#Deep Learning回顾#之2006年的Science Paper
大家都清楚神经网络在上个世纪七八十年代是着实火过一回的,尤其是后向传播BP算法出来之后,但90年代后被SVM之类抢了风头,再后来大家更熟悉的是SVM、AdaBoost、随机森林、GBDT、LR、FTRL这些概念。究其原因,主要是神经网络很难解决训练的问题,比如梯度消失。当时的神经网络研究进入一个低潮期,不过Hinton老人家坚持下来了。
功夫不负有心人,2006年Hinton和学生发表了利用RBM编码的深层神经网络的Science Paper:Reducing the Dimensionality of Data with Neural Networks,不过回头来看,这篇paper在当今的实用性并不强,它的更大作用是把神经网络又推回到大家视线中,利用单层的RBM自编码预训练使得深层的神经网络训练变得可能,但那时候Deep learning依然争议很多,最终真正爆发是2012年的ImageNet的夺冠,这是后话。
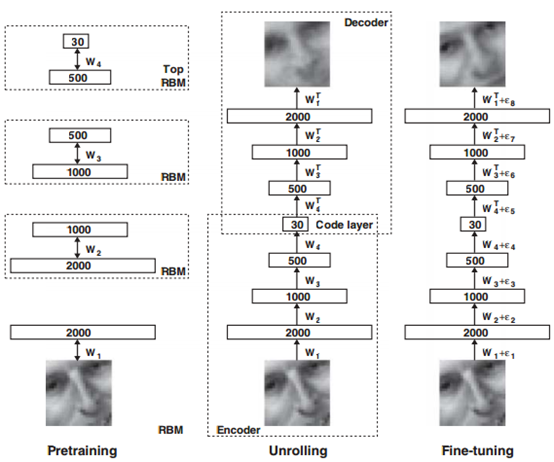
如图中所示,这篇paper的主要思想是使用受限RBM先分层训练,受限的意思是不包含层内的相互连接边(比如vi*vj或hi*hj)。每一层RBM训练时的目标是使得能量最小:
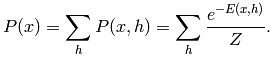
能量最小其实就是P(v, h)联合概率最大,而其他v’相关的p(v’, h)较小,后面这个是归一化因子相关。这块如果理解有问题的,需要补一下RBM相关知识,目前网上资料不少了。
大致的过程为,从输入层开始,不断进行降维,比如左图中的2000维降到1000维, 降维时保证能量最小,也就是输出h和输入v比较一致,而和其他输入v’不一致,换句话说,输出尽量保证输入的信息量。降维从目标上比较类似于PCA,但Hinton在文章说这种方法比PCA效果会好很多,尤其是经过多层压缩的时候(比如784个像素压缩到6个实数),从原理应该也是这样的,RBM每一层都尽量保留了输入的信息。
预训练结束后,就会展开得到中间的解码器,这是一个叠加的过程,也就是下一层RBM的输出作为上一层RBM的输入。
最后再利用真实数据进行参数细调,目标是输入图片经过编码解码后尽量保持原图信息,用的Loss函数是Likelihood:
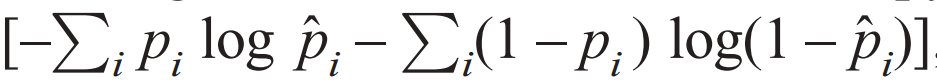
这篇在今天看来实用性不太大,难度也不大,但在当时这篇文章看起来还是晦涩的,很多原理没有细讲。为何能中Science?个人认为,毕竟Hinton是神经网络的泰斗,换个人名不见经传的人估计中不了,另外这篇文章也确实使得以前不可能的深层神经网络变得可能了,在今天依然有很多可以借鉴的地方,细心的同学会发现上百或上千层的ResNet的思想在一定程度上和这篇论文是神似的。
参考资料:
[1] Paper: http://www.cs.toronto.edu/~hinton/science.pdf
[2] 代码: http://www.cs.toronto.edu/~hinton/MatlabForSciencePaper.html
本文只是简单回顾,疏漏之处敬请谅解,感兴趣的可以加QQ群一起学习:564533376
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

