记一次 Redis 规模化运维讨论会(含 PPT)
7月29日下午,在滴滴,有幸邀请到了业界的一些同学,一起就「redis规模化运维」踩过的坑和最佳实践,做了深入的讨论和交流。知识是无价的,分享却是无私的,非常感谢各位朋友们的参与。「世上本没有路,填的坑多了,便成了路」共勉。
滴滴codis集群运维实践
主讲人:曾凡禹、刑惺
codis是滴滴业务依赖最重的基础服务之一,上千台服务器,上百套集群。过多的集群,给运维上带来了很多的挑战和阻碍,这是由于对codis的集群稳定性把控不足,为了减少单个集群故障对业务的影响范围,所以不得已而为之,物理上的隔离造成了集群数量变多,同时资源利用率无法最大化。
滴滴的同学,给我们从以下几个方面,做了拆解:
-
滴滴redis架构的演进
-
codis在运维中存在的一些问题
-
codis连接关闭慢引发的事故
-
滴滴对于codis的一些改进
小米redis运维实践
主讲人:卓汝林、张文
小米的同学,从redis-cluster3.0 beta7(2014年6月),就开始引入生产环境尝试,到目前的百余个集群,数千个节点的规模,单个集群内存容量1TB+,15亿+的键,百万级QPS的吞吐量,其中经历了各种各样的问题,也积累了丰富的实践经验。
汝林从以下几个方面为我们做了精彩的呈现:
-
RedisCluster在小米的运营简介
-
Redis Monitor and Alarm
-
Redis Troubleshooting cases
-
Redis Cluster capacity planning
-
Redis大规模运营过程遇到的问题
从汝林的分享中,我们深深感受到了小米的同学,精细化运维的态度和追求极致的精神,以监控为例,监控维度覆盖了CPU、IO、Memory、Network、Latency、再到redis自身运行相关的业务指标,都做了详尽的覆盖和研究,确保了集群的运行状态都处于可控、透明的状态。
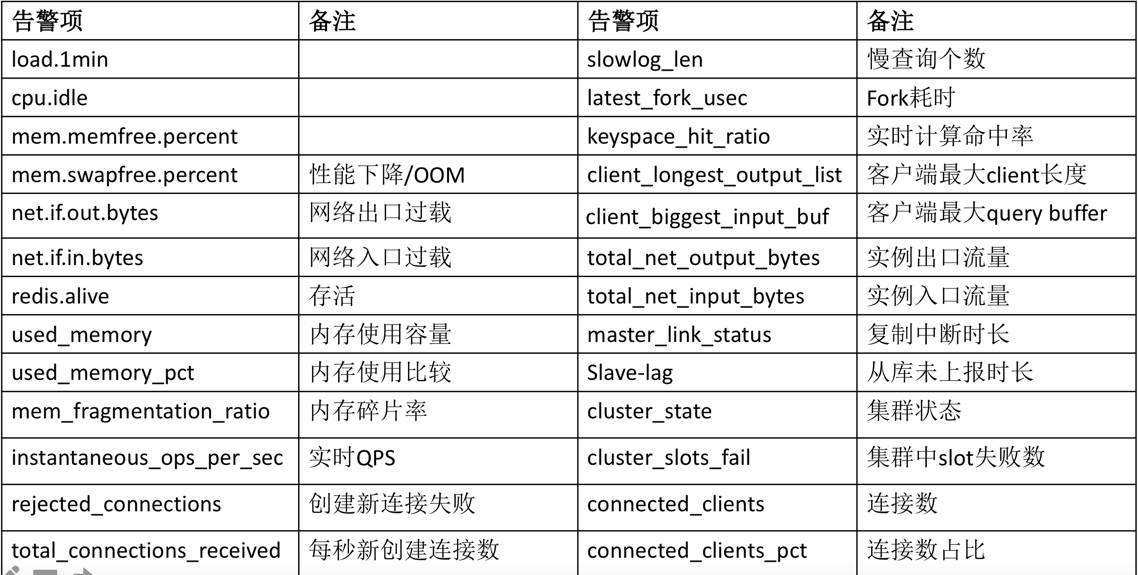


此外,汝林也细数了在redis cluster运维过程中,踩过的各种坑,以及对应的排查思路和解决方案,从理论到实践,都做了非常详细的阐述,是不可多得的第一手资料。
优酷蓝鲸系统简介
主讲人:吴建超
吴建超同学,分享了优酷基于redis cluster所构建的一体化存储解决方案,为我们打开了另外一种思路,感受到了不同的运维风格。
-
集群目前的状况
-
集群结构
-
我们在SDK方面的工作
-
我们在运维方面的工作
-
监控、报警
-
重写运维脚本
微博redis服务化之路
主讲人:曹增涛
微博作为国内最早大规模使用redis的公司之一,在redis方面做了非常多的探索和优化。曹增涛同学,从以下方面给大家做了深入的分享。
-
redis在微博应用介绍
-
redis在微博架构中的应用
-
redis运维中遇到的一些问题及改造
-
redis服务化之路
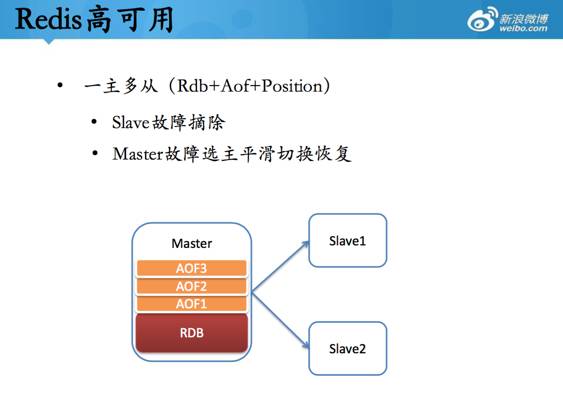
微博在对redis的持续优化中,最令人印象深刻的,包括有“主从优化”、“支持动态升级”、“持久化优化”,其中动态升级,在规模化运维中,能帮助我们大幅提升效率。

在高可用方面,采用一主多从,故障自动选主等手段来保障,同时通过优化“主从同步”来提升效率和保障可用性。
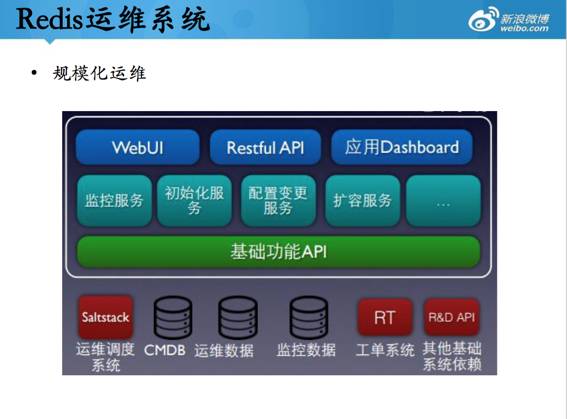
redis作为使用最广泛的服务,如何与整个运维体系打通,提升运维效率,也是至关重要的。
Redis in Baidu
主讲人:闫宇
百度云的闫宇同学,则着重从服务化的角度,详细的拆解了,redis在百度云的应用场景、优化、运维实践等方面,让我们感受到了“大厂的风范”:)
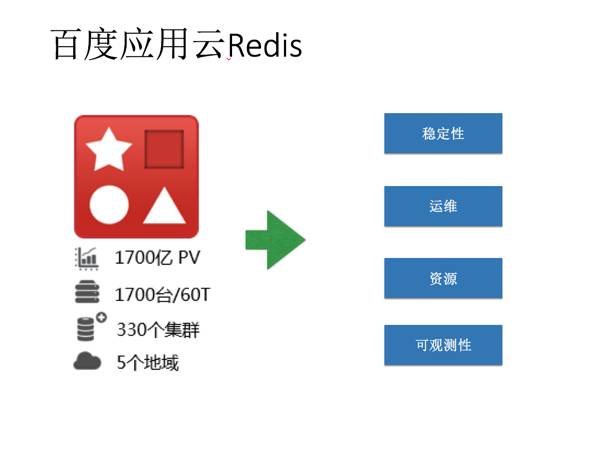
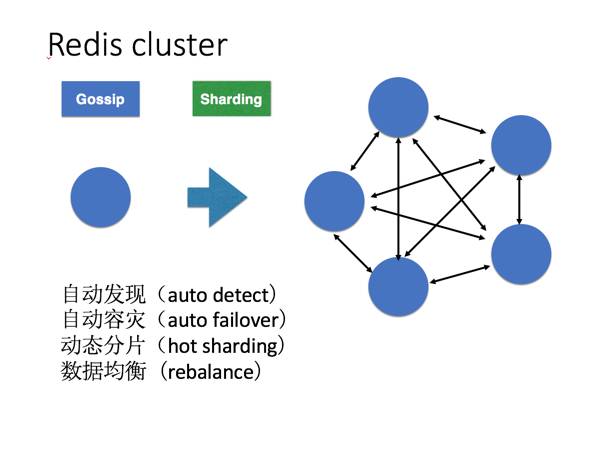
一个场景分析和改造的案例:

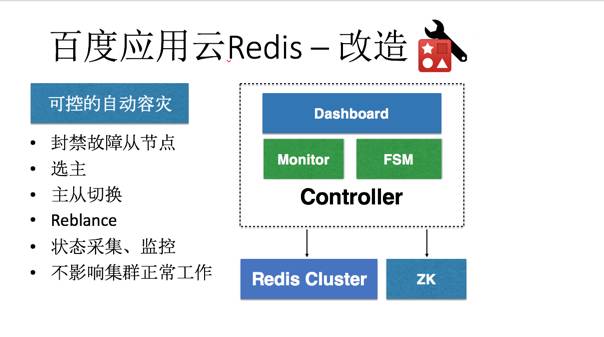
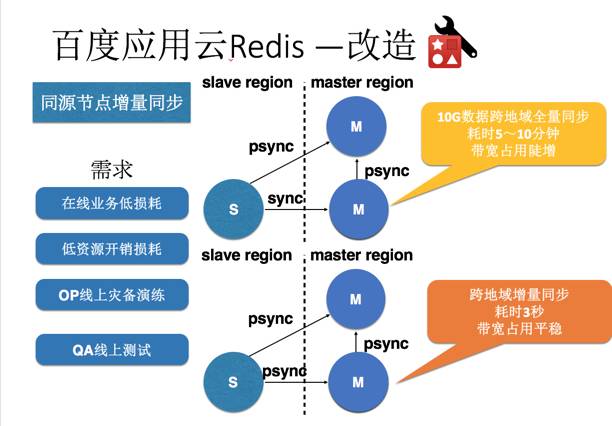

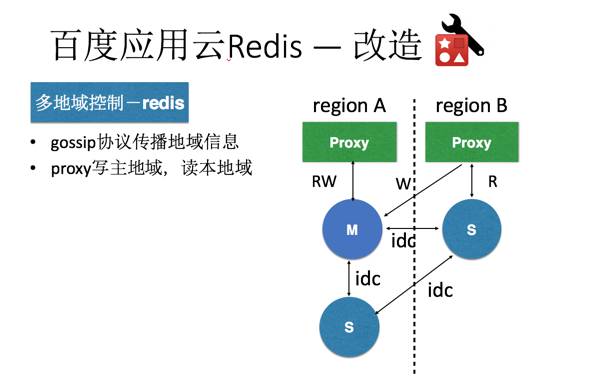
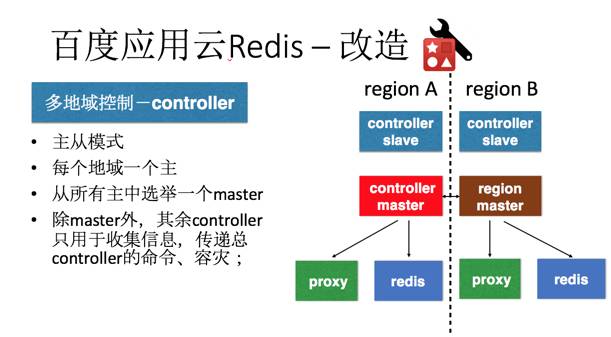
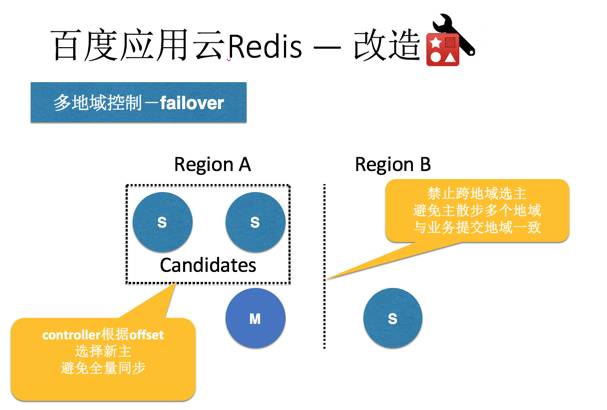
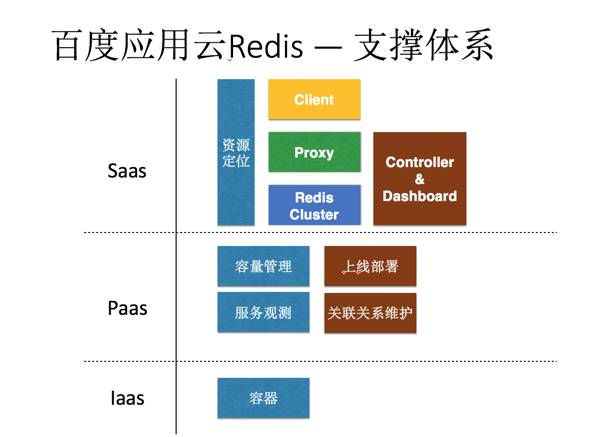
redis服务化支撑体系
饿了么redis运维实践
主讲人:郭浩川
最后,浩川同学,介绍了饿了么在redis运维自动化方面的工作,非常精彩,同时也分享了饿了么在运维过程中踩过的坑...


分享了他们在运维过程中总结出来的一些最佳实践


饿了么的redis监控非常体系化,给大家留下了非常深的印象。

送上现场照片,感谢各位朋友一起交流


最后点击“阅读原文”,下载各位同学的演讲材料,同时可以关注Open-Falcon公众号,大家更好的交流。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

