谷歌SyntaxNet大升级,为40种语言带来文本分割新功能
正值 ACL 2016 举办之际, 我们很高兴地 宣布 :在 五月 作为 SyntaxNet 的一部分和云自然语言 API 的基础发布的 Parsey McParseface 已经有 40 个兄弟姐妹了!Parsey 的兄弟姐妹是一个包含 40 种语言的预训练句法模型集,能以前所未有的精确度分析超过半数世界人口的母语。为了更好地处理这些语言中的语言现象,我们赋予了 SyntaxNet 新能力——文本分割(Text Segmentation)和词态分析(Morphological Analysis)。
当我们发布 Parsey 时,我们就已经计划要扩增更多的语言了,并且这很快被确定是紧急且重要的事情,因为研究者在为其它语言构造顶级 SyntaxNet 模型时遇到了麻烦。
其原因很微妙。像其他 TensorFlow 模型一样,SyntaxNet 有许多需要调整的「旋钮」,它们影响着精确度和速度。这些旋钮被称为超参数(hyperparameter),控制着学习率和其衰减、动量、以及随机初始化等事情。因为神经网络对这些超参数的选择要比许多其他机器学习算法要敏感得多,所以选择正确的超参数设定是非常重要的。不幸的是,没有一种经过测试和证明的方法能办到这事,并且,选择好的超参数几乎是一种经验科学——我们尝试大量的设定,从中找出表现最好的。
另一项挑战是训练这些模型会花很长时间,即使是在非常快的硬件上也要花好几天。我们的解决方案是通过 MapReduce 并行训练许多模型,当其中一种模型看起来有前途时,训练更多带有相似设定的模型以微调结果。模型会越积越多——平均而言,我们会为每种语言训练超过 70 个模型。下面的图显示了精确度是如何随着训练过程中超参数的变化而变化的。比起一个没有微调超参数的模型,表现最好的模型的精确度可以高出 4%。
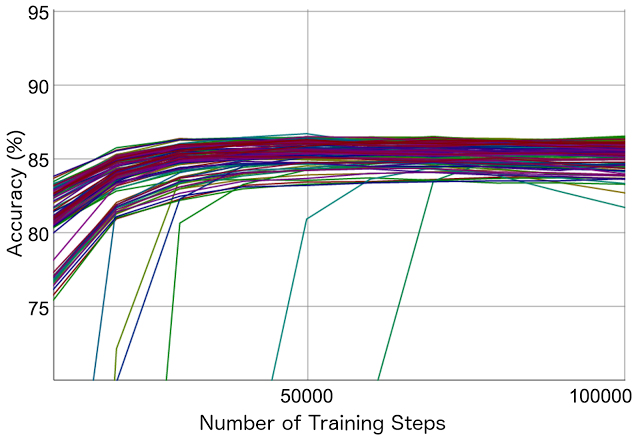
不同超参数下的英语分析模型的留存设定精度(held-out set accuracy,每条线对应一个设定了特定超参数的训练)。在一些情况下,训练是非常慢的,并且在许多情况下超参数的次优选择会明显降低精确度。我们发布的是我们所能为每种语言训练出的最佳模型。
为了更好地分析其他语言的语法,仅微调我们的英语设置是不够的。我们也得扩展 SyntaxNet 的能力。第一项扩展是一个文本分割模型,用来识别字词边界(word boundaries)。在类似英语的语言中,这并不难——你几乎只需关注空格和标点符号。然而在中文中,这相当有挑战,因为词之间没有用空格分开。为了正确地分析中文词之间的依赖性,SyntaxNet 需要理解文本分割——现在它能做到。
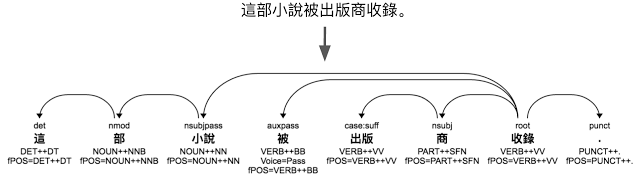
将一段中文字符串解析成分析树,显示了其依赖标签、词标记和词性(自上往下读每个单词标记)
第二项扩展是一个词态分析模型。词态学(morphology)是一种几乎没在英语中表现的语言特征。它描述了词形变化:例如,语法功能和单词的意思是如何随着它的拼写的改变而改变的。在英语中,我们通过在一个单词后加 s 来表示复数。在像俄语这种词尾高度变化的语言中,词态学可以指示数量、性别、单词是句子的主语还是宾语、所有格、介词短语等等。为了理解一句俄文句子的句法,SyntaxNet 需要理解词态学——现在它能做到。
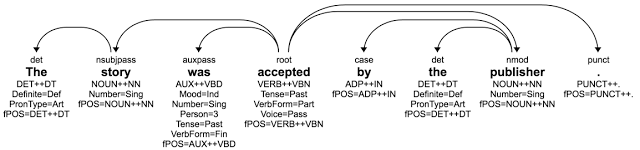

分析树展示了依赖标签、词性和词态学
你可能已经注意到了,上述所有句子的分析树看起来非常相似。这是因为我们遵循内容优先原则,依赖性会被画在内容词之间,功能词成为分析树的叶子。为了增加不同语言之间的并行性(parallelism),Universal Dependencies 项目提出了该想法。Parsey 的兄弟姐妹们基于由该项目提供的树库(treebank)进行训练,并进行了跨语言的统一设计,因此更容易在多语言的语言理解应用中使用。
在不同语言中使用相同的标签集能帮助我们理解不同语言的句子或相同语言中的变体是如何表达相同的意思的。在上述所有例子中,树根(root)指示了句子的主要动词,并且这里有一个被动的名词主语(被「nsubjpass」的弧标签指示)和一个被动的助动词(「auxpass」)。如果你仔细看,你也会注意到一些不同,因为每种语言的语法不同。例如,英语使用介词「by」,而俄语使用词态学来标记短语「the publisher(издателем)」是工具格( instrumental case)——意思是相同的,只是表达方式不一样。
谷歌已经通过 inception 参与了 Universal Dependencies 项目,并且我们非常高兴能够为大家带来我们在数据集和模型上的成果。我们希望这次发布能加速构建能理解世界上所有语言的计算机系统的研究进程。
Parsey 的兄弟姐妹 、 Parsey McParseface 和 SyntaxNet 能在 GitHub 上找到。
原文 http://www.jiqizhixin.com/article/1397正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

