Spark Streaming从读源码到放弃
这篇文章来自于被 Spark Streaming 虐了2个月的我在拜读源码的过程中归纳出来的 Spark Streaming 中的知识, 尝试给大家解释一下 Spark Streaming 的在运行中实际发生了什么事情, 以助于 tunning 时不受制于框架的层层封装. 最佳的阅读方式是配合着 Spark Streaming 的源代码一起读, 因此我尽量加上了源代码的跳转:)
当然面向的是曾经用过 Spark Streaming 的读者, 如果大家没有用过, 我会尝试简单说明一下什么是Spark Streaming.
总的来说这次介绍 Spark Streaming 分为5个部分, 按照运行时发生的顺序, 分为如下:
- DAG 的生成
- 在 Driver 上启动 Streaming, 分发 Receiver
- 在 Executor 上启动 Receiver Job
- 数据流转
- 定时 Batch Job
为了更好的说明, 我将以 github 上 spark 项目的 kafka spark streaming 的 wordcount 作为例子.
三句话介绍什么是 Spark Streaming
最佳的解释当然是 官方文档 , 简而言之, 归结下面两张图. 
Spark Streaming 就是一个不断从数据源中接收数据, 经过处理后输出到别的地方的一个流式处理框架. 在处理的过程中可以用到 Spark 的分布式内存计算的特性.
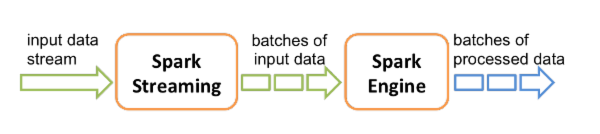
在流式处理中, Spark Streaming 将接收到的数据按照间隔时间(batch interval)分隔成一个个 batch, 以 batch 为单位处理数据, 以batch为单位输出.
文章中提到的几个基本概念
Batch Job
Spark Streaming 中, 根据时间间隔(batch interval)分成一个个 batch. 根据执行的操作, 一个 batch 对应1到多个 Batch Job. 因此在 Streaming 运行过程中会每隔一段时间向 Spark 提交1到多个 Job. Spark 以 Job 作为任务的基本单位, 进行 Scheduling 和计算.
Receiver Job
若使用到 Receiver-based 的数据输入源, 在 Streaming 运行中会生成一直不间断运行的 Receiver Job, 此 Job 在某一 Executor 上创建 Receiver 后就一直不断接收数据.
Job/Stage/Task
一个 Job 实际上包含了一系列的操作, 如 textFile.map(func1).map(func2).reduceByKey(func3).forEach(func4) , 本质上是一个有向无环图(DAG), 也可以理解为一个链. Spark 会根据实际进行的操作, 将 Job 分成一或多个 Stage, 并且顺序依次执行.
在运行过程中, Spark 会根据 RDD 中的 partition 情况将每个 stage 分成多个 Task, 一般来说 RDD 有多少个 partition, 一个 stage 就有多少个 Task. Task 是 Executor 执行计算的任务执行单元.
DAG的生成
图论中,如果一个有向图无法从任意顶点出发经过若干条边回到该点,则这个图是一个有向无环图(DAG图)。Spark streaming 使用 DAG 来描述程序的行为.

在有过 Spark 使用经验的同学看来, DAG 应该不陌生. 在 Spark 的 Web UI 上, 会使用 DAG 来展现每个 Job 的过程. 如我从当前线上程序中截出来的一张 DAG:
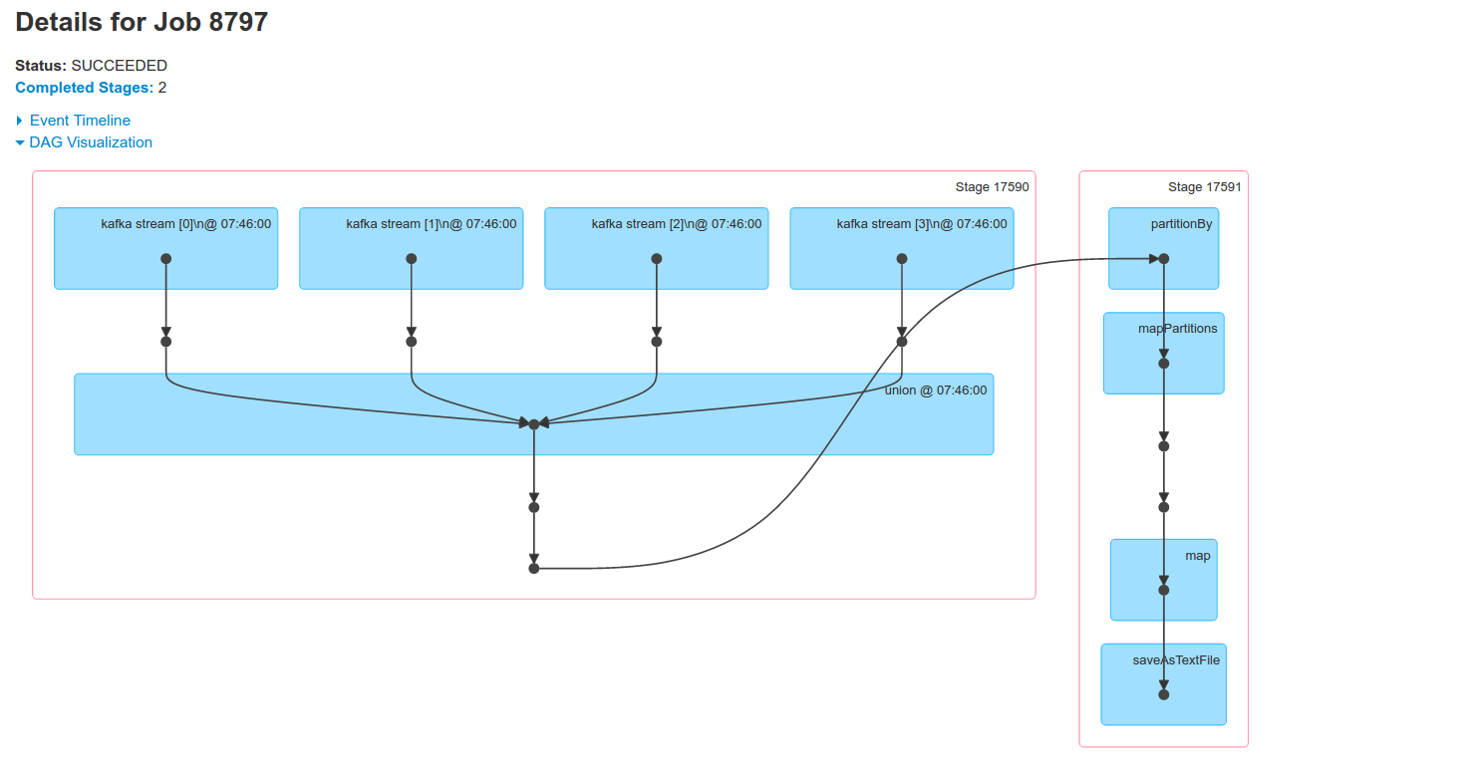
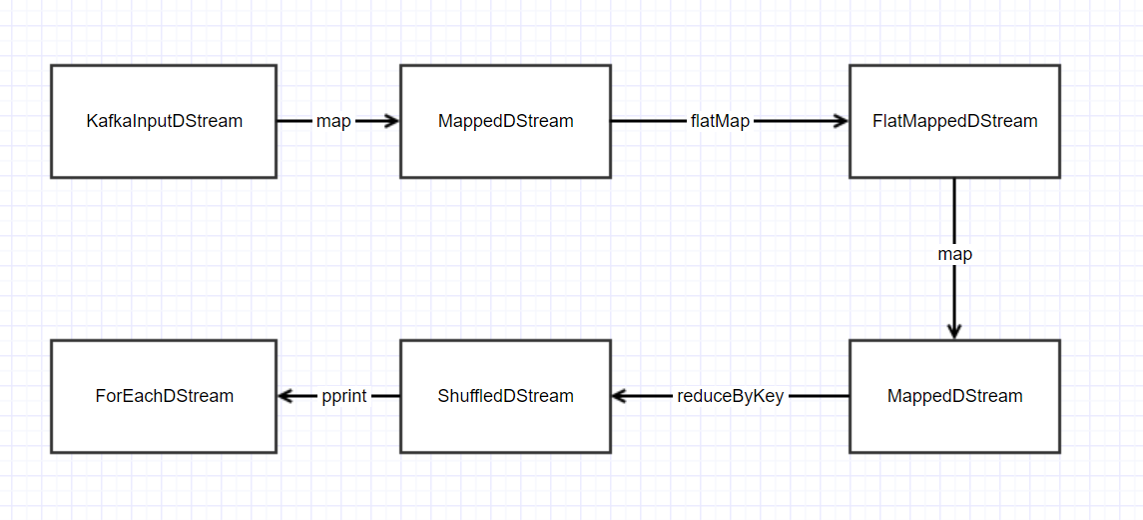
回到我们的 wordcount 例子, 在 ssc.start() 之前, 将会生成如下的 DAG
if __name__ == "__main__": sc = SparkContext(appName="PythonStreamingKafkaWordCount") ssc = StreamingContext(sc, 1) zkQuorum, topic = sys.argv[1:] kvs = KafkaUtils.createStream(ssc, zkQuorum, "spark-streaming-consumer", {topic: 1}) lines = kvs.map(lambda x: x[1]) counts = lines.flatMap(lambda line: line.split(" ")) / .map(lambda word: (word, 1)) / .reduceByKey(lambda a, b: a+b) counts.pprint() ssc.start() ssc.awaitTermination()
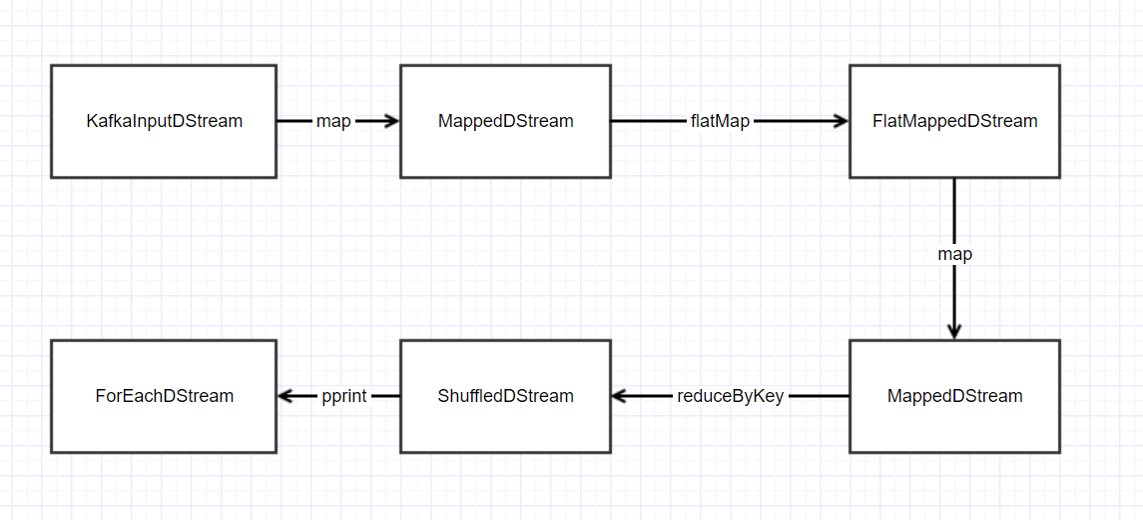
让我们来一个个地看, 按照顺序如下:
createStream() map() flatMap() map() reduceByKey() pprint()
在 StreamingContext 中, 使用 DStreamGraph 来表示 DAG, 其中有两个属性, inputStreams 和 outputStreams.
private val inputStreams = new ArrayBuffer[InputDStream[_]]() private val outputStreams = new ArrayBuffer[DStream[_]]()
inputStreams 用于记录数据的输入源, 在 createStream 时添加. 在此例中只有一个: KafkaInputDStream.
outputStreams 记录整个依赖链, 在生成 outputStream 时添加, 生成 Batch Job 时使用, 定义 Batch Job 的行为, 在此例中只有一个: ForEachDStream.
自此, 在启动 Streaming 之前, 有了一份完整的描述整个 Streaming的DAG.
在 Driver 上启动 Streaming 并分发 Receiver
从调用 ssc.start() 开始, Streaming 就开始启动, 调用关系如下:
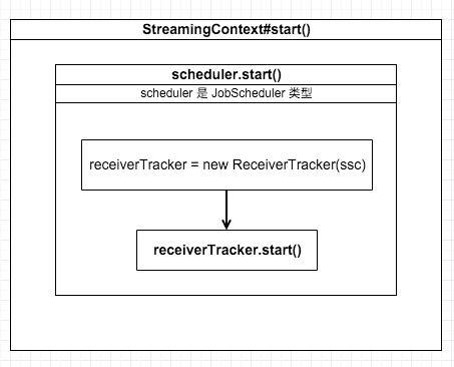
StreamingContext 中有一个成员 JobScheduler , 负责协调每个 batch job, 包括其生成和运行. scheduler.start()将创建一个 ReceiverTracker , 负责跟踪每个 Receiver 的状态.
按照顺序, ReceiverTracker.start() 干了以下的一些事情:
- 初始化 ReceiverTracker 中的 ReceiverTrackerEndpoint, 接收和处理来自 ReceiverTracker 和各个机器上的 Receiver 发来的消息.
- 从 DAG 的 inputStreams 中找到需要 Receiver 的 inputDStream, 取出它们的 Receiver
- runDummySparkJob 这也是为什么我们启动 Streaming 后在 Web UI 上看到分成一个70个 task 的 job 会先运行的原因.
- 往 ReceiverTrackerEndpoint 发送 StartAllReceivers 的消息, 开始分发 Receiver
4.1 ReceiverSchedulingPolicy .scheduleReceivers() 决定每个 receiver 分配到哪个机器上的哪个Executor上, 默认会均匀分配到各个机器.
4.2ReceiverTracker.startReceiver()生成 Receiver 的 RDD 和 jobFunc(jobFunc 用于在Executor 上启动此 Receiver), 并打包成一个 Job
4.3ssc.sparkContext.submitJob()提交 Job, 开始在 Executor 上跑
在 Executor 上启动 Receiver Job
Driver 上提交了 Receiver Job 之后, 分发到 Executor 上执行
- 初始化一个 ReceiverSupervisor 负责跟踪这个 Receiver
-
ReceiverSupervisor.start()启动 Receiver - Receiver 根据传入的 topics 字段, 新建 N 个线程(在 topics 的字典中, 每个 topic 的数字含义为: 对此 topic 开多少个线程进行消息消费), 开始接收数据.
-
ReceiverSupervisor.awaitTermination()阻塞这个 Job, 使各个 Receiver 线程源源不断地接收数据.
自此, Streaming 开始源源不断地运行, 不断地接收数据, 数据开始在系统中流转.
数据流转
在 Spark Streaming 中, 数据流转过程基本上包括了 Receiver 接收数据, 数据结构化以及数据持久化, 数据定时分配给 Batch, Batch Job 定时处理数据, 垃圾数据回收 . 下面列出了一张包含此过程的超级复杂的图......
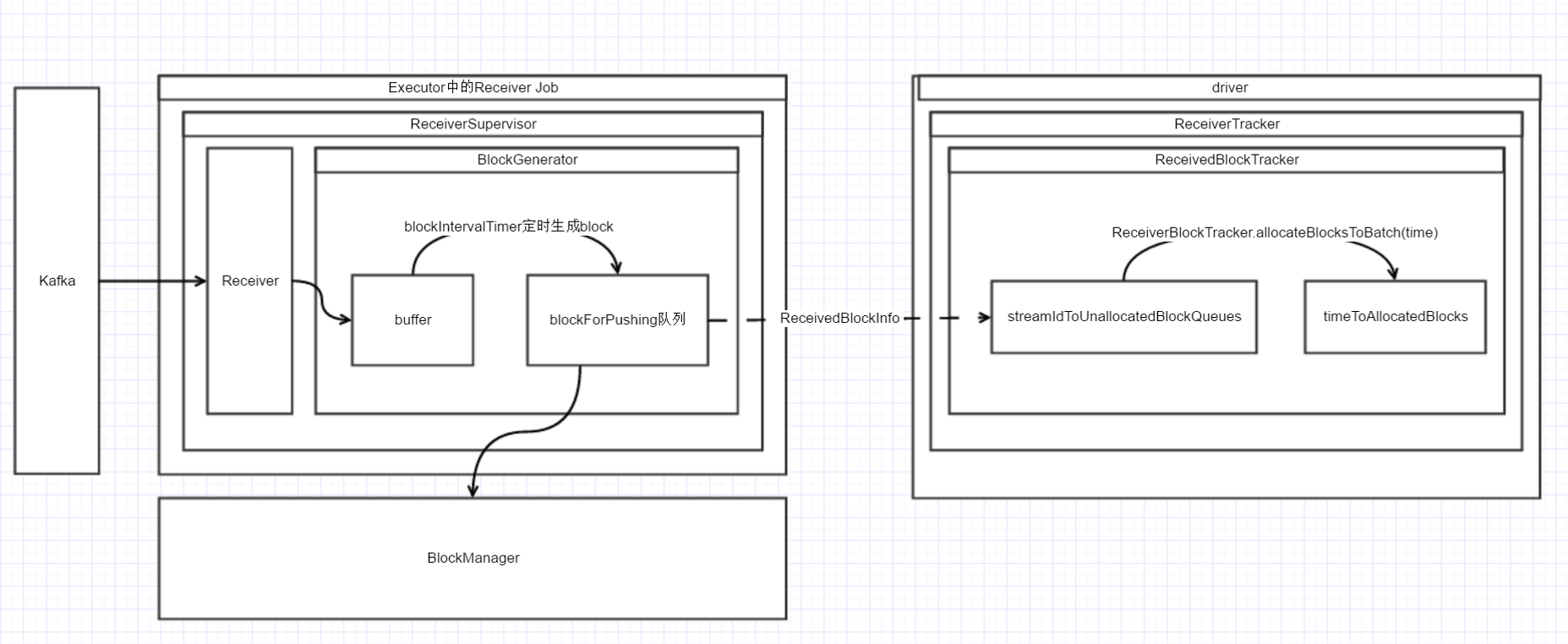
让我们分开了一个个部分地看.
左边是在 Executor 上接收数据的过程由多个线程并行完成此过程, 逻辑如下 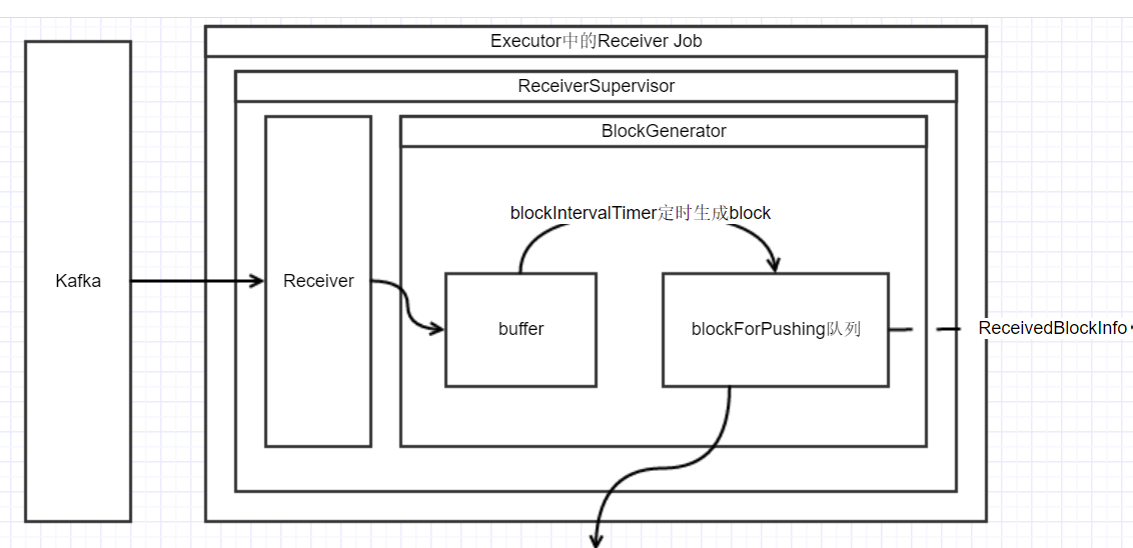
Receiver线程接收数据
- Receiver 不断地从 Kafka 接收数据(while循环中), 并且调用 Receiver.store()
- store 方法会调用
ReceiverSupervisor.pushSingle(), pushSingle 方法调用了 RateLimiter.waitToPush() 阻塞此操作, 直到接收速率满足了 maxRate 的配置要求 - 调用 BlockGenerator .addData() 将接收的消息添加到 BlockGenerator 的 buffer 中 (BlockGenerator 为 ReceiverSupervisor 的一个成员, 后续会继续说到)
BlockGenerator.blockIntervalTimer 线程生成 Block
此线程为一个定时器, 每隔一段时间(spark.streaming.blockInterval)进行一次操作, 逻辑如下:
- 获取新的全局唯一的 blockId
- 将buffer中的数据全部取出来, 组装成 Block, put 到 BlockGenerator.blockForPushing 队列中, 此队列是阻塞队列, 如果这个队列满了, 则阻塞这个线程的 put 操作.
BlockGenerator.blockPushingThread 线程
此线程不断地(在一个while循环中)把上一线程生成的 Block 存储并通知 driver, 逻辑如下:
-
blockForPushing.poll()取出来一个 Block - 调用
ReceiverSupervisor.pushAndReportBlock()看方法名就知道其作用 - 生成一个 ReceivedBlockInfo 的实例, 封装了新接收的Block的信息. 调用并且发送AddBlock(ReceivedBlockInfo)消息到 Driver 上的 ReceiverTrackerEndpoint. 告诉 ReceiverTracker 这个 InputDStream (用 streamId 标识)有新的 Block, 这个 Block 有多少条消息, 在哪个机器上等等信息.
- 将这个 Block 存到 BlockManager 中. (根据设定的 StorageLevel, 决定存多少份/序列化方法/存在内存OR磁盘)
在Driver上
在上一条线程的第3步中, 处理发过来的 AddBlock(ReceivedBlockInfo) 的消息.
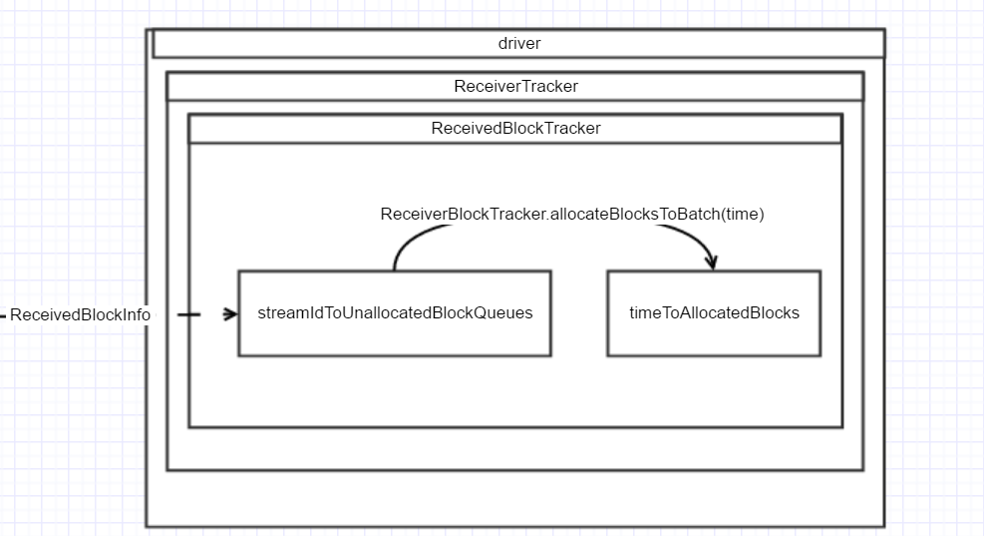
消息被接收后, 将会调用 ReceiverTracker.ReceiverBlockTracker.addBlock() , 此方法将 ReceivedBlockInfo 添加到 ReceivedBlockTracker.streamIdToUnallocatedBlockQueues 中. Key 为streamId, Value 为已存储但未分配的 Block 队列. 定时生成 Batch Job 时, 将访问这个结构来获取每个 InputDStream 对应的未处理的 Block.
定时的Batch Job
Spark Streaming 的定时分 Batch 处理接收的数据就是由这一部分来实现. 实际的逻辑非常简单.
在 Driver 的 StreamingContext 的一个成员 JobGenerator 中有这样一个定时器
private val timer = new RecurringTimer(clock, ssc.graph.batchDuration.milliseconds, longTime => eventLoop.post(GenerateJobs(new Time(longTime))), "JobGenerator")
这个定时器简而言之干了一件事情, 每隔一个 batchDuration 调用 JobGenerator.generateJobs() , 此方法逻辑如下: ! 
将已经接收到的 blocks 分配给 batch
方法 ReceiverBlockTracker.allocateBlocksToBatch(time) 将 streamIdToUnallocatedBlockQueues 中的 block 拿出来转换成 Key 为 streamId, Value为ReceivedBlockInfo 数组的 Map, 放到 timeToAllocatedBlocks, 决定此 batch 包含哪些 block
private val streamIdToUnallocatedBlockQueues = new mutable.HashMap[Int, ReceivedBlockQueue] private val timeToAllocatedBlocks = new mutable.HashMap[Time, AllocatedBlocks]
生成 Batch Job 并提交
还记得之前提到的 DAG 吗? 生成 DAG 的时候, 用 DStreamingGraph.outputStreams 记录依赖链
生成 Job 的时候, 对每个 outputStream, 调用 outputStream.generateJobs() 方法, 生成对应的 RDD 和 jobFunc
def generateJobs(time: Time): Seq[Job] = { logDebug("Generating jobs for time " + time) val jobs = this.synchronized { outputStreams.flatMap { outputStream => val jobOption = outputStream.generateJob(time) jobOption.foreach(_.setCallSite(outputStream.creationSite)) jobOption } } logDebug("Generated " + jobs.length + " jobs for time " + time) jobs }
之后, 生成此 Batch 的相关信息用于监控, 再调用 JobScheduler.submitJobSet(JobSet(time, jobs, streamIdToInputInfos))
完成后清除 Block
完成此 Batch Job 后, 会往 JobScheduler.eventLoop 发送 clearMetaData 的事件, 让 eventLoop 线程调用 BlockManager 清除此 batch 对应的所有 Block.
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

