剖析Elasticsearch集群系列第三篇 近实时搜索、深层分页问题和搜索相关性权衡之道
剖析Elasticsearch集群系列涵盖了当今最流行的分布式搜索引擎Elasticsearch的底层架构和原型实例。本文是这个系列的第三篇,我们将讨论Elasticsearch是如何提供近实时搜索并权衡搜索相关性计算的。
本系列已经得到原文著者Ronak Nathani的授权
在本系列的前一篇中,我们讨论了Elastisearch如何解决分布式系统中的一些基本挑战。在本文中,我们将探讨Elasticsearch在近实时搜索及其权衡计算搜索相关性方面的内容,Insight Data的工程师们已经在使用Elasticsearch构建的数据平台之上,对此有所实践。我将在本文中主要讲述:
- 近实时搜索
- 为什么深层分页在分布式搜索中是有害的?
- 计算搜索相关性中的权衡
近实时搜索
虽然Elasticsearch中的变更不能立即可见,它还是提供了一个近实时的搜索引擎。如前一篇中所述,提交Lucene的变更到磁盘是一个代价昂贵的操作。为了避免在文档对查询依然有效的时候,提交变更到磁盘,Elasticsearch在内存缓冲和磁盘之间提供了一个文件系统缓存。内存缓存(默认情况下)每1秒刷新一次,在文件系统缓存中使用倒排索引创建一个新的段。这个段是开放的并对搜索有效。
文件系统缓存可以拥有文件句柄,文件可以是开放的、可读的或者是关闭的,但是它存在于内存之中。因为刷新间隔默认是1秒,变更不能立即可见,所以说是近实时的。因为translog是尚未落盘的变更持久化记录,它能有助于CRUD操作方面的近实时性。对于每次请求来说,在查找相关段之前,任何最近的变更都能从translog搜索到,因此客户端可以访问到所有的近实时变更。
你可以在创建/更新/删除操作后显式地刷新索引,使变更立即可见,但我并不推荐你这样做,因为这样会创建出来非常多的小segment而影响搜索性能。对于每次搜索请求来说,给定Elasticsearch索引分片中的全部Lucene段都会被搜索到,但是,对于Elasticsearch来说,获取全部匹配的文档或者很深结果页的文档是有害的。让我们来一起看看为什么是这样。
为什么深层分页在分布式搜索中是有害的?
当我们的一次搜索请求在Elasticsearch中匹配了很多的文档,默认情况下,返回的第一页只包含前10条结果。search API提供了 from 和 size 参数,用于指定对于匹配搜索的全部文档,要返回多深的结果。举例来说,如果我们想看到匹配搜索的文档中,排名为 50 到 60 之间的文档,可以设置 from=50 , size=10 。当每个分片接收到这个搜索请求后,各自会创建一个容量为 from+size 的优先队列来存储该分片上的搜索结果,然后将结果返回给协调节点。
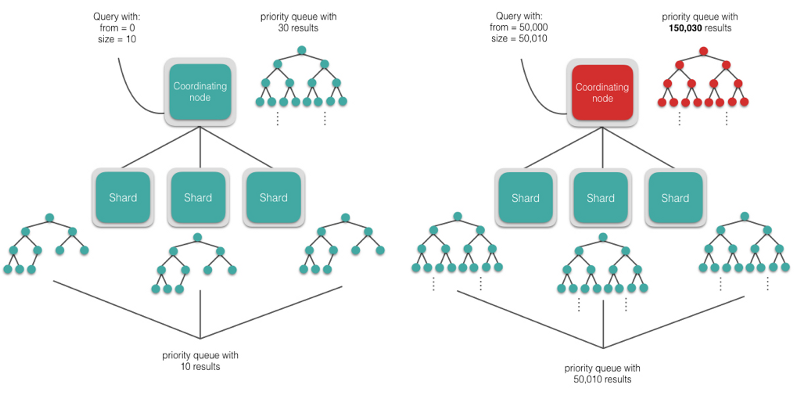
如果我们想看到排名为 50,000 到 50,010 的结果,那么每个分片要创建一个容量为 50,010 的优先队列来存储结果,而协调节点要在内存中对 数量为shards * 50,010 的结果进行排序。这个级别的分页有可能得到结果,也有可以无法实现,这取决于我们的硬件资源,但是这足以说明,我们得非常小心地使用深分页,因为这非常容易使我们的集群崩溃。
一种获取全部匹配结果文档的可行性方案是使用 scroll API ,它的角色更像关系数据库中的 游标 。使用 scroll API 无法进行排序,每个分片只要有匹配搜索的文档,就会持续发送结果给协调节点。
获取大量文档的时候,对结果进行得分排序会非常昂贵。并且由于Elasticsearch是分布式系统,为每个文档计算搜索相关性得分是非常昂贵的。现在,让我们一起看看计算搜索相关性的诸多权衡中的一种。
计算搜索相关性中的权衡
Elasticsearch使用 tf-idf 来计算 搜索相关性 。由于其分布式的性质,计算全局的idf(inverse document frequency,逆文档频率)非常昂贵。反之可以这样,每个分片计算本地的idf并将相关性得分分配给结果文档,返回的结果只关乎该分片上的文档。同样地,所有分片使用本地idf计算的相关性得分,返回结果文档,协调节点对所有结果排序并返回前几条。这样做在大多数情况下是没有问题的,除非索引的关键字词项有倾斜或者单个分片上没有代表全局的足够数据。
比如说,如果我们搜索“insight”这个词,但包含"insight"这个词项的大多数文档都存放在一个分片上,这样以来匹配查询的文档将不能公平地在每个分片上进行排序,因为每个分片上的本地idf的值非常不同,得到的搜索结果可能不会非常相关。同样地,如果没有足够的数据,那么对于某些搜索而言,本地idf的值可能大有不同,结果也会不如预期相关。在有足够数据的真实场景中,本地idf值一般会趋于均等,搜索结果是相关的,因为文档得到了公平的得分。
这里有2种应对本地idf得分的办法,但都不建议真正在生产环境中使用。
- 一种办法是一索引一分片,本地idf即是全局idf,但这没有为并行计算/水平伸缩留有余地,对于大型索引并不实用。
- 另一种办法是在搜索请求中使用 dfs_query_then_search (dfs = distributed frequency search,分布式频率搜索) 参数,这样以来,会首先计算每个分片的本地idf,然后综合这些本地idf的值来计算整个索引的全局idf值,最后使用全局idf计算相关性得分来返回结果。这种方式不为生产环境推荐,因为有足够的数据确保词项频率分布均匀。
在本系列的过去几篇中,我们回顾了一些Elasticsearch的基本原则,对于我们理解并上手Elasticsearch,这些内容非常重要。在接下来的一篇中,我将使用Apache Spark来研究Elasticsearch中的索引数据。
查看英文原文: Anatomy of an Elasticsearch Cluster: Part III
感谢杜小芳对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

