安全性保证:在非拜占庭错误情况下,包括网络延迟、分区、丢包、冗余和乱序等错误都可以保证正确。 -
可用性:集群中只要有大多数的机器可运行并且能够相互通信、和客户端通信,就可以保证可用。因此,一个典型的包含 5 个节点的集群可以容忍两个节点的失败。服务器被停止就认为是失败。他们当有稳定的存储的时候可以从状态中恢复回来并重新加入集群。paxos在有2f + 1个节点时可以容忍f个节点失败. -
不依赖时序来保证一致性:物理时钟错误或者极端的消息延迟在可能只有在最坏情况下才会导致可用性问题。 - 通常情况下,一条指令可以尽可能快的在集群中大多数节点响应一轮远程过程调用时完成。小部分比较慢的节点不会影响系统整体的性能。
Paxos算法
提到Raft算法的同时, 总是无法避免的要说起Paxos, 在Raft论文中也提到, Raft算法初衷是为了解决Paxos难以理解而提出, 所以总要看看Paxos算法到底是个什么东西
Paxos算法的缺陷:
- Paxos 算法
难以理解 - Paxos算法没有提供一个足够好用来构建一个现实系统的基础
Raft算法
Raft是一种为了 管理复制日志 的 一致性算法
- Raft 将一致性算法分解成了
领导人(leader)选举、日志复制和安全性三个模块.
Raft算法的特性:
-
强领导者:Raft 使用一种更强的领导能力形式。比如,日志条目只从领导者发送给其他的服务器。这种方式简化了对复制日志的管理并且使得 Raft 算法更加易于理解。 -
领导选举:Raft 算法使用一个随机计时器来选举领导者。这种方式只是在任何一致性算法都必须实现的心跳机制上增加了一点机制。 -
关系调整:Raft 使用一种共同一致的方法来处理集群成员变换的问题,在这种方法中,两种不同的配置都要求的大多数机器会重叠。这就使得集群在成员变换的时候依然可以继续工作。
领导人选举
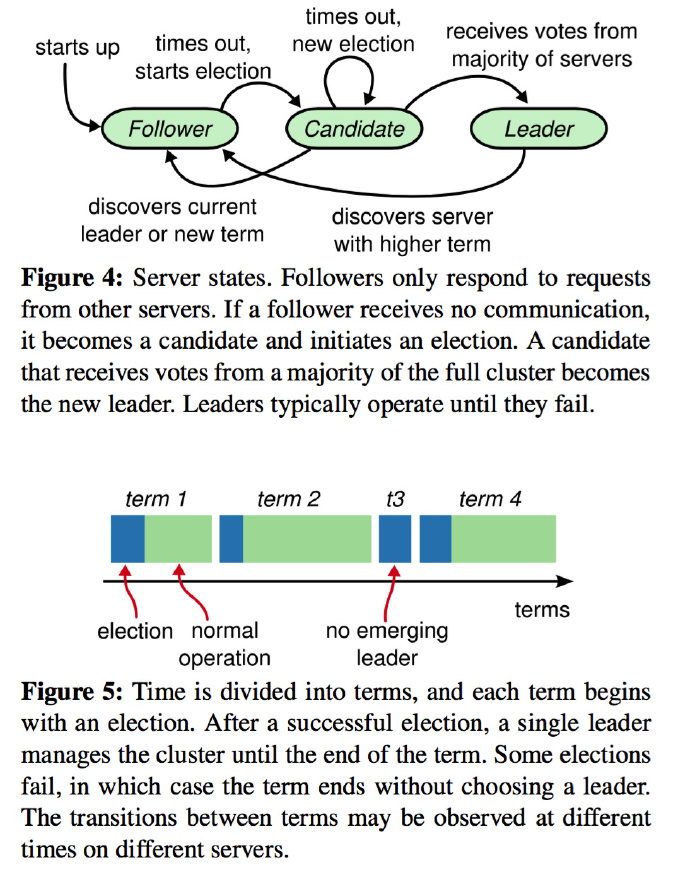
- 在任何时刻,每一个服务器节点都处于这三个状态之一:领导人(leader)、跟随者(follower)或者候选人(candidate). 跟随者都是被动的:他们不会发送任何请求,只是简单的响应来自领导者或者候选人的请求。领导人处理所有的客户端请求
- Raft 把时间分割成任意长度的
任期(terms), 如上面图中的Figure 5, 任期用连续的整数标记。每一段任期从一次选举开始,一个或者多个候选人尝试成为领导者。如果一个候选人赢得选举,然后他就在接下来的任期内充当领导人的职责。在某些情况下,一次选举过程会造成选票的瓜分。在这种情况下,这一任期会以没有领导人结束(t3);一个新的任期(和一次新的选举)会很快重新开始。Raft 保证了在一个给定的任期内,最多只有一个领导者 - 领导者
周期性的向所有跟随者发送心跳包。如果一个跟随者在一段时间里没有接收到任何消息,也就是选举超时, 然后他就会认为系统中没有可用的领导者然后开始进行选举以选出新的领导者。 - 此跟随者先要增加自己的
当前任期号并且转换到候选人状态, 开始进入 领导人选举 . 他会并行的向集群中的其他服务器节点发送RPC请求给自己投票。候选人会继续保持着当前状态直到以下三件事情之一发生:(a) 他自己赢得了这次的选举, 则向其他服务器发送心跳检测,(b) 其他的服务器成为领导者, 候选者选为跟随者,(c) 一段时间之后没有任何一个获胜的人, 每一个候选人都会超时,然后通过增加当前任期号来开始一轮新的选举。
日志复制
日志复制具有以下特性:
- 如果在不同的日志中的两个条目拥有相同的索引和任期号,那么他们存储了相同的指令。
- 如果在不同的日志中的两个条目拥有相同的索引和任期号,那么他们之前的所有日志条目也全部相同
可能因为领导者在日志提交前挂掉, 导致所有的服务器中的日志不一定的情况. 领导人处理不一致是通过强制跟随者直接复制自己的日志来解决了.
领导人针对每一个跟随者维护了一个 nextIndex ,这表示下一个需要发送给跟随者的日志条目的索引地址。当一个领导人刚获得权力的时候,他初始化所有的 nextIndex 值为自己日志中的最后一条。如果一个跟随者的日志和领导人不一致,那么在下一次的附加日志 RPC 时的一致性检查就会失败。在被跟随者拒绝之后,领导人就会减小 nextIndex 值并进行重试。最终 nextIndex 会在某个位置使得领导人和跟随者的日志达成一致。当这种情况发生,附加日志 RPC 就会成功,这时就会把跟随者冲突的日志条目全部删除并且加上领导人的日志。一旦附加日志 RPC 成功,那么跟随者的日志就会和领导人保持一致,并且在接下来的任期里一直继续保持。
安全性
- 选举限制, 候选人发起RPC 中包含了候选人的日志信息,投票人会拒绝掉那些日志没有自己新的投票请求
- 如果已经服务器已经在某个给定的索引值应用了日志条目到自己的状态机里,那么其他的服务器不会应用一个不一样的日志到同一个索引值上
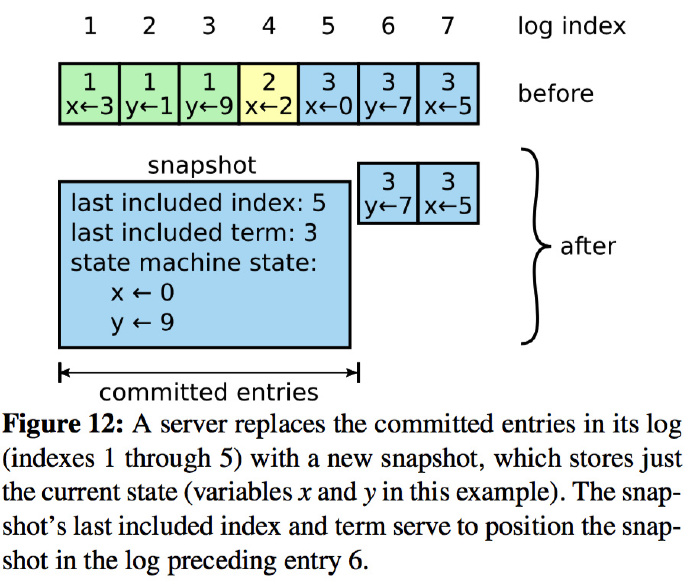
日志压缩
目的是减少不断增长的日志所占用服务器空间大小
采用的方法如下图:
客户端交互
- 客户端发送command给领导人, 若领导人未知,挑选任意节点,若该节点不是领导人,则重定向至领导人
- 领导人追加日志项,等待
提交,更新本地状态机,最终响应客户端 - 若客户端超时,则不断重试,直至收到响应为止
参考链接
- Raft官网
- illustrated Raft guide
- Paper:
In Search of an Understandable Consensus Algorithm - Raft一致性算法
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

