英语流利说基础数据平台

随着大数据产品的日益成熟与稳定,如今不少互联网公司在数据产品所投入的运维工作已经越来越少,另外,加上国内云服务的不断普及,建立一套自己的大数据基础平台的成本也将变的更低。本文将向大家简要介绍流利说是怎样基于 AWS(Amazon Web Services)服务构建自己的大数据平台。
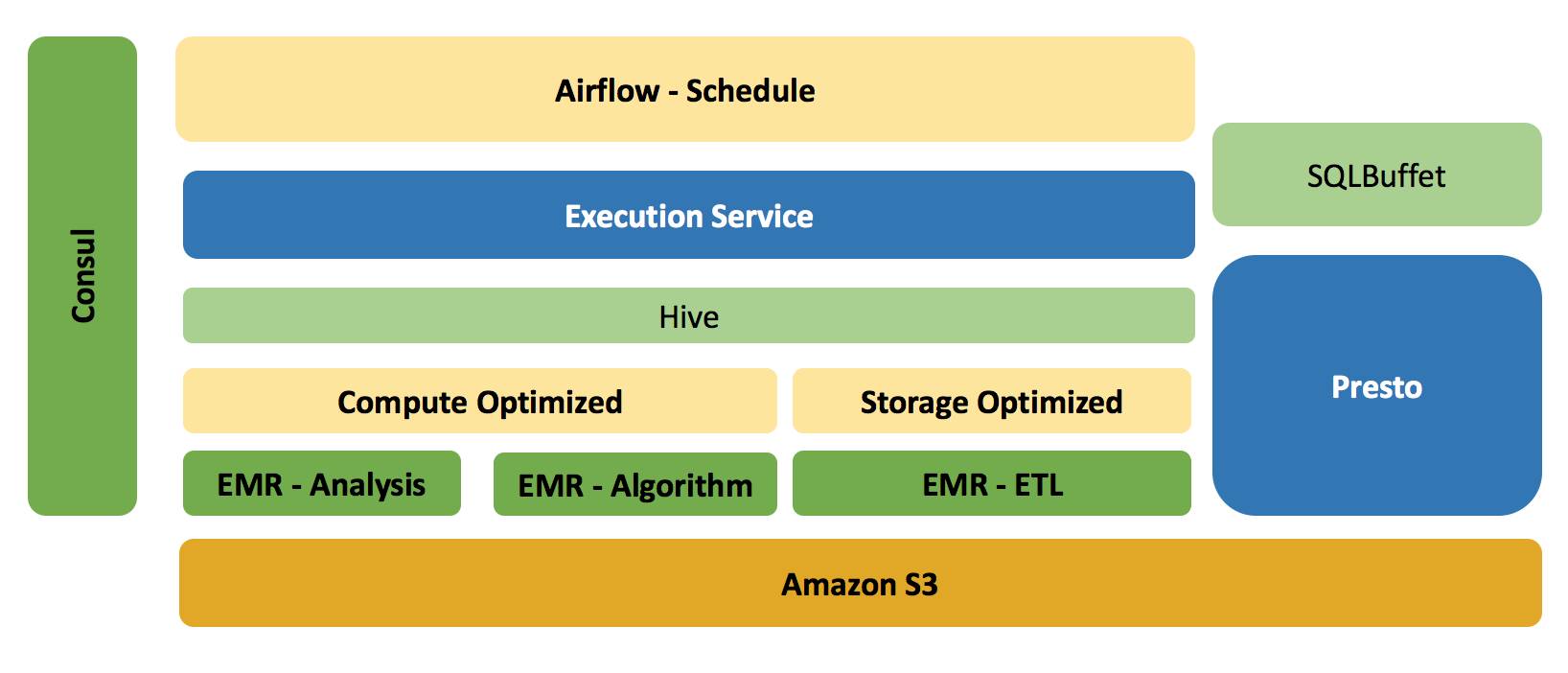
数据平台架构
-
存储系统 - 从 HDFS 到 S3
从架构图中,可以看出,我们选用了 Amazon 的 S3 作为整个平台的存储层,这使得我们在整个平台的任何一处地方都可以很轻松的获取数据,而作为同一类别的产品 Hadoop HDFS,我们对于它的定位,则是辅助 MapReduce / Yarn 的运行,其本身不存储任何 Job 的最终数据。当然我们确实有一段时间,所有的 ETL 数据存储到 HDFS,但后来我们发现其不利于集群的扩展。比如集群在做伸缩性扩展时,DataNode 节点需要退役,移动数据的成本太大,造成扩展集群的时间太长。
而另外一个重要的因素在于,我们基于 S3,在其上构建了数个 EMR(Amazon Elastic MapReduce)集群,而这些集群之间是相互独立的,这样我们可以基于 S3 和 EMR 做到存储层面的共享,而在计算资源层面做到隔离。
-
计算资源 – EMR
Amazon EMR 在于我们可以很方便并快速的构建一个基于 Hadoop,Spark,Hive等大数据产品的计算集群,如果不是需要长久服役,我们可以在其所有 Job 完成之后,销毁集群,而并不影响数据的持久化,因为所有的数据都保存在 S3。事实上,我们每天的 ETL Job 正以 T+1 的方式使用这一类型的集群,当所有 Job 完成之后,调度系统会立即销毁集群(下文会讲到我们是如何管理并使用集群的)。
另外一点,对于集群上的任务,他们的特点可能都不太一样,比如推荐和算法业务可能对集群的计算能力要求较高,而 ETL 类型的任务,可能又对存储或内存要求较高。因此我们在构建集群之前,可以通过指定机型来达到这样的效果,并在后期任务节点上做到伸缩性扩展。
-
服务发布 – Consul
纵向来看,平台的所有节点在启动之初都会向 Consul 注册自己,如果是 EMR 类型的节点,其本身作为一种计算服务, Master 节点会向 Consul 发布一个新的服务, 因此后期我们在向集群提交任务时,实际上并不需要指定集群地址,而只需要告诉 Execution Service(任务与集群管理服务),我需要一个可以作为推荐系统的集群即可。
后面,我们会讲到流利说的 Execution Service ,它是一个 Master/Slave 架构类型的系统,因此单点的 Master 并不能保证HA(高可用性)。事实上该系统在构建之初,也会向 Consul 发布服务,所以调度系统在向 Execution Service 提交任务时,并不需要指定 Master 节点。
-
任务与EMR集群管理系统 - Execution Service
Execution Service(以下称为ES)用来管理EMR集群的创建,扩容,以及销毁,另外还负责每天流利说所有调度任务的提交,执行,以及结果的反馈。 目前ES支持的任务类型包括 Bash,HQL(Hive SQL Script),以及 Spark。所有对集群的操作,以及提交的任务,我们统一维护到 MySQL 中。
-
Airflow
流利说目前所有的 ETL 任务都是通过 Airflow 来调度的,并且 Airflow Task 之间的依赖性可通过 Python 来定义,这使得我们的学习以及维护成本更低。ETL 的基本流程是,我们通过数据同步工具,把数据以 T+1 的方式从 MongoDB / Redis Dump 到 S3,并且在此过程中,同样会把表的结构同步到 S3,然后利用最新的表结构和数据,在 Hive 中建立相对应的库和表。对于原始数据,一般数据最初以 Json 的格式保存到一个名为 raw_data 的库中,在后续的 ETL Job 中,我们会对 raw_data 库中的表进行清洗,计算以及转换,最终数据以 ORC 或是 Parquet 的方式保存到 Prod 的库中。 另外,Airflow的调度同样承担每天集群的构建工作,整个生命周期类似 Start -> CreateCluster -> Jobs submission --> TerminateCluster --> End.
-
数据查询工具 - Presto
Hive 在批处理上表现不错,但在交互式查询上,可能一个很小的查询就需要几十秒甚至数分钟; 因此对于这类查询,我们引入了 Presto,并且其依赖的数据源仍然在 S3 上。我们对Presto 维护了自己的分支,并且开发了 Presto UI 供数据分析人员使用。流利说是一家以数据驱动产品的公司,数据分析师以及产品经理,甚至销售每天会有若干的查询需要立即得到结果。除了基于 Presto,它需要拥有比较友好的UI,以及考虑到人员变动,我们需要做更严格的权限控制。另外,对于大量编写 SQL 的数据分析师,我们在 Sublime 上做了 Presto 插件,这使得在编写脚本时,天然拥有了高亮显示,字符提示等优势,当你完成脚本编写后,可以通过 Command + E 来执行你在 Sublime 中所选择的查询语句。
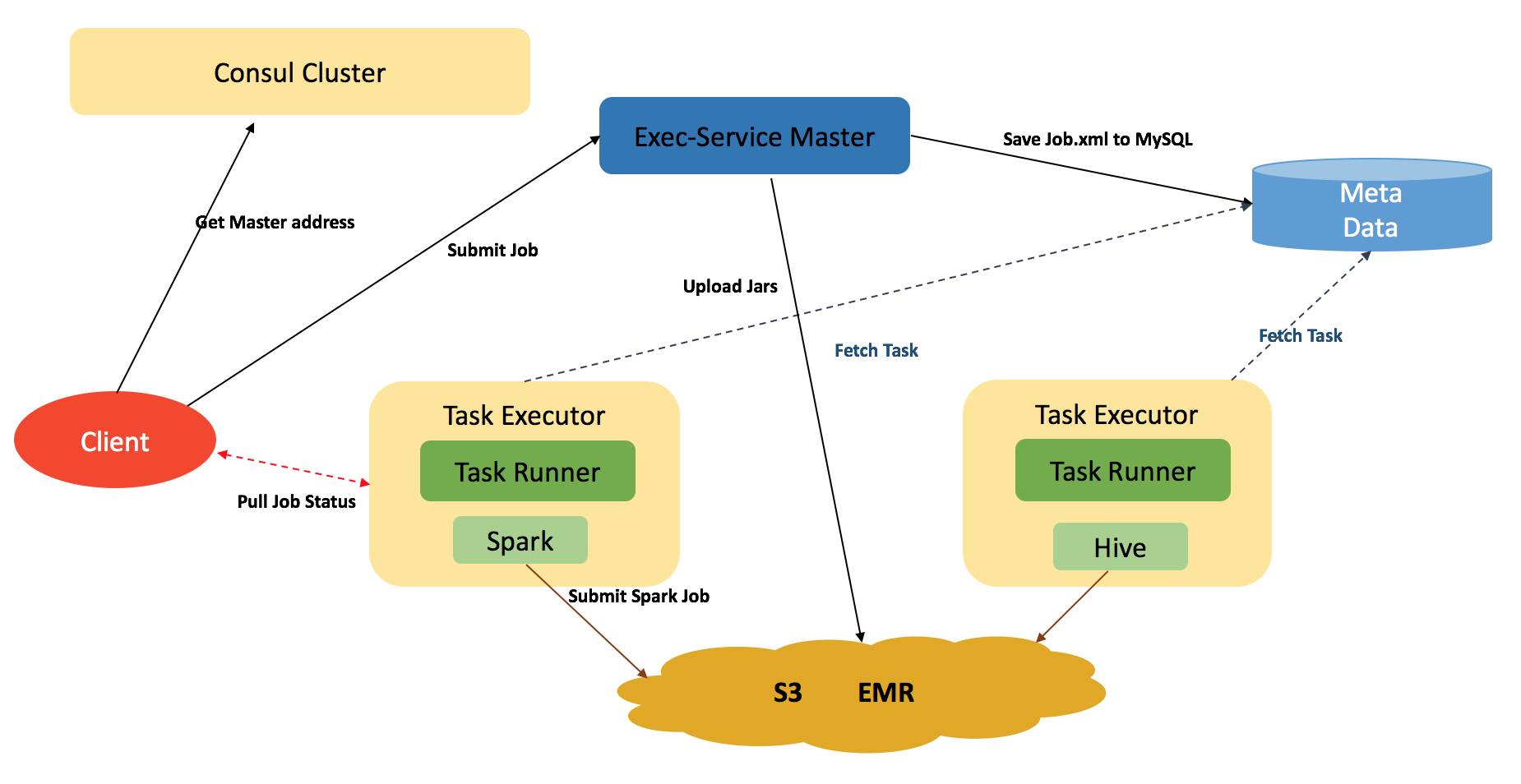
Execution Service 系统架构
ES 由一个 Master 和多个 Executor 节点组成,其支持单机与集群两种运行模式。Master 节点主要负责任务状态的管理工作,并把任务的元数据保存至数据库,而任务的执行脚本以及第三方所依赖的包,会打包上传到 S3(如果是单机模式,并不会上传 S3,而是保存至本地的 Job 目录下)。所有的 Executor 会从数据库中不断拉取待执行的任务,Executor 之间采用抢占式设计,这里如果某一个 Executor 抢到可以运行的任务,并会更新其任务的状态。
-
任务提交以及执行过程
我们说到任务,其中包括了启动 EMR 集群这样一种特殊操作,客户端在提交任务之前,会向 Consul 申请当前有无可用的 ES 服务,当然客户端可以手动指定 ES 集群的地址。Consul会返回当前正常服役的 ES Master 地址,接着客户端会向 Master 申请 Job ID,并把所要运行的相关脚本打包发送给 Master,如果是启动集群的任务,Master只会在 Meta 中创建一个待启动集群的一条指令;如果是 Bash / Hive / Spark 类型的任务,Master会把 Job 上传到 S3。在 Executor 成功获取任务之后,客户端会向 Executor 申请获取 Job 的日志,这是一个不断 Pull Log 的过程,而 Executor 会启动相应任务类型的Runner,来处理任务。
我们再以 Spark 的任务为例,来描述 Runner 的整个执行过程:Spark 与 Hive 两种类型的任务,他们的执行过程是一样的,而 Bash 类的任务,一般在 Executor 本机执行。在集群可用之后,客户端可以向集群提交计算任务,而在 Runner 从 Meta 中获取任务之后,Runner 随后会从 S3 下载执行的任务包到本地,并且解压。Runner 会创建提交任务的相关命令,以及任务所对应的输出流,以及错误流的文件。之后会把整个目录,以无密钥的方式,推向 EMR 集群的 Master 节点,而后 Runner 会再次以远程执行的方式,在 Master 节点提交 Hive 以及 Spark 任务。并把相应的输出,以及错误流保存到本地,此时客户端在不断轮循中获取到任务执行的实时日志。
-
EMR 集群创建过程
以创建集群为例,我们来描述 Runner 的整个执行过程: 在获取到需要启动集群的指令后,Job 中最少需要包括集群的名称,启动用户的相关权限,以及 EMR 集群的 Master / Slave 的机型,以及各自的数量。当然这里还有一些 IAM 的信息。接着,Runner 以客户端提供的这些信息,开始构建集群,并不断等待集群创建完成。在构建集群的过程中,EMR 集群的状态会随之变化,一般来讲,集群状态为 waiting 时,即表示集群可用。在集群创建完成之后,我们对 EMR 集群做了必要的配置,如 Consul 的注册、Hive元数据的配置、以及 Yarn 集群的一些相关参数的调整,而这一系列步骤,我们称之为 bootstrap,它由一系列 Bash 脚本构成。 之后我们重新启动 Hive 以及 Yarn 服务。这个过程结束之后,即表示集群创建完毕,而客户端此时可以选择等待集群创建完毕,也可以立即响应退出。(这两种方式分别提供给两种场景使用,如调度系统,在创建集群时, 需要等待集群创建完成之后,再调度后面的任务)
-
集群的伸缩性扩展 - Resize
在集群创建之后,或是 Job 的运行过程中,往往会根据实际情况,对集群的节点数量甚至节点类型进行微调。比如在出现意外情况时,需要修补一段很长时间的数据,往往会提升集群的计算节点(Node Manager)数量,如 ETL 类型的 Job,那么会添加内存优化的机型作为计算节点。我们把这样的过程称之为对集群的 Resize 操作,整个 Resize 可在数分钟内完成并加入集群。 而 EMR 集群本身由 Master / Core / Task 三种节点角色组成(Core 与 Task 节点的区别,是在于 Core 节点有 DataNode 进程),ES 同时支持对这三种节点的数量进行调整。 当然这样的操作,在数量上是有限制的。
-
客户端(CLI)命令
为了更为直观的了解 ES,我们以 Hive Job 为例,来看一下 CLI 的命令。我们创建一个名为 hive_job 目录,然后在该目录下,创建一个名为 run_main.hql 的脚本文件,文件内容如:
show databases; use temp; show tables;
如我们想向nobody用户所属的集群,提交上述脚本,那么客户端命令可以如下这样:
bin/submit_task -d hive_job/ -t hive -u nobody -p
总结
本文简要介绍了流利说基础数据平台的核心模块,以及 Execution Service 的系统架构。目前数据平台已趋于稳定,但随着流利说每日的数据激增,除了集群的总体计算能力的扩展,我们后期更希望在集群的资源利用率方面做更多的和探索与实战。

正文到此结束
- 本文标签: web Datanode 数据 插件 core Service rmi js HDFS UI json src Jobs ip 集群 系统架构 MongoDB Amazon Job 目录 mina 产品 配置 时间 同步 下载 云 db 互联网 map 管理 总结 python mysql node 进程 sql 大数据 开发 生命 tab 数据库 密钥 Bootstrap 参数 http Hadoop tar apr redis REST ask executor
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

