MongoDB和HDFS转存Redis
我们在河图上面提供的接口需要由原来的第一版升级为第二版。
第一版接口采用的是如下图所示的方案:
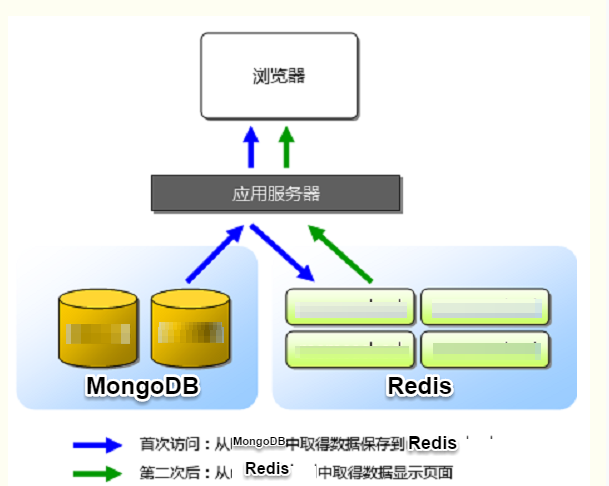
由上图所知,我们的第一版API接口设计,当前只对请求的query做了Cache,也就是之前有请求的数据能够在Redis中命中,快速响应,而对于未命中的query,需要查询恶意IP数据库(MongoDB),ElasticSearch,然后计算出结果Score,并返回给调用者,最后再对查询结果做Cache。
这样做的缺点是:后期需求量上来之后,我们所能提供的每秒查询率不够。
现在需要升级第二版,需要对我们的数据做全量Cache,即需要将来源于三个不同地方的数据按统一格式全部存到Reids中,并要考虑每天的增量数据。
问题难点:
目前数据主要来源于如下三个数据库:
-
用MongoDB存储的
恶意IP数据库,其数据格式为:{ "_id" : "14.145.225.34_2015-09-03_0", "Count" : [ "Total##**##1" ], "_type" : 0, "Service" : [ "tieba##**##1" ], "RuleName" : [ "RULE_MULTIPART_DOS##**##1" ], "UA" : [ "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)##**##1" ], "Uri" : [ "/c/s/getClientConfig?cmd=303039##**##1" ], "_date" : "2015-09-03", "_ip" : "14.145.225.34" }
-
用另一个MongoDB存储的
蜜罐数据,其格式为:{ "_id" : ObjectId("56f101049e84a61d5ceafc19"),
"attack_history" :
[ { "attack_type" : "crack_password", "source" : "web_request_log", "end_time" : "2016-03-04 12:42:03", "date" : "2016-03-04", "attack_target" : "usr.mb.hd.sohu.com", "start_time" : "2016-03-04 03:53:47", "attack_count" : 92734, "description" : "" } ],
"indicator" : "111.192.46.41",
"status" : "MALICIOUS",
"sub_status" : [ "crack_password" ],
"type" : "IP" } -
用HDFS存储的
DNS数据,其格式为:{
"domain": "90gj65.oqnlo196.cn",
"update": "2016-01-03 03:08:47",
"create": "2015-12-15 08:43:08",
"evil_type": ["3"],
"history": [
{
"ip": [
"98.126.8.11"
],
"source": "public",
"date": "2015-12-14"
},
}
该问题的难点在于:这三个数据库中存储的数据格式均不相同,且相互之间有一定交叉。需要把这些数据处理合并计算之后成为一个数据,按照同样的格式存进Redis数据库里面,并且需要考虑以后的每日增量数据更新的问题。
问题解决方案:
-
关于存进Redis数据库中的格式:
我们最终需要的是,当别人输入查询某个IP的时候,我们能给出其IP的四个维度的信息:
(1). 该IP在恶意IP库中最近出现的时间;
(2). DNS域名服务器中最近出现的时间;
(3). 该IP所绑定的域名数量;
(4). 域名数量中恶意域名的数量;
这四个维度分别对应存储进Redis中Value的四个值。
因此Redis的哈希存储(HSET)符合我们的业务需求,而根据数据存储方式,初步有如下两套方案:
方案一:

方案二:

方案一在最终的查询效率上面要高,对C段查询请求的支持较好,但存数据的时候Value信息不好存。
方案二非常容易存数据,但对C段查询支持不太好。
考虑到最终的查询效率,最终决定采用 方案一 。
-
最终给出如下的大致解决方案:
一个IP地址对应的所填Value的4个值:
-
恶意IP库中最近出现的时间:只与mongoDB有关python程序连接好两个mongo数据库,在数据库中例如查询,只需注意“indicator”字段,表示IP,然后attack_history字段里面的end_time,注意进行内部比较。入Redis库。
-
DNS中最近时间:只与DNS有关 -
域名数量:只与DNS有关 -
恶意域名数量:只与DNS有关针对后三个值,打算用Redis-Spark直接进行读写。再合并第一个字段,最终进行插入。
实际解决过程:
1.处理DNS数据
针对 DNS 数据,由于其在HDFS上有一个备份,因此直接用我们的Spark集群处理。具体处理代码
ipdomain_spark.py 如下,这是Spark上所提交的应用代码:
import random
import sys
import time,datetime
import json
reload(sys)
sys.setdefaultencoding('utf-8')
from pyspark import SparkContext,SparkConf
hdfsdir="hdfs://yq01-sw-hds01.yq01.baidu.com:8020/xlab/dnsinfo/"
resultdir = "hdfs://yq01-softwareresearch-cymirr00.yq01.baidu.com:9000/dailywork/ipdomain/"
#/*************************Public Dns Functions*************************/
def getIPs(data):
if "evil_type" in data:
evil_type = 1
else:
evil_type = 0
ipdict = {}
for item in data["history"]:
day = item["date"]
for ip in item["ip"]:
if ip in ipdict:
if day>ipdict[ip]:
ipdict[ip] = day
else:
ipdict[ip] = day
iplist = []
for ip,xdate in ipdict.items():
iplist.append((ip,[xdate,1,evil_type]))
return iplist
def mergeByIp(x,y):
if x[0]<y[0]:
x[0] = y[0]#for date
x[1] += y[1]#for domain nums
x[2] += y[2]#for evil domain nums
return x
def toStr(data):
data[1].insert(0,"0000-00-00")
return "%s/t%s"%(data[0],json.dumps(data[1]))
if __name__ == "__main__":
curtime=sys.argv[1]
conf = SparkConf().setAppName("selectActiveIps")/
.set("spark.network.timeout","3000")/
.set("spark.yarn.executor.memoryOverhead","3072")/
.set("spark.yarn.driver.memoryOverhead","3072")/
.set("spark.akka.frameSize","500")
sc = SparkContext(conf=conf)
wholeData=sc.pickleFile(hdfsdir+curtime+"/elasticwhole")/
.flatMap(getIPs)/
.reduceByKey(mergeByIp,2000)/
.map(toStr)/
.coalesce(20)
wholeData.saveAsTextFile(resultdir+curtime)
sc.stop()
这是Spark提交任务的脚本 ipdomain.sh :
#/**************************normal settings***********************/
hdfsdir='hdfs://yq01-softwareresearch-cymirr00.yq01.baidu.com:9000/dailywork/'
sparkdir='/home/work/spark/spark-1.6.1-bin-hadoop2.6/bin/'
yarndir='/home/work/hadoop/hadoop/hadoop-2.6.0/bin/'
#resourcedir='/home/work/chenfeiyan/dns/data/resource/'
#srcdir='/home/work/chenfeiyan/dns/src/'
#datadir='/home/work/chenfeiyan/dns/data/'
#logdir='/home/work/chenfeiyan/dns/data/logs/'
#################################################################################
export YARN_CONF_DIR=/home/work/hadoop/hadoop/hadoop-2.6.0/etc/hadoop
${sparkdir}/spark-submit --master yarn /
--deploy-mode cluster /
--queue default /
--num-executors 100 /
--executor-cores 4 /
--driver-cores 4 /
--executor-memory 15g /
--driver-memory 20g /
ipdomain_spark.py $1
if [ $? -eq 0 ];then
unset YARN_CONF_DIR
else
exit 1
fi
这样处理之后使原来的DNS数据变为如下格式:
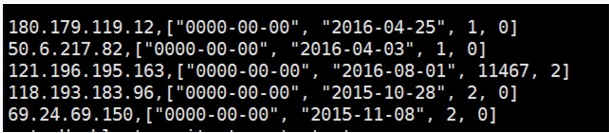
其中“0000-00-00”就是等待另外两个数据库处理之后把该日期插进去。
2.处理恶意IP数据
针对 MongoDB 中的 恶意IP数据 ,按如直接查询处理,直接按脚本 emongo2redis.py 运行,代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import pymongo
import os
client_evilips = pymongo.MongoClient('nmg02-sw-cce00.nmg02', 30000)
db_evilips = client_evilips.ticdb
collection_evilips = db_evilips.evilips
data2=collection_evilips.find({},{'indicator':1,'attack_history.date':1})
file = open("evilips.txt","r+w")
for i in data2:
if i.has_key('attack_history'):
listA=i['attack_history']
record = {'date':'0','ip':'0'}
record['ip']=i['indicator']
for item in listA:
if item['date'] >= record['date']:
record['date']=item['date']
s = str(record['ip']+","+record['date']+os.linesep)
file.write(s)
file.close()
这里得到一个 evilips.txt 文件,里面数据个数如下:
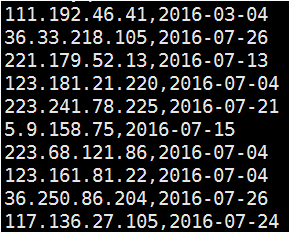
IP和日期用逗号隔开。
3.处理蜜罐数据
针对 MongoDB 中的 蜜罐数据 ,直接查询之后,还需要进行日期的比较,直接按脚本 mongo2reids.py 运行,代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import pymongo
import os
client_urltable = pymongo.MongoClient('cq02-cce000.cq02', 27017)
db_urltable = client_urltable.urldb
collection_urltable = db_urltable.urltable
data_urltable = collection_urltable.find({},{'_ip':1,'_date':1,'_id':0})
file = open("urltable.txt", "r+w")
counter,s=0,''
for ii in data_urltable:
counter+=1
s += str(ii['_ip']+","+ii['_date']+os.linesep)
if counter >= 100000:
file.write(s)
counter,s=0,''
if counter:
file.write(s)
file.close()
这里得到一个 urltable.txt ,数据格式如下:
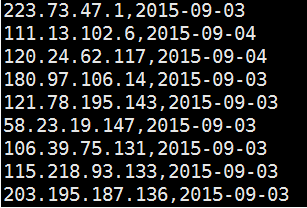
4.数据合并
将 urltable.txt 和 evilips.txt 中的数据进行合并,推送到Spark的HDFS中,其保存路径为: /dailywork/ipdomain/ipmongo2.txt ,而此时Spark中还有我们第一步处理的数据,保存路径为: /dailywork/ipdomain/2016-08-01 ,将这两个数据进行合并,合并方式为:以DNS数据为准,IP为唯一主键,当ipmongo2.txt中有DNS中的IP时,将后面的日期插入DNS的第一个Value中。因此用Spark中的 leftOuterJoin 函数。而此时遇到的第一个问题是,按照道理,jion之后的数据条目不应该比DNS的数据条目还要多,当时出现的问题是:DNS中有 21948374 条记录,ipmongo2.txt中有 5855408 条记录,jion之后有 22505689 条数据,也就是说,jion之后的数据条目增多了,这是不正常的。后面反复排查错误,直到发现ipmongo2.txt中有键值相同的数据,于是将键值相同的数据进行去重,去重的同时,依然要比较他们后面日期值的大小,保留最近的日期进行保存。去重之后的恶意IP数据有 2714252 条记录,此时再Jion,就正常了。最后给出 ipdomain_spark_jion.py 代码如下:
import json
import sys
from pyspark import SparkContext,SparkConf
hdfsdir="hdfs://yq01-softwareresearch-cymirr00.yq01.baidu.com:9000"
#/*************************Public Dns Functions*************************/
def replace(data):
list=json.loads(data[1][0])
if data[1][1] == None:
return data[0]+"/t"+json.dumps(list)
else:
list[0]=data[1][1]
return data[0]+"/t"+json.dumps(list)
if __name__ == "__main__":
conf = SparkConf().setAppName("selectActiveIps")/
.set("spark.network.timeout","3000")/
.set("spark.yarn.executor.memoryOverhead","3072")/
.set("spark.yarn.driver.memoryOverhead","3072")/
.set("spark.akka.frameSize","500")
sc = SparkContext(conf=conf)
##2 mongoDB data
ipData=sc.textFile(hdfsdir+"/dailywork/ipdomain/ipmongo2.txt")
## Key Value pairs
smalldata=ipData.map(lambda x: (x.split(",")[0],x.split(",")[1]))
## Duplicate removal
reduce_smalldata=smalldata.reduceByKey( lambda x,y : x if x>=y else y )
## DNS data
wholeData=sc.textFile(hdfsdir+"/dailywork/ipdomain/2016-08-01")
## Key Value pairs
bigdata = wholeData.map(lambda x: (x.split("/t")[0],x.split("/t")[1]))
## join
lastData=bigdata.leftOuterJoin(reduce_smalldata)
## replace and sort
result=lastData.sortByKey().map(replace)
## Save data
result.saveAsTextFile(hdfsdir+"/test/temp1")
sc.stop()
提交脚本代码与第一步一样。
此时得到的数据格式为:
113.66.157.30,["2016-01-03", "2016-03-02", 1, 0]
180.97.69.40,["2016-07-31", "2015-11-23", 1, 0]
104.238.140.70,["2016-07-06", "2016-06-12", 1, 0]
137.175.47.157,["0000-00-00", "2016-08-01", 2230, 82]
可以看到有些IP的恶意域名数量为0,但是在恶意IP数据库里面出现过,而有些IP的恶意域名数量不为0,但是没有出现在恶意IP数据库里面,此时统计了一下,有9675条IP记录,既出现在了恶意域名数据库中,又出现在了DNS域名记录中。这里的几个数据很值得研究。
5.存到Redis集群中
将得到的数据存到Redis集群中。
Redis集群有几种存法,一个是官网给出的用这样的命令存:
cat data.txt | redis-cli
而data.txt中的数据格式为:
hset Key field value
hset Key filed value
……
就是一行一行从文本读命令,然后用客户端命令执行。
还有一个是基于Redis本身的事务机制,批量读取数据,然后做少量次数的存储。
最终,我是在Spark平台上直接import redis包处理的。这里遇到的第一个问题是,刚开始一直报莫名其妙的错误,后来发现Python的第三方redis包并不能处理集群的情况,只能处理单机版的情况,后来又换成了 redis-py-cluster 1.2.0 包,而该包也是依赖redis包的,因此提交运行的时候,两个包都要打包提交上去。第二个问题是,Spark平台报执行内存不足的错误,后来在提交的时候,需要在应用中指定大一点的内存,将 spark.driver.maxResultSize 调为 2g ,最后应用代码 spark2redis.py 为:
import json
import sys
from rediscluster import StrictRedisCluster
from pyspark import SparkContext,SparkConf
hdfsdir="hdfs://yq01-softwareresearch-cymirr00.yq01.baidu.com:9000"
#/*************************Public Dns Functions*************************/
if __name__ == "__main__":
conf = SparkConf().setAppName("selectActiveIps")/
.set("spark.network.timeout","3000")/
.set("spark.yarn.executor.memoryOverhead","3072")/
.set("spark.yarn.driver.memoryOverhead","3072")/
.set("spark.akka.frameSize","500")/
.set("spark.driver.maxResultSize","2g")
sc = SparkContext(conf=conf)
## connect to redis
startup_nodes = [{"host": "yq01-softwareresearch-cymirr30.yq01.baidu.com", "port": "6777"}]
rc = StrictRedisCluster(startup_nodes=startup_nodes)
## rawdata
rawdata = sc.textFile(hdfsdir+"/test/temp1")
## Key Value pairs
rawkv = rawdata.map(lambda x: (x.split("/t")[0],x.split("/t")[1]))
## initialization
## pipeline_redis = r.pipeline()
## count = 0
## batch_size = 10000
## hset to redis
for onerecord in rawkv.collect():
if onerecord[0].count('.') == 3:
ipc=onerecord[0].split(".")[0]+"."+onerecord[0].split(".")[1]+"."+onerecord[0].split(".")[2]
rc.hset(ipc, onerecord[0], onerecord[1])
## count += 1
## if not count % batch_size:
## pipeline_redis.execute()
#send the last batch
## pipeline_redis.execute()
sc.stop()
提交脚本为 ipdomain.sh :
#/**************************normal settings***********************/
hdfsdir='hdfs://yq01-softwareresearch-cymirr00.yq01.baidu.com:9000/dailywork/'
sparkdir='/home/work/spark/spark-1.6.1-bin-hadoop2.6/bin/'
yarndir='/home/work/hadoop/hadoop/hadoop-2.6.0/bin/'
export YARN_CONF_DIR=/home/work/hadoop/hadoop/hadoop-2.6.0/etc/hadoop
${sparkdir}/spark-submit --master yarn /
--deploy-mode cluster /
--queue default /
--num-executors 30 /
--executor-cores 4 /
--driver-cores 4 /
--executor-memory 15g /
--driver-memory 20g /
--py-files /home/work/qimingyu01/redis-py-cluster-1.2.0/rediscluster.zip,/home/work/qimingyu01/redis-2.10.5/redis.zip /
spark2redis.py
6.查询性能测试
将数据全部存入Redis集群后,查询结果如下:
-
单个记录查询测试结果:
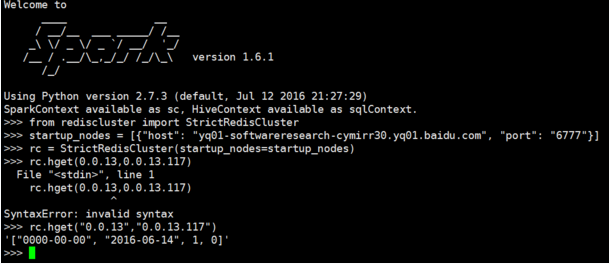
-
全部记录查询测试结果,返回所有的Key值:
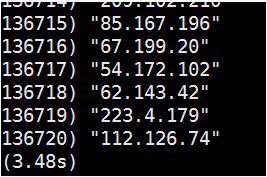
可见不到响应时长不超过4秒,相当的快。
【版权声明】
本文首发于 戚名钰的博客 ( http://qimingyu.github.io/ ),欢迎转载,但是必须保留本文的署名 戚名钰 (包含链接)。如您有任何商业合作或者授权方面的协商,请给我留言:mingyuqi.java@qq.com
本文永久链接: http://qimingyu.github.io/2016/08/07/MongoDB和HDFS转存Redis/
正文到此结束
- 本文标签: Word UI executor App 备份 src ip kk 数据库 GitHub json tab 博客 DNS map cache 域名 web client db 2015 description API Select Hadoop http js HDFS ORM 时间 zip list node python find redis DOM 测试 统计 git 集群 Service 需求 update value windows ACE tar 数据 MongoDB 服务器 core awk cat queue 代码 java key cmd
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

