一个计算我的妻子是否怀孕的贝叶斯模型
在2015年的二月21日,我的妻子已经33天没有来月经了,她怀孕了,这真是天大的好消息!通常月经的周期是大约一个月,如果你们夫妇打算怀孕,那么月经没来或许是一个好消息。但是33天,这还无法确定这是一个消失的月经周期,或许只是来晚了,那么它是否真的是一个好消息?
为了能获得结论我建立了一个简单的贝叶斯模型,基于这个模型,可以根据你当前距离上一次经期的天数、你历史经期的起点数据来计算在当前经期周期中你怀孕的可能性。在此篇文章中我将阐述我所使用的数据、先验思想、模型假设以及如何使用重点抽样法获取数据并用R语言运算出结果。在最后,我将解释为什么模型的运算结果最终并不重要。另外,我将附上简便的脚本以供读者自行计算.
数据
非常幸运的是,在2014年的下半年间我的妻子一直在记录她经期起始日期,否则我只能以仅拥有小量数据而告终。总体上我们拥有8个经期的起始日期数据,但是我采用的数据不是日期而是相邻经期起始日间相隔的天数。 已经有33天。
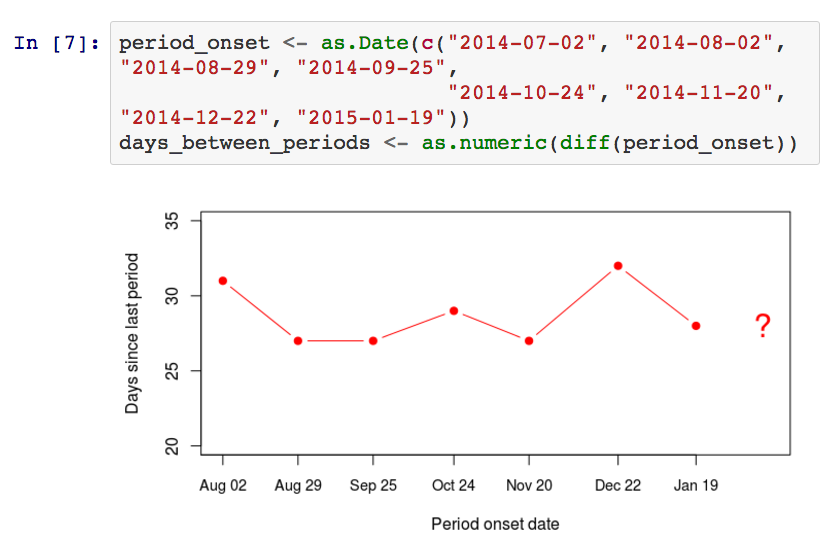
所以日期发生得相对规律,以28天为一个周期循环。最后一次月经开始日期是在1月19日,所以在2月21日,距离最后一次经期发生日。
模型的建立
我要建立一个涵盖生理周期的模型,包括受孕期和不受孕期,这显然需要做大量的简化。我做了一些 总体假设 如下:
- 一对情侣受孕与否不受其他因素的影响。
- 女方拥有固定的经期。
- 该对想要受孕的夫妻正在积极地尝试受孕。换言之,如Wilcox et al. (2000) 推荐的每周两次到三次受精。
- 一旦怀孕,期间将不会有经期。
接下来是我所做的具体假设:
- 假设两个相邻经期间隔的天数(days_between_periods)服从的正态分布,其中均值(mean_period)和标准差(sd_period)未知。
- 假设在一对生育能力的夫妻(is_fertile为真 )受孕时一个周期内怀上孕的概率是0.19(更多关于选定该值的由来见参考文献)。不幸的是,并非所有的夫妻都具备生育能力,没有生育能力则怀孕的几率为零。如果生育率被编码为 0-1,那么可生育率可以被简洁的写为 0.19* is_fertile.
- 在某一些不能受孕的时期(n_non_pregnant_periods)的怀孕失败率则为(1 - 0.19 * is_fertile)^n_non_pregnant_periods
- 最后,如果你在这一个周期内(从上一次生理期至这一次生理期为一个周期)将不会怀孕;那么最新一次经期距离下一个经期的天数(next_period)将必然会大于最新一次经期距离当前日期的天数(days_since_last_perio)。即,next_period < days_since_last_period的概率为零。这么做看上去很奇怪因为这个事件是显然的,但是我们在模型中将会要用到它。
基本的假设就是这样了。但是为了使其更加实际,需要考虑使用一个似然函数,一个给定了参数和一些数据、计算在给定参数下数据的概率,通常而言是一个与概率成正比例的数值——似然值。因为这个似然值可能极小所以我需要对其取对数,从而避免引起数值问题。当用R语言设计似然函数时,总体上的模式如下:
- 方程将数据和参数作为选项。
- 通过预处理,将似然值的初始值设为1.0,相应的对数为0.0。(log_like <- 0.0)
- 用R语言调用概率密度分布函数(比如dnorm, dbinom and dpois),用该函数计算模型中不同部分的似然值。然后将这些似然值相乘。对应地,将取对数后的似然值log_like相加。
- 为了让d*函数返回对数似然值,只需添加参数log=TRUE。并且注意似然值0.0对应的取对值为-inf
所以,综上所述该模型的对数似然函数如下:
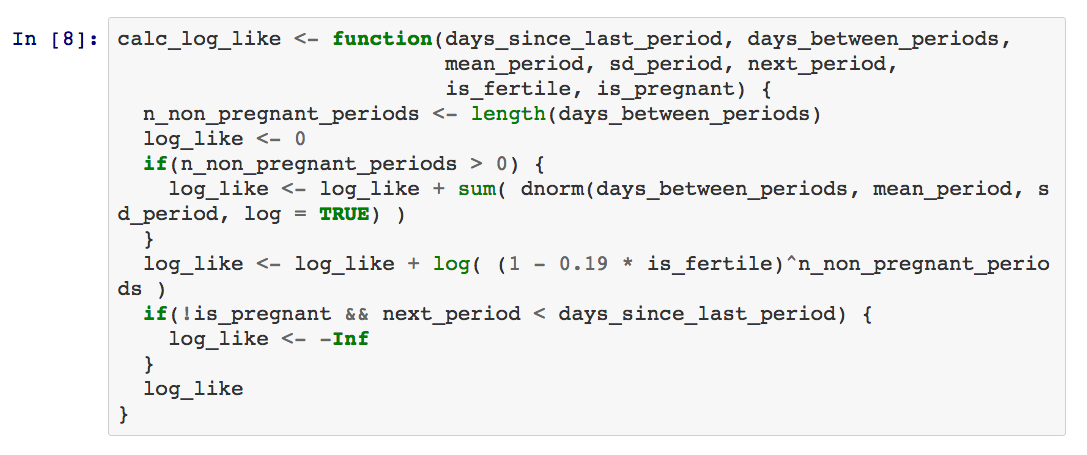
这里数据有标量days_since_last_period以及向量days_between_periods,而其他的参数将会被被估计出来。使用这个函数,我能从任意一个数据+参数的组合中得出对数似然函数值。但是,到这里我只完成了建模的一半工作,我还需要先验信息!
关于经期,受孕和生育的先验信息
为了完善这个模型,我需要所有参数的先验信息。换言之,我需要明确在获取数据之前这个模型包含了哪些信息。具体上,我需要实验开始前mean_period, sd_period, is_fertile, and is_pregnant的初始值。(虽然next_period也是一个参数,我不需要给出一个它的确切初始值,因为它的分布完全由mean_period 和sd_period确定。另外,我还需要找到在一个周期内能受孕的可能值(上文中我设定为0.19)。这里我使用了模糊、主观的数据吗?不!我到生育文献中去寻找了更加有信息价值的依据!
对于days_between_periods的分布,其参数为mean_period和sd_period。这里我使用了来自文章The normal variabilities of the menstrual cycle Cole et al, 2009 中的估计值,该文测量了184个年龄来自18-36岁的女性的经期规律。相邻经期间天数的总平均值为27.7天。每一个参与实验者的标准差的平均值为2.4。总体样本的间隔天数的标准差为1.6。给定了这些估计值以后我令mean_period服从(27.7,2.4)的正态分布,令sd_period服从均值为1.6,标准差为2.05的半正态分布。如下:
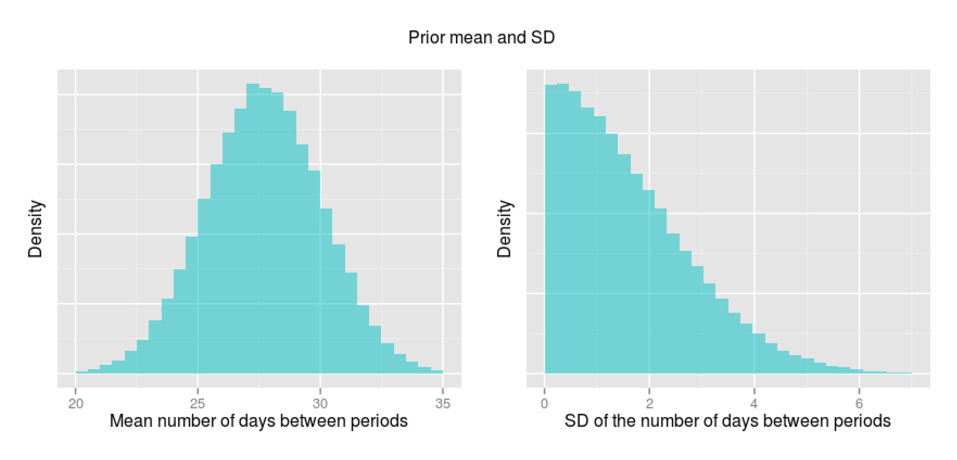
对于参数is_fertile a以及参数is_pregnant我考虑了受精频率作为先验。想要确定可育的夫妻的比例几乎是不可能的事情,因为这里对于不育有各种不同的定义。 Van Geloven et al. (2013)做了一个小范围的文献回顾然后得出结论所有夫妻中有2%至5%的人被认为是不孕的。因为曾看到高达10%的情况,我决定取该范围的上限。设定初始数据100%-5%=95%的夫妻是可孕的。
is_pregnant 是 0 1变量表示这对夫妻在最近的一轮周期中是否将要(或者说已经)受孕。在这里我使用的先验值是在一个周期内成功受孕的概率。当这对夫妇没有生育能力时这个概率值显然为0.0,但是积极地尝试、可育的夫妇在一个周期内成功受孕的比例有多大呢?不幸的是我并没有找到明确说明这一数据的文献,但是我找到了比较接近的参照依据。在Increased Infertility With Age in Men and Women Dunson et al. (2004) 一书的第53页,给出了在12个月中一直尝试受孕但是没有怀上的夫妻的比例,同时该数据也提供了女性不同年龄段的数据。


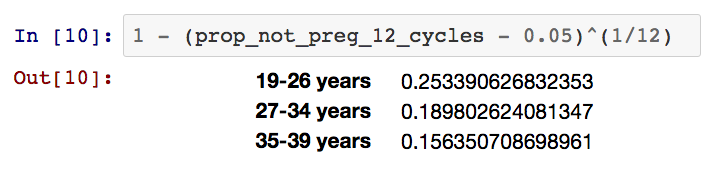
故上述即为对数似然函数中19%的怀孕概率值的由来,19%亦作为is_pregnant的先验值。现在我有了所有参数的先验,可以建立一个由先验函数的抽样函数了。

这里使用了一个参数(n),它输出了一个n行的数据框,每一行是基于先验数值得出的样本数据。输出结果如下:
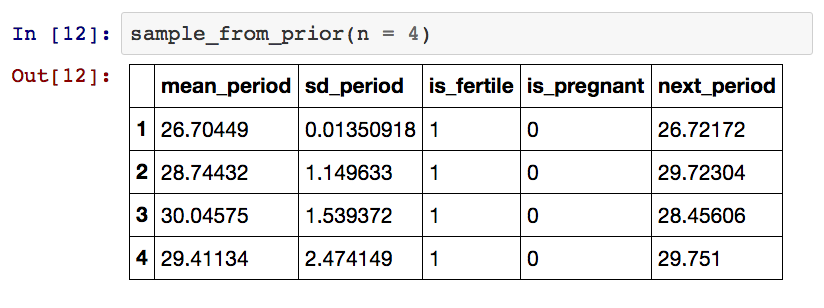
使用重要性抽样来拟合模型
现在,我已经收集了贝叶斯统计分析的三大要素:先验信息,似然函数以及数据。为了拟合模型我有很多方法,但是这里有一个非常方便的方法——重要性抽样。我之前曾写文提及过重要性抽样法,这里我们来回顾一下:重要性抽样法是一种蒙特卡洛实验法,它建立起来非常简单并且适用于以下情况:(1)参数空间非常小(2)先验分布与后验分布的形式区别不大。因为我的参数空间比较小,加之我使用了信息量包含得比较丰富的先验数据。因此,认为重点抽样法在此例中是可用的。在重要性抽样法中三个基本的步骤为:
- 由先验分布产生大样本(这里可以通过sample_from_prior得到)
- 给定了参数时,对每一个与似然值成比例的先验数据进行赋权。(这里可以通过 calc_log_like 得到)
- 将权重归一化,从而在先验分布的情况下形成了新的概率分布。最终,根据此概率分布对先验分布的样本进行重新抽样。(这里可以用R函数抽样)
( 注意存在与该过程不同的多种方法,但是在用来拟合贝叶斯模型时,这是重要性抽样法的常用版本)
因为我已经定义过 sample_from_prior 和 calc_log_like,因此需要定义一个新的方程来做后验抽样:

结果:怀孕的可能性
因此,在2月21日,2015,我的妻子已经没有来月经33天了。这是一个好休息吗?让我们运行这个模型看看结果吧!

post这里是一个长数据框,其中数值的表示基于这些参数得出的后验分布信息。
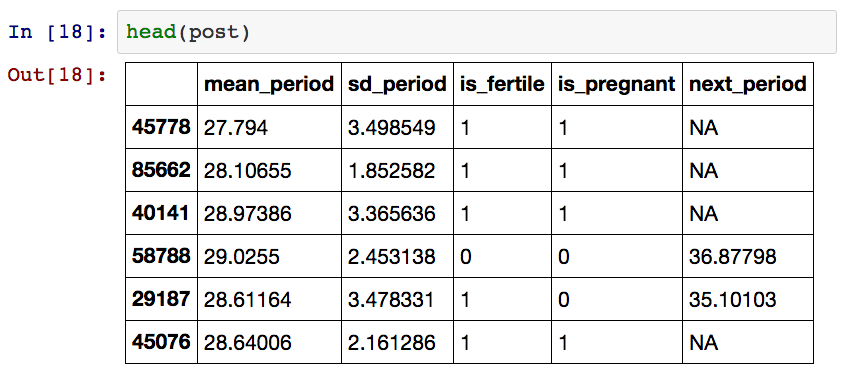
让我们来看看各个周期中间隔天数的均值和方差的变化吧。
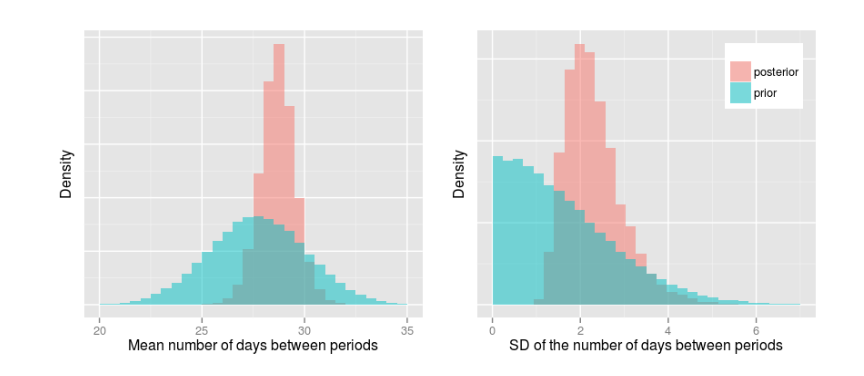
像期望的那样,后验分布的图像比先验数据更狭长;并且观察后验数据,大致得出平均的经期周期天数在29天左右,其标准差在2-3天左右。那么重要问题来了:我们是可育夫妻的概率为多少,以及我们在2月21日确定已经怀孕的概率为多少?为了计算这个我们取 postisfertile 与 post is_pregnant ,并计算众数。当然一个捷径是直接采用均值。
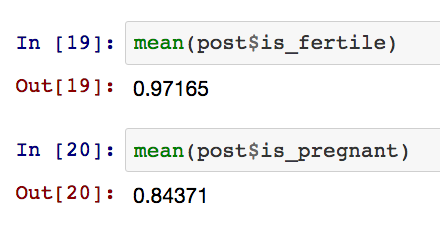
因此这是一个相当好的消息:我们极有可能是可孕的夫妻,并且我们已经受孕的可能性高达84%!用这个模型我可以了解到:当经期的来临再多延迟几天,我们确定怀孕的概率是如何随之而变化的。


是的,既然我们已经得到了好消息,为何不看看在我们之前尝试受孕的数月中我们可孕和受孕成功的可能性是如何变动的呢?
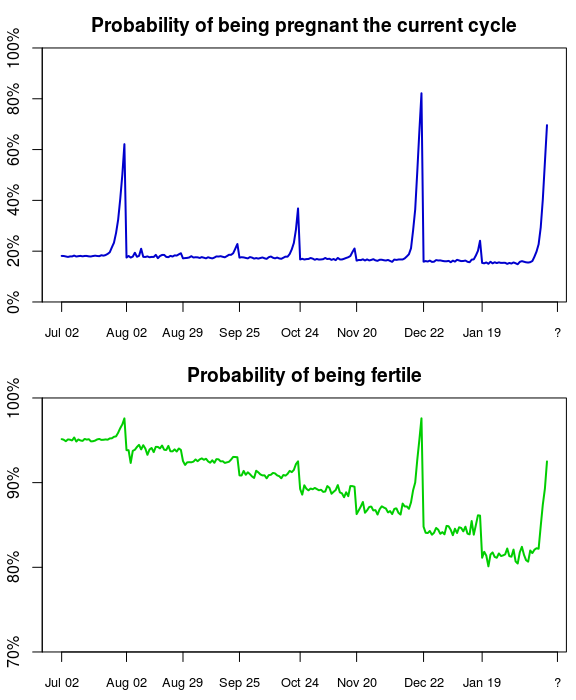
因此,这能够解释得通了。在距离“最后一次经期”的时间变长时,我们在当前周期怀孕成功的几率增加了,但是一旦这里有经期发生时可能性会跌回至基线。我们看到的可孕率曲线是几乎相同的,但在我们没有怀孕成功的每一个周期里,可孕率曲线稍稍有所下降。这两个指标的图像均呈轻微的锯齿状,但这只是由重要性抽样算法的偏差导致的。另外需指出的是,虽然上述的图像非常美观,但是查看未怀孕期间的概率是无效的,唯一具重要性和信息价值的是当前的概率。
一些关于这个模型的批评 但其实并不重要
- 当然,比起我相对简单粗糙的计算,别人有可能能够得到更优越的先验值。还有很多可以加入考虑的预测因子,如男性的年龄,健康因子等等。
- 每个月受孕的概率本应被视作一个不确定的值而不是一个固定值,而我把它设为了固定值。但是在拥有的给定数据很少的情况下,我将其视作一个适用于多个参数的参数值。
- 没有事物是完全符合正态分布的,两个经期间的天数亦然。这里我认为假设是适用的,但是还有比我的假设远要复杂得多经期间隔天数模型,比如 Bortot et al (2010)建立的模型。



原文网站: http://sumsar.net/blog/2015/11/a-bayesian-model-to-calculate-whether-my-wife-is-pregnant/
翻译:lan
作者:Rasmus Bååth
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

