IM 去中心化概念模型与架构设计
本文转自微信公众号: mindwind 瞬息之间
原文
http://www.iteye.com/news/31782
今天打算写写关于 IM 去中心化涉及的架构模型变化和设计思路,去中心化的概念就是说用户的访问不是集中在一个数据中心,这里的去中心是针对数据中心而言的。
站在这个角度而言,实际上并非所有的业务都能做去中心化设计,对于一致性要求越高的业务去中心化越难做。比如电商领域的库存就是一个对一致性要求很高的业务,不能超卖也不能少卖,这在单中心容易实现,但多中心纯从技术层面感觉无解,可能需要从业务和技术层面一起去做个折衷。
反过来看 IM 的业务场景是非常适合做去中心化设计的,因为其业务场景都是弱一致性需求。打开你的微信或 QQ 仔细观察下,对大部分人来说与你联系最频繁的实际多是在地域上离你最近的人,人与人之间的心理距离和物理距离会随着时间渐趋保持一致。所以根据这个特点,按地域来分布数据中心和聚合人群是比较合适的。
在进入去中心化 IM 架构模型之前,我们先看看中心化架构是怎样的,分析其关键设计再来看如果要去中心化需要做哪些变化?
中心化IM的中心化架构并不意味着只有一个数据中心,它也可以是多数据中心的,如下图。
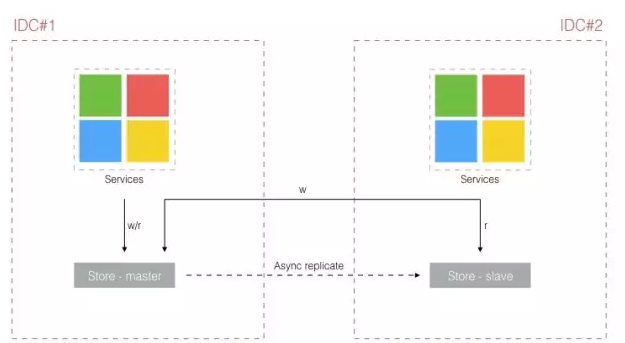
之所以说它是中心化架构,关键特征是其存在共享的数据存储。部署在两个数据中心的应用需要共享访问统一的数据存储,而这种共享访问实际是依赖数据中心之间的专线连通,这样的架构也限制了能选取的数据中心地理位置的距离。而实现去中心架构的关键点就在于规避跨数据中心的共享存储访问,使得应用在其自身数据中心实现访问闭环。
我们这里只分析下实现 IM 消息互通这个最重要场景下共享数据存储里需要存些什么数据呢?一个是用户上线后的「座标」,主要指用户本次在线接入了哪台机器的哪根连接,这个「座标」用于在线消息投递。而另一方面若用户离线时,别人给它发消息,这些消息也需要存储下来,一般称为用户的「离线消息」,下次用户上线就可以自动收取自己的离线消息。
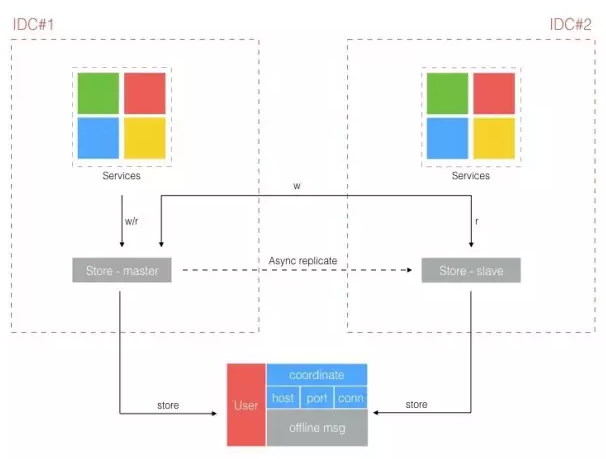
中心化架构实际能做到的极致就是把读实现自有数据中心闭环,而写依然需要向主数据中心所在的存储写入。而 IM 的写入场景还不算是一个低频操作,那么要实现去中心化架构关键点就在如何解决写的问题上。
去中心化在设计 IM 的去中心化架构之前,希望去实现这个架构并编写代码时,不需要去考虑最终部署到底是去中心的还是中心的。编码时就像开发中心化架构一样去实现场景的功能,而去中心化的能力做为纯基础的技术能力,通过附加的方式来获得,先看看架构图的变化,如下。
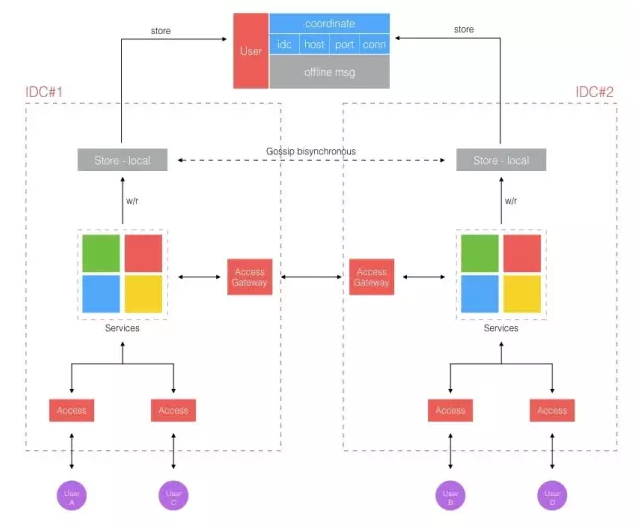
这里的变化是为「座标」增加一个「数据中心」纬度,当按通用的方式去本地存储定位用户时,发现一个非本地的座标时消息该怎么投递?这里可以在每个本地数据中心额外添加一个消息网关程序,注册到本地存储中,并负责接收所有非本地座标的消息,这有点像路由网络中的边界网关。
消息网关统一接收应当发往其他数据中心的消息,以实现跨数据中心的消息流转。这里有个疑问是其他数据中心的「座标」是怎么跑到本地来的?离线消息的场景又该如何处理呢?关于这两个问题,就涉及到我们解决跨数据中心同步数据的关键技术了。
关键技术结合 IM 的业务场景,实际它对同步的延时具有一定的容忍度。所以我觉得基于 Gossip 协议的小道消息传播特性就能很好的满足这个同步场景。
关于 Gossip 我是在新近的 NoSQL 数据库 Cassandra 上听说的,后来 Redis Cluster 也利用了该协议来实现无中心化集群架构。但 Gossip 协议可不是什么新东西,实际关于它的诞生可以追溯到好几十年前的施乐研究中心,就是为了解决数据库同步问题被我们的前前前辈想出来的。
这个协议的灵感来自于办公室小道消息的传播路径,当一个人知道了一条小道消息,他碰到一个朋友并随口告诉了他,朋友又告诉了朋友的朋友,没多久整个办公室都知道了,也就完成了信息的同步。借用这个模型,实际上我们需要同步的信息就是用户的在线「座标」和「离线消息」。
因为 Gossip 自好几十年前已经有很多论文证明并公开发表,而且近年也有 Cassandra 和 Redis 的成功工程实践,所以我就先不用去怀疑其可行性,而是直接利用其结论了。根据其特性,分析 IM 的去中心场景在引入 Gossip 后有些什么可供观察的变化和值得注意的方面。
在一个稍具规模的 IM 场景下,用户总是在上上下下,消息也在不停的在「在线」和「离线」之间变化,所以需要通过 Gossip 同步的信息是时时存在的。所以假设我们在某个时刻去拍一个快照(实际做不到),得到的结果是多个数据中心的数据肯定是不一致的,几乎不存在所谓的全局最终一致性的某一时刻。在这样的客观环境下,对 IM 的业务场景有多大影响?
当用户A在 IDC#1 在线,用户B 在 IDC#2 刚上线,这里存在一个同步时差,那么此时用户A给用户B发消息,在本地没有用户B的座标,所以进入离线消息池。用户B此时不能立刻收到用户A的消息,但离线消息池会在随后通过 Gossip 协议同步到用户B所在的 IDC#2,用户B此时就可以通过离线消息收取用户A的消息。
上面描述了一种临界场景,在这种临界场景下,用户收消息存在延时。而这种临界场景实际上并不是常态,而且 IM 用户实际对这种刚上线的消息延时存在很高的容忍度。这一点我想大家用 QQ 可能体会过,有时一上线都一分钟了,还会收到之前的离线消息,我不知道这是有意的延时还是真有这么长的系统延时。
那么使用 Gossip 协议从理论上来估算下会产生多久的延时?假设我们在全国东西南北中各部署一个数据中心,一共五个。五个数据中心之间无专线,走公网互通,网络延时最大 200 ms。使用 Gossip 完成在五个数据中心的最终一致性同步最大需要多长时间?这里我直接引用 Gossip 论文结论:
Cycles = log(N) + ln(N) + O(1)
当 N=5 时,完成全部同步,需要节点间私下传播的次数,套用公式得到 3.3 次,取整得 4 次。按最大网络延时 200 ms,每次 Gossip 交换信息间隔 100 ms,那么协议本身固有延时大约 4x200 + 4x100 = 1.2s,而再算上程序开销,这个延时很可能在数秒内波动,这个量级的延时对于少数的临界场景是完全可以接受的。
总结本文的标题是概念模型,但它不像另外一篇《RPC 的概念模型与实现解析》跟了实现解析,说明这只是一个理论推导。因为里面最关键的是如何配合 Gossip 的共享存储似乎没有找到特别适合的产品,要是自己做一个呢就会产生一种今天只想出去兜兜风,却要先自己动手造辆车的感觉。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

