跳表 & 散列 2 - 散列
继续是《数据结构算法与应用:C++语言描述》的笔记,这是第七章跳表和散列的内容,本节内容是介绍字典的另一种描述方法–散列。
散列表描述
理想散列
字典的另一种描述方法就是 散列(hash) ,它是用一个散列函数(hash function)把关键字映射到散列表(hash table)中的特定位置。
也就是使用哈希表来描述字典了。
在理想情况下,如果元素e的关键字是k,散列函数是f,那么e在散列表中的位置为$f(k)$。要搜索关键字为k的元素,首先要计算出$f(k)$,然后看$f(k)$处是否有元素,如果有,则找到该元素,如果没有,说明该字典中不包含该元素。在前一种情况中,如果要删除该元素,只需要把表中$f(k)$位置置为空即可,在后一种情况中,可以通过把元素放在$f(k)$位置以实现插入。
理想情况下,初始化一个空字典需要的时间为$/theta(b)$(b是散列表中位置的个数),搜索、插入和删除操作的时间均为$/theta(1)$。在许多场合都可以使用理想的散列方法,但对于关键字变化范围太大的应用是不能创建这样一个散列表的。
线性开型寻址散列
当关键字的范围太大,不能用理想方法表示时,可以采用比关键字范围小的散列表以及把多个关键字映射到同一个位置的散列函数。虽然有多种函数映射方法,但最常用的还是 除法映射 。其形式如下:
$$
f(k) = k /% D
$$
其中k是关键字,而D是散列表的大小,也就是位置数,而%是求模操作符。散列表中的位置号从0到D-1,每一个位置称为 桶(bucket) 。若关键字不是正整数型(如int,long,char, unsigned char等),则在计算f(k)之前必须把它转换成非负整数。对于一个长字符串,可以采用取其2个或4个字母来变成无符号整数或无符号长整数的方法。f(k)是存储关键字为k的元素的 起始桶 ,在良性情况下,起始桶中存储的元素即是关键字为K的元素。
下图中给出一个散列表ht,桶号从0到10,在图a中,表中只有3个元素,除数D是11,由于80%11=3,所以80的位置是3,40%11=7,65%11=10,每个元素都在相应的桶中,散列表中余下的桶为空。
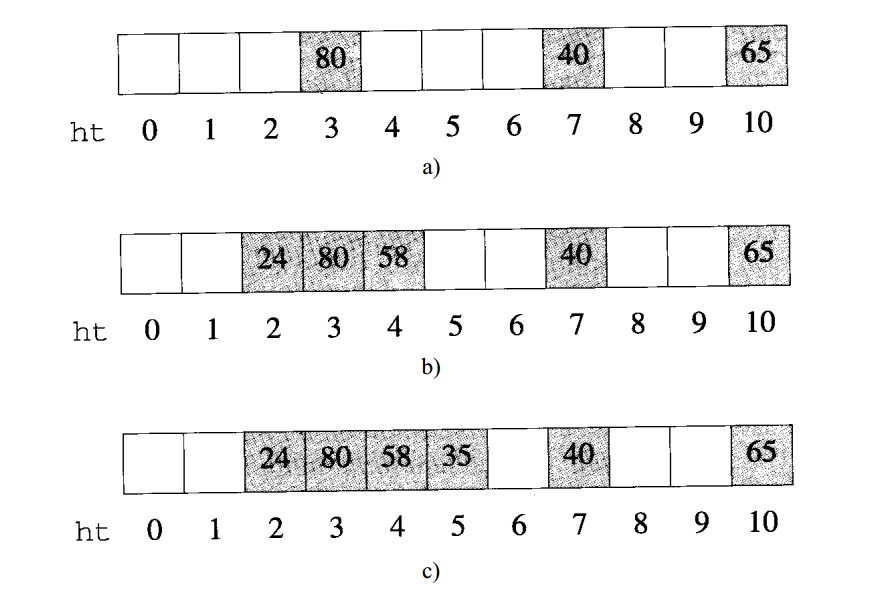
现在假设要插入58,58的起始桶应该是f(58)=58%11=3,但是此时该桶中已经放了80了,这个时候就发生了 碰撞 。一般来说,一个桶中是可以存储多个元素的,而存储桶中若没有空间就发生 溢出 。但在我们的表中,每个桶只能存储一个元素,因此同时发生了碰撞和溢出。这个时候处理58的最简单的办法就是将其存储到表中下一个可用的桶中,这种解决溢出的方法叫做 线性开型寻址(linear open addressing) 。
因此如图b所示,将58存放在4号桶中。假设下一个要插入的元素值是24,其起始桶应该是2,然后就放入2号桶中,然后要插入35,其起始桶是2号,使用线性开型寻址的方法,它将被放入5号桶,最后一个要插入的是98,而10号桶已经满了,此时它被插入0号桶中。 因此,在寻找下一个可用桶时,表被视为环形的。
下面给出采用线性开型寻址的散列表的类定义。在类定义中假定散列表中每个元素的类型都是E,每个元素都有一个类型为K的key域。key域是用来计算起始桶的,因此类型K必须能够适应取模操作%。散列表使用了两个数组,ht和empty。当且仅当ht[i]中不含有元素时,empty[i]为true。
template<class E, class K> class HashTable{ private: int hSearch(const K& k)const; // 散列函数的除数 int D; // 散列数组 E *ht; // 一维数组 bool *empty; public: HashTable(int divisor = 11); ~HashTable(){ delete[] ht; delete[] empty; } bool Search(const K& k, E& e)const; HashTable<E, K>& Insert(const E&e); HashTable<E, K>& Delete(const K&k, E& e); void Output(std::ostream&); };
下面给出搜索操作的实现,对于私有成员 hSearch 会返回b号桶的三种情况有:1) empty[b] == false && ht[b] == k ;2) empty[b] == true ,即表中没有关键字值为k的元素;3) empty[b] == true && ht[b] != k ,且表已满。
template<class E, class K> int HashTable<E, K>::hSearch(const K& k)const{ // 查找一个开地址表,如果存在,返回k的位置,否则返回插入点(如果有足够空间) // 起始桶 int i = k % D; // 在起始桶开始 int j = i; do{ if (empty[j] || ht[j] == k) return j; // 下一个桶 j = (j + 1) % D; } while (j != i); // j== i 表示回到起始桶 // 表已经满 return j; } template<class E, class K> bool HashTable<E, K>::Search(const K& k, E& e)const{ // 搜索与k相匹配的元素并放入e,如果不存在,则返回false; int b = hSearch(k); if (empty[b] || ht[b] != k) return false; e = ht[b]; return true; }
插入和删除操作如下,其中书中没有实现删除操作,而是作为课后练习题,所以删除操作是自己实现的。
template<class E, class K> HashTable<E, K>& HashTable<E, K>::Insert(const E& e){ // 在散列表中插入一个元素 K k = e; int b = hSearch(k); // 检查是否能完成插入 if (empty[b]){ empty[b] = false; ht[b] = e; return *this; } // 不能插入,检查是否有重复值或者表满 if (ht[b] == k){ std::cerr << "The key " << k << " already in the HashTable/n"; return *this; } else{ std::cerr << "The HashTable is full./n"; return *this; } } template<class E, class K> HashTable<E, K>& HashTable<E, K>::Delete(const K& k, E& e){ // 删除与k相匹配的元素,并放入e int b = hSearch(k); // 检查是否能进行删除操作 if (empty[b]){ std::cerr << "The key " << k << " is not in the HashTable/n"; return *this; } // 可以删除 e = ht[b]; empty[b] = true; ht[b] = 0; int i = b; int j = (b+1) % D; // 从下一个桶开始搜索是否存在另一个起始桶一样的元素 do{ if (!empty[j]){ if (ht[j] % D == i){ empty[i] = false; ht[i] = ht[j]; empty[j] = true; ht[j] = 0; i = j; } } j = (j + 1) % D; } while (j != b || empty[j]); }
更详细的例子可以查看 字典–哈希表实现
设b是散列表中桶的个数,散列函数中D为除数,且b=D。初始化表的时间是$/theta(b)$。当表中有n个元素时,最坏情况下插入和搜索时间均为$/theta(n)$。而当所有n个关键字值都在同一个桶中时出现最坏的情况。通过比较散列在最坏情况下的复杂性与线性表在最坏情况下的复杂性,可以看到两者完全相同。
但散列的平均性能还是相当好的。用$S_n$和$U_n$来分别表示一次成功搜索和不成功搜索中平均搜索的桶的个数。对于线性开型寻址,有如下公式成立:
$$
U_n /sim /frac{1}{2} (1+/frac{1}{(1-/alpha)^2}) /
S_n /sim /frac{1}{2} (1+/frac{1}{1-/alpha})
$$
其中$/alpha = /frac{n}{b}$是负载因子。
所以若$/alpha =0.5$,则在不成功搜索时平均搜索的桶的个数为2.5个,而成功搜索时则是1.5个。当$/alpha =0.8$,则是50.5和5.5。所以当负载因子为0.5时,使用线性开型寻址散列表的平均性能要比线性表好。
另一个影响性能的参数是D。 当D是素数或者D没有小于20的素数因子时,可以使性能达到最佳(D等于桶的个数b) 。
而确定D的值,首先要了解影响成功搜索和不成功搜索性能的因素。通过$S_n$和$U_n$的公式,可以确定$/alpha$的值,然后再结合n的值,可以得到b的最小许可值,然后找到一个比b大的最小整数,这个整数要么是素数,要么没有小于20的素数因子,这个整数即可作为D和b的值。
另一种计算D的方法是首先根据散列表的最大空间来确定b的最大可能值,然后取D为不大于这个最大值的整数,该整数要么是素数,要么没有小于20的素数因子。例如,如果在表中最多可以分配530个桶,则D和b的最佳选择为23(因23*23=529)。
链表散列
当散列发生溢出的时候,链表是一种好的解决方法。下图给出了散列表在发生溢出时采用链表来进行解决的方法。
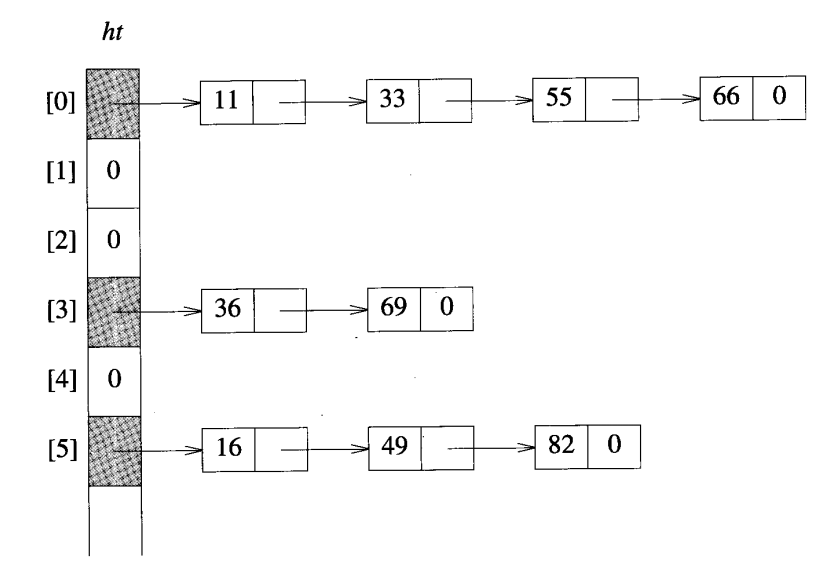
在该散列表的组织中,每个桶仅含有一个节点指针,所有的元素都是存储在该指针所指向的链表中。
下面给出代码实现,该类使用了类 SortedChain 的成员。
template<class E, class K> class ChainHashTable{ private: // 位置数 int D; // 链表数组 SortedChain<E, K>* ht; public: ChainHashTable(int divisor = 11){ D = divisor; ht = new SortedChain<E, K>[D]; } ~ChainHashTable(){ delete[] ht; } bool Search(const K&k, E& e)const{ return ht[k%D].Search(k, e); } ChainHashTable<E, K>& Insert(const K& k, E& e){ ht[k%D].DistinctInsert(k, e); return *this; } ChainHashTable<E, K>& Delete(const K& k, E& e){ ht[k%D].Delete(k, e); return *this; } void Output(std::ostream&) const; };
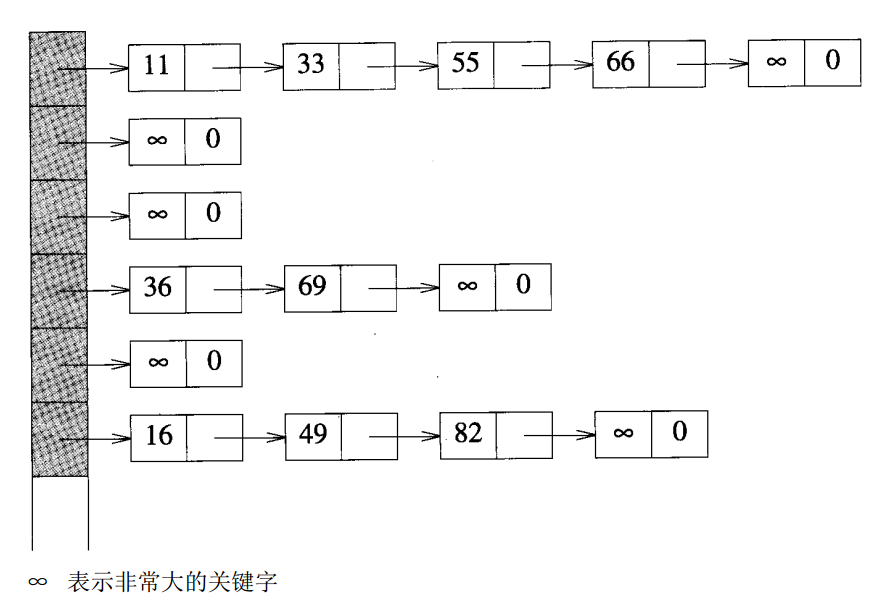
一种改进方法是在每条链表中添加一个尾节点,尾节点中的关键字值最起码要比散列中所有元素的关键字值都大。如下图所示。在实际实现的过程中,所有的链表可以共用同一个尾节点。
线性开型寻址与链表散列的比较
将线性开型寻址与没有尾节点的链表散列进行比较。令s为每个元素需占用的空间(以字节为单位),每个指针和每个整数类型的变量各占用2个字节空间。同时,设散列表中有b个桶和n个元素。首先注意到使用线性开型寻址时有$n /le b$,而使用链表散列则是n可能大于b。
采用线性开型寻址所需要的空间为$b(s+2)$个字节,其中s为每个元素所占用的字节数。而使用链表所需要的空间为$2b+2n+ns$字节,当$n /lt /frac{bs}{s+2}$时,链表所用的空间要比开型寻址少。
在最坏情况下,两种方法进行搜索,都需要搜索所有的n个元素。链表散列的平均搜索次数,其一次不成功搜索和一次成功搜索的平均搜索的桶数如下公式所示:
$$
U_n /sim /frac{/alpha+1}{2},/alpha /ge 1 /
S_n /sim 1+/frac{/alpha}{2}
$$
将线性开型寻址的公式与链表散列的公式相比较,可以看到使用链表时的平均性能要优于使用线性开型寻址。例如,当$/alpha = 0.9$时,链表散列的一次不成功搜索,平均需要检查0.95个元素,一次成功搜索需要检查1.45个元素。而对于线性开型寻址,则是分别为50.5个5.5个元素。
散列与跳表比较
散列与跳表均使用了随机过程来提高字典操作的性能。 使用跳表时,插入操作用随机过程来决定一个元素的级数。 这种级数分配不需要考虑插入元素的值。 在散列中,当对不同元素进行插入时,散列函数随机地位不同元素分配桶,但散列函数需要使用元素的值。
通过使用随机过程,跳表和散列操作的平均复杂性分别为对数时间和常数时间。跳表的最坏时间复杂性为$(n+ MaxLevel)$,而散列的最坏时间复杂性为$/theta(n)$ 。跳表中指针平均占用的空间约为$Maxlevel+/frac{n}{1-p}$,在最坏情况下可能相当大。链表散列的指针所占用的空间为$D+n$。
不过,跳表比散列更灵活。例如,只需简单地沿着0级链就可以在线性时间内按升序输出所有的元素。而采用链表散列时,需要$/theta(D+n)$时间去收集n个元素并且需要$O(nlogn)$时间进行排序,之后才能输出。对于其他的操作,如查找或删除最大或最小元素,散列可能要花费更多的时间(仅考虑平均复杂性)。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

