聚簇索引的优缺点
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式.比较常用的就是 InnoDB 中的聚簇索引,它实际上是在同一结构中保存了 B-tree 索引和数据行.也就是说一个表的数据实际存放在索引的叶子页中.
Mysql(InnoDB)中的聚簇索引不能指定,只能 MySQL 自动生成.InnoDB 中一般是通过主键聚集数据.(而在 Oracle 中则是需要手动创建)
在 InnoDB 中如果没有定义主键,会选择一个唯一的非空索引来代替,如果没有这样的索引,InnoDB 会隐式定义个主键来作为聚簇索引.
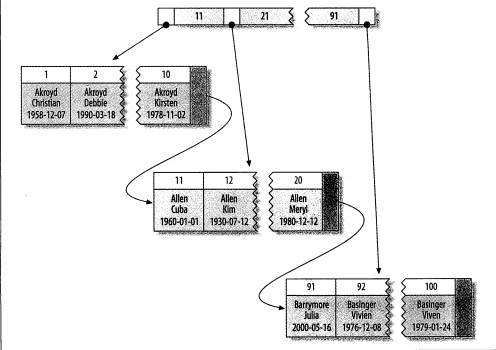
InnoDB 只聚集在一个页面中的记录,包含相邻键值的页面可能会相距很远. (这句话什么意思?)
摘自: http://blog.codinglabs.org/articles/theory-of-mysql-index.html
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用。
程序运行期间所需要的数据通常比较集中。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
一般使用磁盘I/O次数评价索引结构的优劣。先从B+Tree分析,根据B+Tree的定义,可知检索一次最多需要访问h个节点。数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B+Tree还需要使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
我的理解:这里所说的"页面"应该是指的"叶子页",因为 InnoDB 的每一个叶子页占的空间是指定的(我现在看的这本书上所写为16k,这又和上面那篇文章说所说的一个节点的大小和一个逻辑块的大小应该相等,为4K又矛盾了,不管怎样,有页和块的概念了),根据 B+tree 的特性,在叶子页相互之间是有指针连接的,也就是说正好两个在数字上相邻的键值,被分页了,而聚簇索引是一页一页为单位的,所以可能会相距很远.
聚族索引的优点
1.可以把相关数据保存在一起。例如实现电子邮件时,可以根据用户ID来聚集数据,这样只需要从磁盘读取少数的数据页就能获取某个用户的全部邮件。如果没有使用聚族索引,则每封邮件都可能导致一次磁盘I/O;
2.数据访问更快。聚族索引将索引和数据保存在同一个B-Tree中,因此从聚族索引中获取数据通常比在非聚族索引中查找更快。
3.使用覆盖索引扫描的查询可以直接使用节点中的主键值。
聚族索引的缺点
1.聚簇数据最大限度的提高了I/O密集型应用的性能,但如果数据全部都放在内存中,则访问的顺序就没有那么重要了,聚簇索引也就没有那么优势了;
2.插入速度严重依赖于插入顺序。按照主键的顺序插入是加载数据到InnoDB表中速度最快的方式。但如果不是按照主键顺序加载数据,那么在加载完成后最好使用OPTIMIZE TABLE命令重新组织一下表。
3.更新聚簇索引列的代价很高,因为会强制InnoDB将每个被更新的行移动到新的位置。
4.基于聚簇索引的表在插入新行,或者主键被更新导致需要移动行的时候,可能面临“页分裂”的问题。当行的主键值要求必须将这一行插入到某个已满的页中时,存储引擎会将该页分裂成两个页面来容纳该行,这就是一次分裂操作。页分裂会导致表占用更多的磁盘空间。
5.聚簇索引可能导致全表扫描变慢,尤其是行比较稀疏,或者由于页分裂导致数据存储不连续的时候。
6.二级索引(非聚簇索引)可能比想象的要更大,因为在二级索引的叶子节点包含了引用行的主键列。
7.二级索引访问需要两次索引查找,而不是一次。
备注:有关二级索引需要两次索引查找的问题? 答案在于二级索引中保存的“行指针”的实质。要记住,二级索引叶子节点保存的不是指向行的物理位置的指针,而是行的主键值。这意味着通过二级索引查找行,存储引擎需要找到二级索引的叶子节点获得对应的主键值,然后根据这个值去聚簇索引中查找到对应的行。这里做了重复的工作:两次B-Tree查找而不是一次。对于InnoDB,自适应哈希索引能够减少这样的重复工作。
--------------伟大的分割线----------------
PHP饭米粒(phpfamily) 由一群靠谱的人建立,愿为PHPer带来一些值得细细品味的精神食粮!
饭米粒只发原创或授权发表的文章,不转载网上的文章
所发的文章,均可找到原作者进行沟通。
也希望各位多多打赏(算作稿费给文章作者),更希望大家多多投搞。
投稿请联系:
shenzhe163@gmail.com
本文由 周梦康 向 饭米粒投稿,转载请注明本来源信息和以下的二维码(长按可识别二维码关注)

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

