LinkedIn开源软件项目数量已经超过了100个
社交网络巨头、开源社区的活跃贡献者LinkedIn最近又开源了一系列重量级基础设施软件。到目前为止,LinkedIn在 GitHub 上开源的软件项目数量已经超过了100个。
最近宣布开源的项目有 URL-Detector 、 Rocket Data 和 LayoutKit 等。
URL-Detector
URL-Detector是一个以文本方式检测和标准化URL的Java库。为了保证用户的安全使用,所有用户提交的内容都会经过安全检测。LinkeIn的内容验证服务每秒钟都要处理几十万个URL,检查其中是否有恶意软件或钓鱼软件。LinkdedIn的高级软件工程师Tzu-Han Jan 说 :
如果提交的内容是一个URL,我们就直接用我们的内容验证服务去检查。如果提交上来的是一大堆文本,那就先用URL-Dector算法把可能的URL从中提取出来,再把URL交给内容验证服务。
他们设计了一个有限状态自动机来从文本中提取URL。有限状态自动机是一个包含了若干状态的系统,每个状态可能根据不同的输入而转入几个可能的其他状态。在URL-Detector中的输入就是当前正在解析的字符。
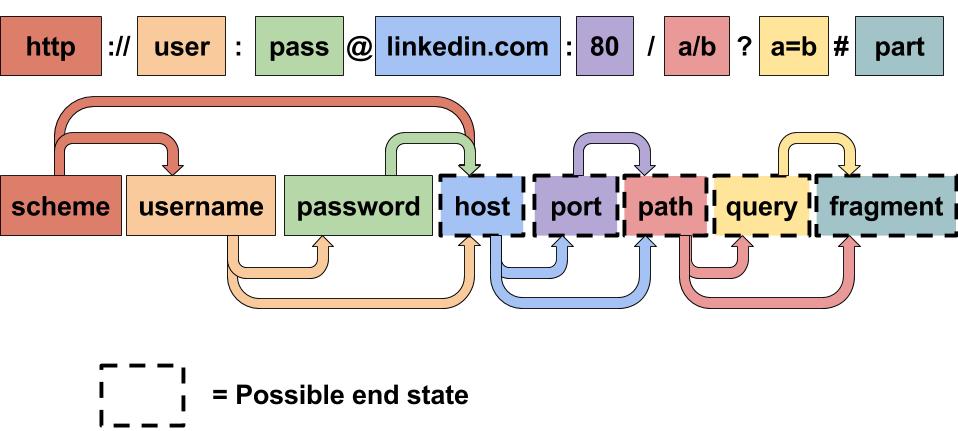
URL-Detector可以辨别出如下任意形式的URL:
- HTML 5 Scheme – //www.linkedin.com
- Usernames – user:pass@linkedin.com
- Email – fred@linkedin.com IPv4
- Address – 192.168.1.1/hello.html
- IPv4 Octets – 0x00.0x00.0x00.0x00
- IPv4 Decimal – http://123123123123/
- IPv6 Address – ftp://[::]/hello
- IPv4-mapped IPv6 Address –
http://[fe30:4:3:0:192.3.2.1]/
它还可以直接解析出关键字,以 http://user@example.com:39000/hello?boo=ff#frag 为例:
- Scheme – "http"
- Username – "user"
- Password – null
- Host – "example.com"
- Port – 39000
- Path – "/hello"
- Query – "?boo=ff"
- Fragment – "#frag"
Rocket Data
Rocket Data是有持续同步层的非阻塞、不可变模型管理系统。它可以使用任何类型的缓存,可以使用简单的API来轻松地挂接到键值型存储上。
从2015年早期重写LinkedIn旗舰版应用时开始,他们就在寻找一个可用的缓存系统来把内容展现给用户,而内容要从网络上加载。总的来说对这套缓存系统的需求是:
- 不可变,线程安全模型;
- 模型在内存和缓存中一致。这样在更新模型之后,所有其它实例中的这个模型都会跟着更新;
- 读写操作都是非阻塞式的;
- 简单的数据淘汰策略;
- 在有大量模型类型、模式和监听器时可以容易扩展;
- 自动迁移;
他们调查了当时业界的各种现有解决方案,包括 Core Data 、 URL Cache 、 Realm ,以及 直接将模型写入磁盘的方案 等,但找不到哪种方案可以满足上述所有需求,或者保证不可变模型的一致性——这是他们最看重的。于是他们决定自己写一套,就是Rocket Data,它的架构如下:
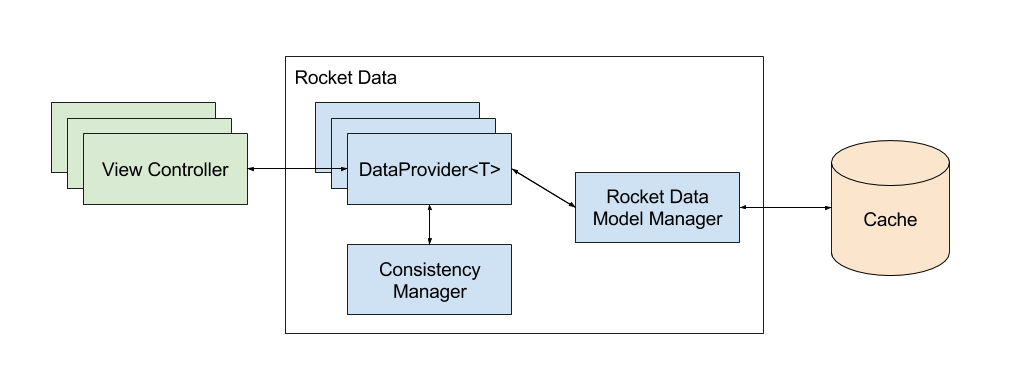
每一个视图控制器都有一个或多个数据提供者的引用。有两种类型的数据提供者:正规数据提供者持有对单一模型的引用,集合数据提供者持有对模型的有序数组的引用。两种数据提供者都可以很容易很快速地完成数据存取,因为模型都保存在内存中。
Peter Livesey这样 评价 这套系统:
有了这套缓存系统,开发者只需一点点额外工作就可以轻松地为项目添加缓存了。缓存和数据提供者都是自动保持一致的。除了每周为一些模型添加模式之外,我们再也不必为迁移增加任何代码。最重要的最,我们程序从来不会因为Core Data异常而崩溃。
LayoutKit
LayoutKit是一个高性能的iOS应用视图布局库。
LinkedIn非常在意手机应用的性能,可第一版的手机应用性能却非常不尽人意,调查后发现原因是主线程在运行Auto Layout时花费了过多时间。Auto Layout是iOS提供的布局引擎,可以自动计算视图在屏幕上的大小和位置。
据LayoutKit的开发者之一Nick Snyder 说 ,他们当初也做了许多尝试。他们试过手工写布局代码,但发现这样会非常难以维护。所以总之需要的是在保证性能的前提下,将布局功能封装起来的可重用模块。可是调查了现有方案之后,仍是发现虽然Auto Layout给大家造成了很大困扰,但合适的方案还是找不到,于是决定自主开发。与Auto Layout相比,LayoutKit的主要优点有:
- 速度快:性能可以与专门写的定制的布局代码相媲美,比Auto Layout快非常多;
- 异步:在后台线程中做布局运算,所以不会干扰与用户的交互;
- 声明性的:用不可变的数据结构声明布局,这样更容易开发、审核、调试和维护布局代码;
- 可缓存的:布局结果都是不可变的数据结构,所以可以在后台线程中计算并缓存,可以非常大的提升性能;
而且LayoutKit还很好用:
- UIKit友好:LayoutKit生成UIView,也提供适配器来方便与UITableView和UICollectionView一起使用;
- 国际化:可以自动为从右到左的语言调整视图;
- Swift:可以在Swift应用中使用;
- 成熟:单元测试覆盖率超过90%,已经用于最新版的LinkedIn iOS应用;
LayoutKit比Auto Layout快八倍,性能可以与专门写的定制的布局代码相媲美。它快在专用的布局算法,而且它也不会为布局创建它并不需要的UIView。所以开发者可以用它随意的去组合布局,再也不用担心性能问题了。

结束语
开源运动如火如茶,其中LinkedIn、Google、Twitter等巨头公司的贡献和推动功不可没。至今LinedIn已经为开源社区贡献了100多个项目和数十万行代码,包括Kafka这样重量级的高吞吐量分布式消息系统。LinkedIn首席工程师Jay Kreps说LinedIn会持续投身开源运动:
- 开源有助于产品保持高标准并引发人们的关注;
- “让任何事情都成为秘密武器并不是我们热衷的有效战略,内部的(工具和技术)信息并不需要成为我们的竞争优势”。
- 坚持开源策略是最好的技术招聘广告。很多LinkedIn招聘到的人都说这是他们加盟的重要原因。
感谢李建盛对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

