运维的角度看微服务和容器
单体应用 VS 微服务
让我们先从运维的真实场景出发,来看一下单体应用存在的问题。这里先分享两个真实的生产案例。
案例一是某核心业务系统,所有的业务逻辑代码都打包在同一个 WAR 包里部署,运行了将近几百个同构的实例在虚拟机上。某次因为应用包中的一个功能模块出现异常,导致实例挂起,整个应用都不能用了。因为它是一个单体,所以尽管有几百个实例在运行,但是这几百个实例都是异常的。业务系统是经过多年建设起来的,排查起来也很复杂,最终整个业务系统瘫痪了近六个小时才恢复。同时,因为有多个前台系统也调用了这个后台系统,导致所有要调用的前台系统也都全部瘫痪了。设想一下,如果这个场景使用的是微服务架构,每个微服务都是独立部署的,那影响的也只是有异常的微服务和其他相关联的服务,而不会导致整个业务系统都不能使用。
另外的案例是一个客服系统,这个系统有一个特点,早上八点的时候会有大量的客服登录。这个登录点是全天中业务并发量最高的时间点,登录时系统需要读取一些客户信息,加载到内存。后来一到早上客服登录时,系统经常出现内存溢出,进而导致整个客服系统都用不了。当时系统应对这种场景做架构冗余时,并不是根据单独的业务按需进行扩展,而是按照单体应用的长板进行冗余。比如说早上八点并发量最高,单点登陆模块业务需求非常大,为适应这个时间点这个模块的业务压力,系统会由原来的八个实例扩展到十六个实例,这时的扩展是基于整个系统的。但事实上,在其他时间段,这个单点登陆模块基本不使用,且监控的数据显示,主机的资源使用情况基本在 40% 以下,造成了很大的资源浪费。所以在一个大型的业务系统中,每个服务的并发压力不一样,如果都按压力最大的模块进行整体扩展,就会造成资源的浪费,而在微服务的模式下,每个服务都是按自身压力进行扩展的,就可以有效的提高资源利用率。
从这两个例子中,我们可以看出,单体应用存在如下两个问题:一个是横向扩展时需要整体扩展,资源分配最大化,不能按需扩展和分配资源;另一个是如果单体中有一个业务模块出现问题,就会是全局性灾难,因为所有业务跑在同一个实例中,发生异常时不具备故障隔离性,会影响整个业务系统,整个入口都会存在问题。
因此,我们当时考虑把综合业务拆分,进行更好的资源分配和故障隔离。
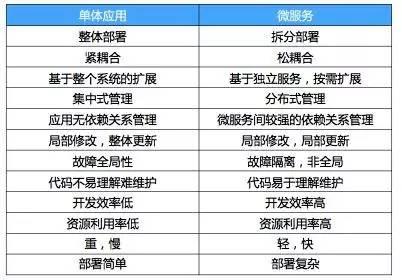
下面我们看一下单体应用和微服务的对比,如图 1 所示。这里从微服务带来的好处和额外的复杂性来讲。
微服务的好处:
局部修改,局部更新。当运维对一个单体应用进行修改时,可能要先把整个包给停了,然后再去修改,而微服务只需逐步修改和更新即可。
故障隔离,非全局。单体应用是跑在一起,所以只要一个模块有问题,其他就都会有问题。而微服务的故障隔离性、业务可持续性都非常高。
资源利用率高。单体应用的资源利用率低,而使用微服务,可以按需分配资源,资源利用率会非常高。
微服务带来的复杂性:
微服务间较强的依赖关系管理。以前单体应用是跑在一起,无依赖关系管理,如果拆成微服务依赖关系该如何处理,比如说某个微服务更新了会不会对整个系统造成影响。
部署复杂。单体应用是集中式的,就一个单体跑在一起,部署和管理的时候非常简单,而微服务是一个网状分布的,有很多服务需要维护和管理,对它进行部署和维护的时候则比较复杂。
如何更好地利用资源。单体应用在资源分配时是整体分配,扩展时也是整体扩展,数量可控,而在使用微服务的情况下,需要为每一个微服务按需分配资源,那么该为每个微服务分配多少资源,启动多少个实例呢,这也是非常大的问题。
监控管理难。以前我们用 Java ,就是一个单体应用,监控和管理非常简单,因为它就是一个 1 ,但是使用微服务它就是 N 个,监控管理变得非常复杂。另外是微服务之间还有一个协作的问题。
基于容器构建微服务架构
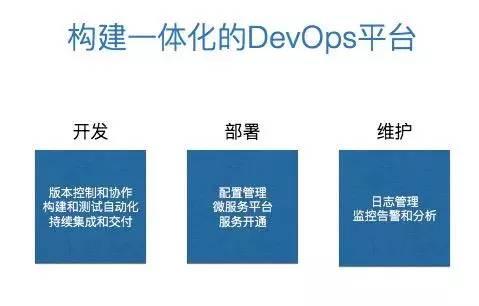
容器的出现给微服务提供了一个完美的环境,因为我们可以:
基于容器做标准化构建和持续集成、持续交付等。
基于标准工具对部署在微服务里面的容器做服务发现和管理。
透过容器的编排工具对容器进行自动化的伸缩管理、自动化的运维管理。
所以说,容器的出现和微服务的发展是非常相关的,它们共同发展,形成了一个非常好的生态圈。下面详细讲下 DevOps 的各个模块。
持续集成与持续发布
持续集成的关键是完全的自动化,读取源代码、编译、连接、测试,整个创建过程自动完成。我们来看一下如何用 Docker , Maven , Jenkins 完成持续集成。
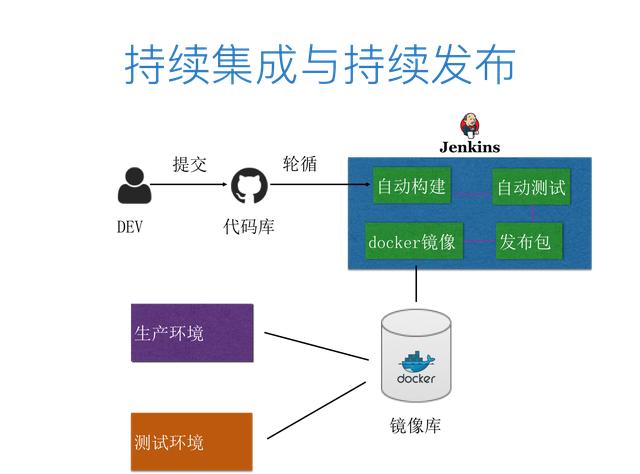
如图 3 所示。首先是开发人员把程序代码更新后上传到 Git ,然后其他的事情都将由 Jenkins 自动完成。那 Jenkins 这边发生什么了呢?Git 在接收到用户更新的代码后,会把消息和任务传递给 Jenkins ,然后 Jenkins 会自动构建一个任务,下载 Maven 相关的软件包。下载完成后,就开始利用 Maven Build 新的项目包,然后重建 Maven 容器,构建新的 Image 并 Push 到 Docker 私有库中。然后删除正在运行的 Docker 容器,再基于新的镜像重新把 Docker 容器拉起来,自动完成集成测试。整个过程都是自动的,这样就简化了原本复杂的集成工作,一天可以集成一次,甚至是多次。
依赖关系管理

典型的微服务架构
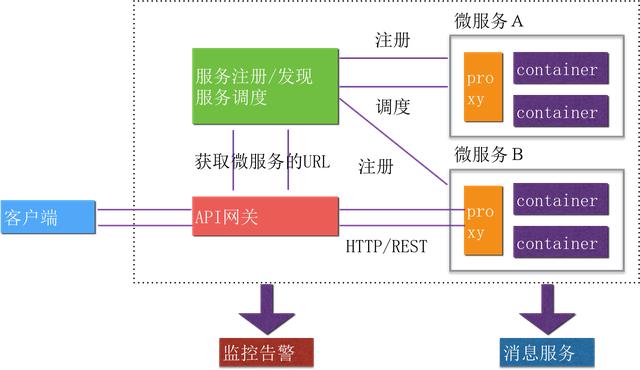
服务发现与负载均衡

日志集中式管理
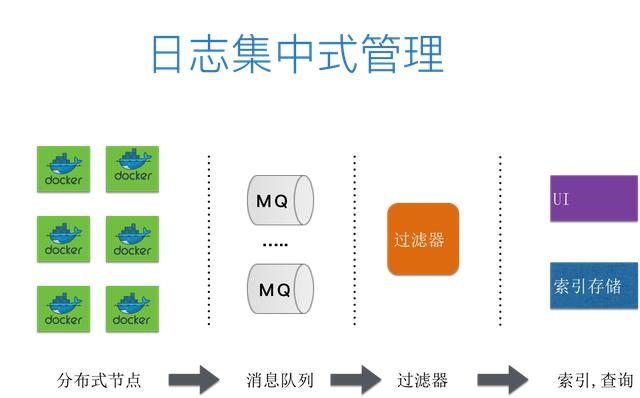
以前单体的情况下,单体的数量少,日志数量也相应比较少,而在微服务架构下,因为拆分成了很多微服务,相应的日志会非常多且散,这种情况下需要对日志进行集中的管理。我们可以在每个容器里跑日志监控,把所有日志采集进行集中管理和存储,再通过简易操作的 UI 界面进行索引和查询。
监控管理

然后就是监控方面了。微服务的量是非常大的,这个时候如何有效地监控是极其重要的。我们刚开始做监控的时候,有几百个实例对同一个关键字进行监控,出故障后会收到几百条短信,因为每一个实例都会发一条短信。这时候严重的致命性的报警就会看不到,因为手机信息已经爆炸了,所以要对报警进行分级,精确告警,最重要的是尽量让故障在发生之前灭亡。因此,在做监控时要对故障提前进行判断,先自动化处理,再看是否需要人为处理,然后通过人为的干预,有效的把故障在发生之前进行灭亡。
但如果所有事情都靠人为去处理,这个量也是非常大的,所以对故障进行自动化隔离和自动化处理也很重要。我们在写自动化故障处理的时候研究了很多常见的故障,写了很多算法去判断,精确到所有的故障,这样基本的常见的故障和可以策划处理的故障都可以自动化处理掉。之前没有出现的故障,出现之后我们就会去研究是否可以做成自动化处理。如果生产上做的不精确,对生产会是灾难性的,所以我们对生产的故障自动化处理也做了很多研究。
七牛的微服务架构实践
前面讲了很多运维,下面来了解一下 Docker 和微服务在七牛云中的实践,以七牛的文件处理服务架构演变为例。
文件处理服务是指,用户把原图存到七牛的云存储之后,然后使用文件处理服务,就可以把它变成自己想要的服务,比如剪裁、缩放和旋转等,如图 9 。
过去为适应不同的场景,用户需要针对同一图片自行处理后上传所有版本,但如果使用七牛的文件处理服务,则只需提供原图就可以了,其他版本的图片都可以通过七牛进行处理。如图 10 所示,我们把一张原图放进去之后,只需要在原图后面加一个问号和参数,就可以呈现出想要的方式,比如说加水印、旋转、缩放和剪裁。

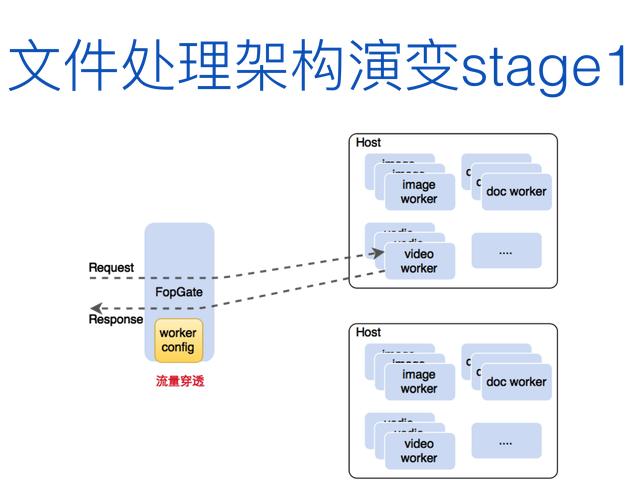
文件处理服务的架构在早期是非常笨拙的, 如图 11 所示。FopGate 是业务的入口,通过 work config 静态配置实际进行计算的各种 worker 集群的信息,里面包含了图片处理、视频处理、文档处理等各种处理实例。集群信息在入口配置中写死了,后端配置变更会很不灵活,因为是静态配置,突发请求情况下,应对可能不及时,且 FopGate 成为流量穿透的组件(业务的指令流与数据流混杂在一起),比如说要读一张图片,这张图片会经过 FopGate 导过来。
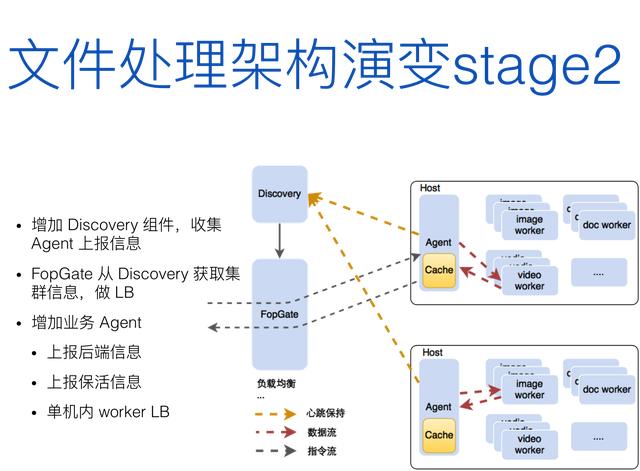
于是,我们自己组建了一个叫 Discovery 的服务,由它进行负载均衡和服务发现,用于集群中 worker 信息的自动发现,每个 worker 被添加进集群都会主动注册自己,FopGate 从 Discovery 获取集群信息,完成对请求的负载均衡。同时在每个计算节点上新增 Agent 组件,用于向 Discovery 组件上报心跳和节点信息,并缓存处理后的结果数据(将数据流从入口分离),另外也负责节点内的请求负载均衡(实例可能会有多个)。此时业务入口只需负责分发指令流,但仍然需要对请求做节点级别的负载均衡。这是第二个阶段,如图 12 。
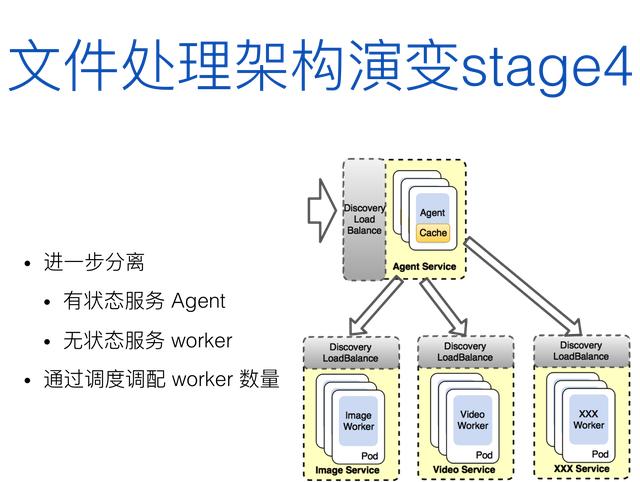
在第三个阶段,我们把文件处理架构迁移到了容器平台上,取消了业务的 Discovery 服务,转由平台自身的服务发现功能。每个 Agent 无需和 Discovery 维护心跳,也不再需要上报节点信息,每个 Agent 对应一个计算 worker,并按工种独立成 Service,比如 Image Service,Video Service,由于后端只有一个 worker ,因此也不需要有节点内的负载均衡逻辑,业务入口无需负载均衡,只需请求容器平台提供的入口地址即可,如图 13 所示。

踩过的那些坑
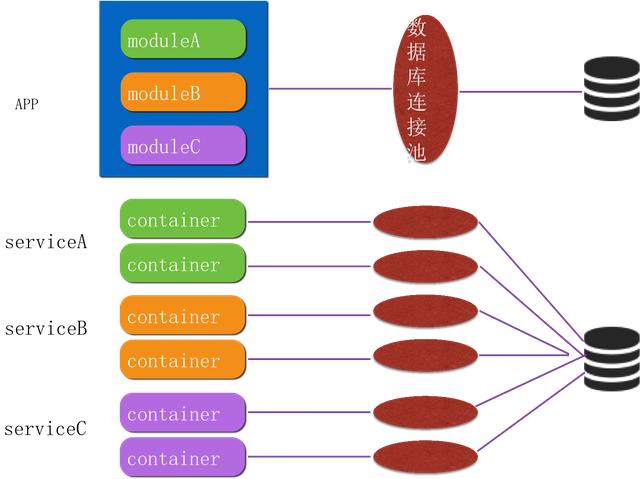
图 15 所示的是单体应用访问后端数据库使用的数据库连接池,连接池里的连接是可以复用的,而单体中所有的业务模块都可以调用同一个池里的连接。这个数据库连接池可以进行动态的伸缩,但它连接到后端数据库的连接是有上限的。拆分成微服务之后,可能每一个微服务都要创建一个数据库连接池,微服务间的数据库连接池并不能共享。当对微服务进行弹性伸缩时,并不知道它会弹性到什么程度,这时就可能会对后端数据库造成连接风暴,比如原本只有五千个长连接,但是由于弹性伸缩(可能根据前台业务情况进行了非常大的伸缩),会对数据库发生连接风暴,对数据库造成非常大的压力。
为了确保不会因某个服务的连接风暴把数据库拖垮,对其他服务造成影响,我们做了一些优化。首先是优化了我们的一些弹性算法,其次是限定了容器弹性伸缩的范围,因为没有限制的伸缩,可能会对后端数据库造成压力。另外一个是降低连接池初始化的大小,比如初始化设定为 10 ,它往数据库里面的长连接就是 100 个,如果设定为 1 ,往数据库里面长连接就只有 10 个 ,如果太多则可能会对数据库造成压力。还有就是数据库端进行一些限定,当连接达到一定数量就进行预警,限制弹性扩展。
单体应用如何改造成微服务?
我在传统企业工作了七八年,我们一直在探讨单体应用如何拆分成微服务。其实对传统企业来讲,他们的单体是非常大的,而且内部的耦合性是非常强的,内部调用非常多。如果我们冒冒失失地将单体拆分成微服务,会占用非常大的网络传输。如果在拆成微服务的时候,没有进行很好的架构设计,拆成微服务并不是享受它带来的好处,而是灾难。所以在拆的时候,比如说前端、后端的拆分、耦合性不是特别强的拆分,我们提倡先跑到容器里面,看一下运维容器的时候有什么坑,然后解决这些坑,然后不断完善。我们可以把耦合性不是那么高的拆成大的块,然后把信息密集型的进行拆分,慢慢拆分成我们理想的架构。这是一个循序渐进的过程,不可一蹴而就。

图 16 是微服务的一些设计准则,例如设计提倡最小化功能,小到不能再小。这时需要每一个服务标准化的提供出来,有一个标准化的接口和其他微服务进行通信。还需要是异步通信,如果是同步会造成堵塞。每个微服务都要有独立的数据存储。此外,服务还需要是无状态的,因为如果有状态,弹性伸缩时可能会有数据丢失,可以用一些其他的方法处理这些有状态的数据。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

