领科云基于Mesos和Docker的企业级移动应用实践分享
本文由 李加庆 根据2016年1月24日 @Container容器技术大会·北京站 上 刘超 的演讲《领科云基于Mesos和Docker的企业级移动应用实践分享》整理而成。
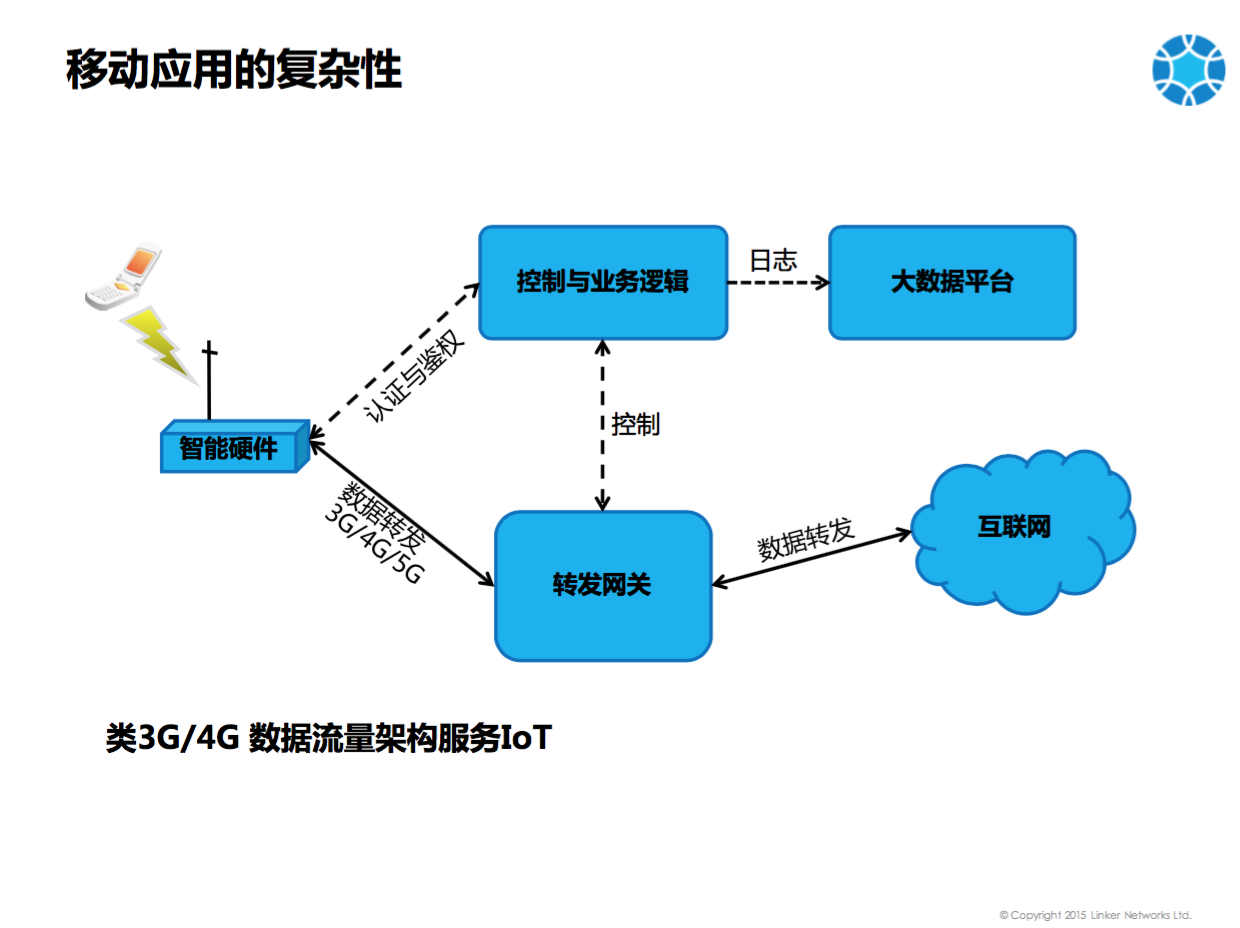
相对于普通的应用,移动应用更具复杂性。如上图,手机能连接到智能硬件,智能硬件对于手机端看来是一个 WIFI ,其实它是个 MIFI ,所谓 MIFI 后端连接的是 3G、4G 网络,手机通过 3G、4G 网络连接到控制与业务逻辑进行认证和鉴权,必须是合法的用户才能使用流量。当认证和鉴权通过后,及建立了数据通路,就会有数据流量转发,是通过转发网关进行的,转发网关部署在 Linker 的数据中心,通过转发网关进行转发的流量可实现流量的共享、流量的赠与以及流量的免流等。用户手机访问互联网,访问日志会进入大数据平台。这个架构类似于 3G/4G LTE 网络架构,只是经过简化,没有什么 SGW 、 PGW 、 MME 、 HSS 等。简化后的架构可应用于 IOT 即物联网,车载网这种场景。此类场景会导致我们的应用非常复杂,牵扯到各种各样的东西。首先要有手机连接智能硬件,另外我们业务逻辑使用JAVA开发,其次,考虑高吞吐量、高并发,转发网关使用C进行开发,最后大数据平台原来是用 Hadoop ,现在改用 Spark ,支持实时的数据处理。
如此类复杂的应用进行容器化,会有很多问题。在 Docker 化之前所有东西都是部署在 VM上 的。因为微服务化以及 Docker 化会使得应用更加轻量级、高性能、易部署,于是我们要将应用迁移至Docker,就会遇到一些挑战,例如 JAVA 平台高可用、高并发怎么做?程序宕机后如何自修复?Hadoop、Spark 如何复用数据中心资源?(Spark是用于处理实时的数据流,而 Hadoop 是批量处理数据,原来两个集群是分开部署的)。转发网关要求提供更高的吞吐量,容器如何实现?最具挑战的是智能硬件的远程更新与维护,因为硬件一旦发给客户,就无法收回更新。上述便是我们面临的应用复杂性,解决这些问题最终的思路是 Docker everywhere 容器无处不在。

上图是领科云的总体架构。底层支持 Openstack 、 Amazon 、阿里云等 IaaS 平台。原来将 DC/OS 部署在IaaS平台的时候使用 Ansible ,因为给客户提供解决方案的时候,经常需要给客户部署一套进行联调。使用 Ansible 会遇到问题,就是客户的机器硬件环境千差万别,操作系统也不同,如果使用 Ansible,脚本必须经常改。于是我们将平台和应用全部 Docker 化,就可以用 Docker Machine , Swarm , Compose 进行部署。IaaS 平台基础上是 Linker DC/OS,Linker DC/OS 之上可部署大数据平台方面,Spark 和 Hadoop 都可以作为Framework运行在Mesos上,共享资源。还 Linker DC/OS 上还可以部署 PaaS 平台,用于管理 Java 应用,可实现应用的自发现,自修复,弹性伸缩。Linker 的 PaaS 平台是基于 Marathon 开发了 Linker Controller 。当前业界的容器编排的系统都是针对容器本身的,可以配置容器之间的依赖关系,但是很少有人关心容器里面的应用的相互关系,虽然容器启动起来了,并不代表容器中的应用配好了。尤其是在互联网场景下,应用会越来越复杂,经常需要相互依赖,相互发现,相互配置,这种场景当前没有很好的解决方案,我们就开发了 Linker Controller 管理应用的相互关系。再上面是 Marketplace Platform,可以通过 Drag&Drop托拉拽建立应用模型的方式设计和部署应用。
接下来分别介绍各个部分如何Docker化,以及Docker化过程中遇到的问题和解决方案。
首先是传统应用的Docker化,即JAVA程序的Docker化。此类服务在Docker化之前是部署在虚拟机中,不可能因为Docker化重写程序或者改变架构。所以必须要保证当前的业务架构不发生根本性的改变,在体验到Docker轻量级、快速部署、动态扩展的好处以后,然后再逐步进行架构的微服务化。我们原来的架构也是相对紧偶合的,Docker化了之后逐步进行微服务化,区分有状态服务和无状态服务,通过多轮迭代最终适应全部的Docker化。
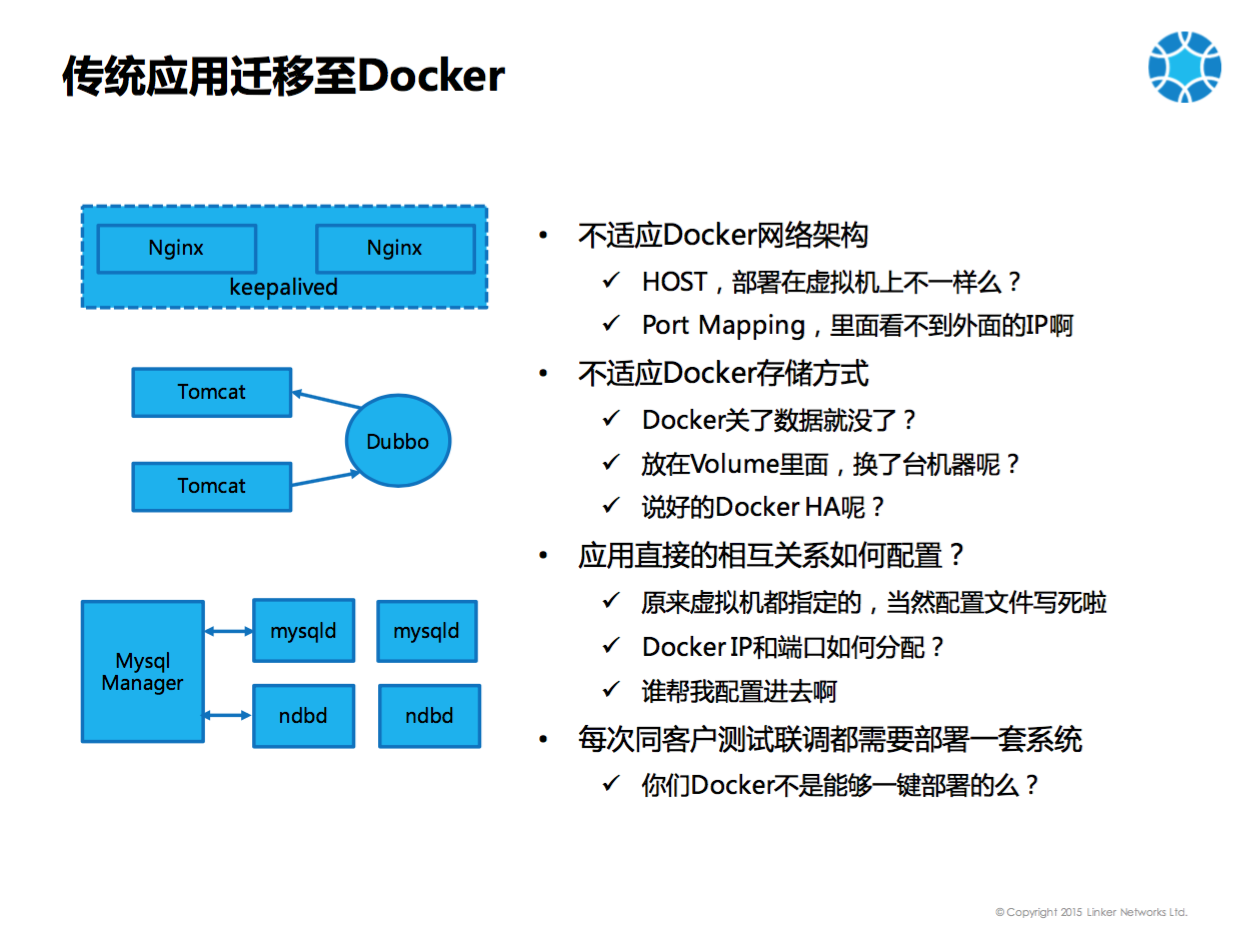
上图左边为传统的JAVA应用,最前端是负载均衡器例如Nginx。负载均衡器不能是单节点的,一般是双节点的,用Keepalived来保持VIP在两个Nginx间浮动及宕机时自动切换。核心部分是运行在Tomcat里的JAVA程序,程序的相互发现是用Dubbo框架。比如说A要调用B,那么B启动后注册到 Dubbo ,A从Dubbo中发现有B服务,A即可调用B。后端的数据库我们没有使用Mysql Replication,而是使用Mysql Cluster,包含Mysql Manager,Mysqld,和ndbd。
此类传统的架构Docker化的时候遇见了图中右面的问题。
第一:传统应用不适应Docker的网络架构。如果用HOST,则同一台机器上不可以部署多个相同的应用,会出现端口冲突。如果使用HOST和虚拟机有什么不一样呢?无法体现容器轻量级,可部署多套的优势。如果修改端口,便需要同时修改配置脚本,特别麻烦。如果使用Port Mapping,问题在于服务发现,Tomcat启动在Docker里面,只是获取Docker里面的IP,无法获取Docker外面的IP(宿主机的IP),无法将宿主机的IP注册到Dubbo。其他应用从Dubbo中读取的是Docker里面的IP,如果不在同一个主机上就无法连接。
第二:传统应用不适应Docker的存储方式。容器适合部署无状态的服务,Docker宕机后marathon再拉起,原来的数据就丢失了,对于传统应用来讲不可思议。所以数据应该存储在Volume中,然而一旦出现Docker迁移到另一主机,数据还是会丢失?
第三:应用之间的相互关系是如何配置。使用虚拟机部署应用,事先会创建很多虚拟机,虚拟机的IP就固定下来,配置文件也可以固定下来,每次部署IP不会变。Docker化后,每次Docker启动IP会变,对于不同的客户,不可能将所有的配置文件重新调整一遍。如果IP是变动的,相互关系的配置就更具挑战。
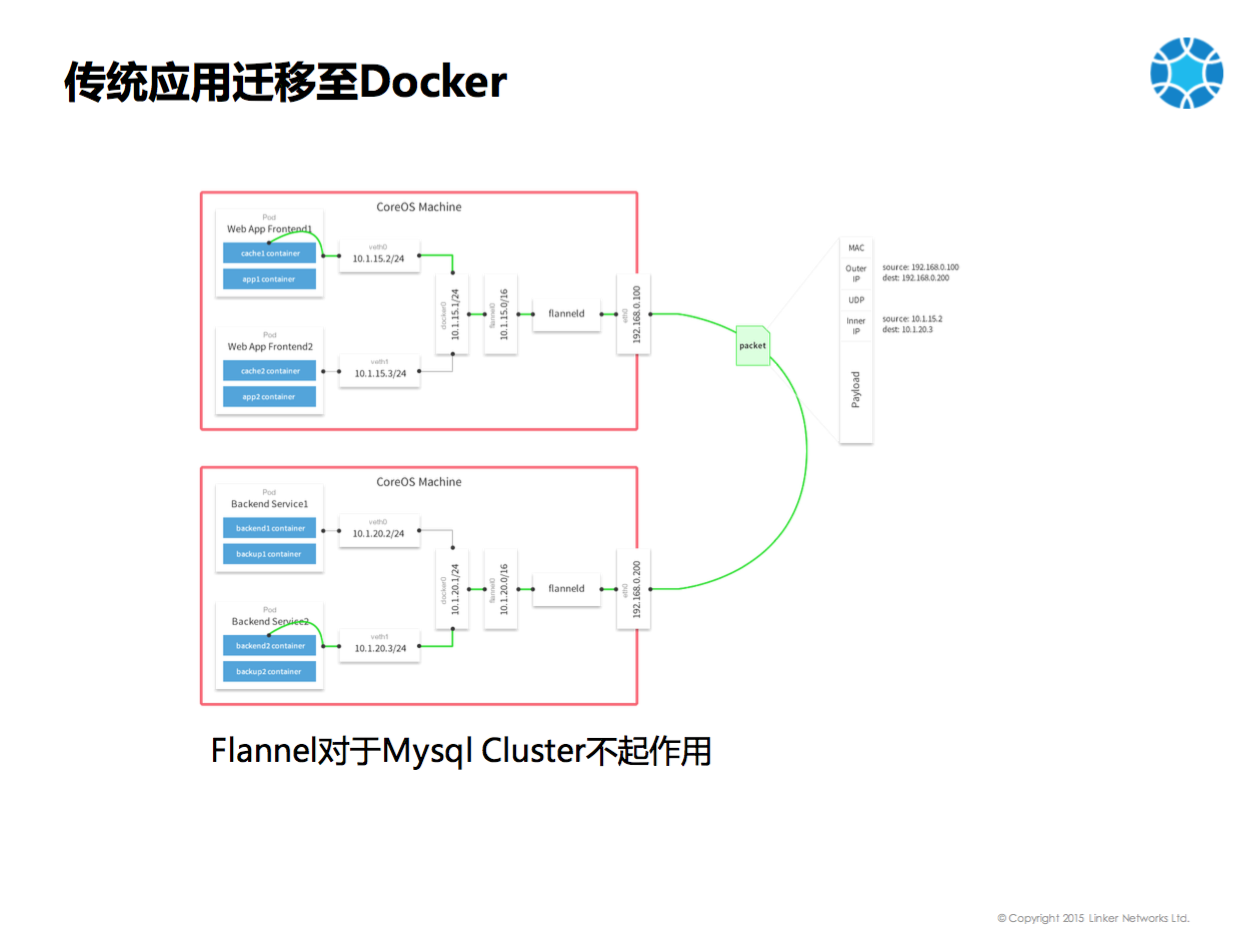
首先要解决的是网络问题,也即跨主机Docker之间的互联,当时 Flannel 比较火,是否可以解决我们的问题呢?但是发现Flannel对于Mysql Cluster不起作用。上图是一个Flannel的架构图,它是Overlay方式,具体说就是Docker里面有一个IP,从这个IP发出的包会通过宿主机上的路由表转发给Flanneld,Flanneld会将包进行封装加上UDP包头,发到另一台机器的Flanneld,做解封装后发给另一台机器上的Docker。这样一个Docker里面能够ping通另外一个Docker的IP。看起来这个架构是没有问题的,但是使用了Mysql Cluster的时候发现,Mysql Cluster是需要相互发现的,Mysql Manager需要确认注册上来的Mysqld是合法的,是通过包中的源IP地址是配置的合法地址才可以。然而Flannel发过来的包中的源IP地址不是源Docker里面的IP地址,而是10.1.15.0这个地址,Mysql Cluster不认为是一个合法的连接,就会拒绝连接,所以说Flannel对我们没有起作用。

我们采取的方式有两种: 方式一是在数据中心内部支撑自有业务的时候,使用用Bridged Flat Networking ,使用桥接的方式,把物理机上的Docker以及虚拟机的Docker全部拉平 。这种方式的优点在于,跨物理机的访问同传统访问没有任何区别,在Docker里面与在VM里面没有什么区别,性能损耗也会比较小。缺点是存在广播风暴的问题,如果集群特别大,应用全部在同一个二层,则会出现广播风暴。由于是内部使用,可以采取物理隔离的方式的,不同的业务搭建在不同的集群。如果使用Port Mapping的方式,从防火墙到服务器需要一次NAT,很多公司会部署IaaS平台OpenStack,然后OpenStack里面运行Docker,这时候 Openstack会有一个Floating IP,一般在数据中心里Floating IP并不是真的公网IP,因为公网IP特别贵。Neutron会将Floating IP做第二次NAT映射到虚拟机,然后虚拟机做第三次NAT映射到Docker。于是任何一次应用的访问需要三层NAT。如果使用这种 Bridged 的方式,则直接从防火墙一层NAT就可以。在物理机和虚拟机的选择上,我们的转发层使用物理机,控制层使用虚拟机,因为转发层可能是需要转发性能保证。 方式二是使用OVS和Weave,后来我们有了在线的平台,使用公有云和OpenStack,无法干预虚拟机的网卡配置 。当时Docker Overlay尚未发布,所以决定用OVS实现这个方案,OVS在不同的机器上通过GRE/VXLAN隧道打通。为了实现多租户的隔离,禁止配置非Managed IP,Docker桥接到OVS上的网卡的IP是Linker Controller分配的,非此IP的包则被禁掉。通过OVS的 Flow Table + Cgroup QoS,可以实现根据带宽做调度。
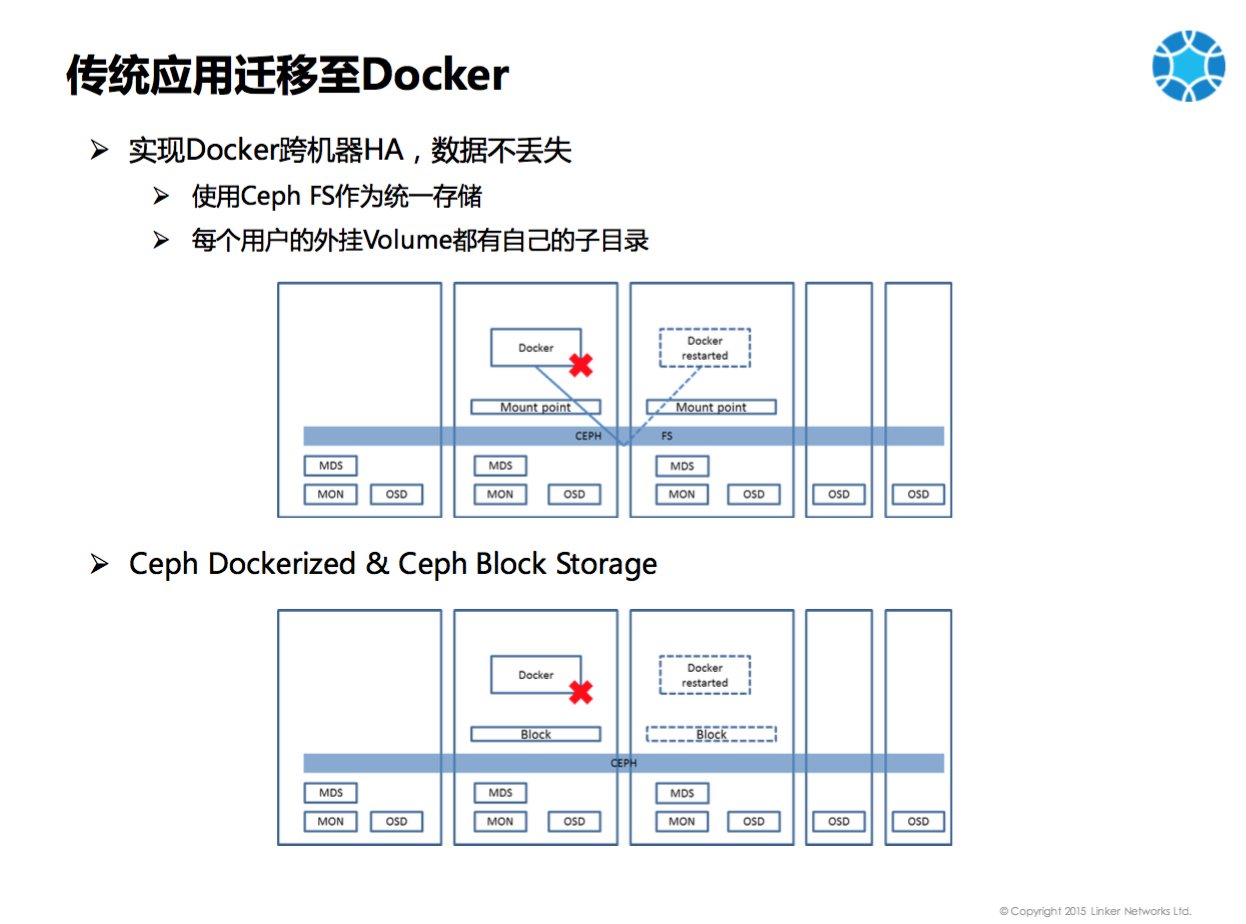
其次要解决的是存储的问题。实现Docker跨机器的HA,数据不丢失,我们选用Ceph作为共享存储。最初使用Ceph FS做统一存储,每台机器上都有Volume,把这些Volume打成同一个池,上面有个Ceph FS,两个机器上的Mount Point都能够看到相同的东西。A机器上的Docker写入Mount Point里的文件是写到 Ceph FS上的,当A机器上的Docker Crash,在B机器上启动后,可以从相同的路径读到相同的文件。后来我们改用 Ceph Block Storage,原因是有两个:一个是业内称Ceph FS不是特别的稳定。我们自己测试发现,积累的数据特别多的时候,写入的性能就会差一些。另一个问题是我们的Ceph也会Docker化,如果用Ceph FS,如果Mount Point在Docker里面的话,其他容器在外面无法访问。但是Block Storage是Mapping出来被其他容器访问到的。后来的方式是Ceph可以Mapping出来一个Block,就可以格式化为一个文件系统,Docker写入的是本地的文件系统,不用访问Ceph的MDS,而是使用Linux的VFS就可以了。当容器宕机后,本地的Block会Unmapping,然后到Docker迁移到的主机上重新Mapping出来,就可以访问到数据了。
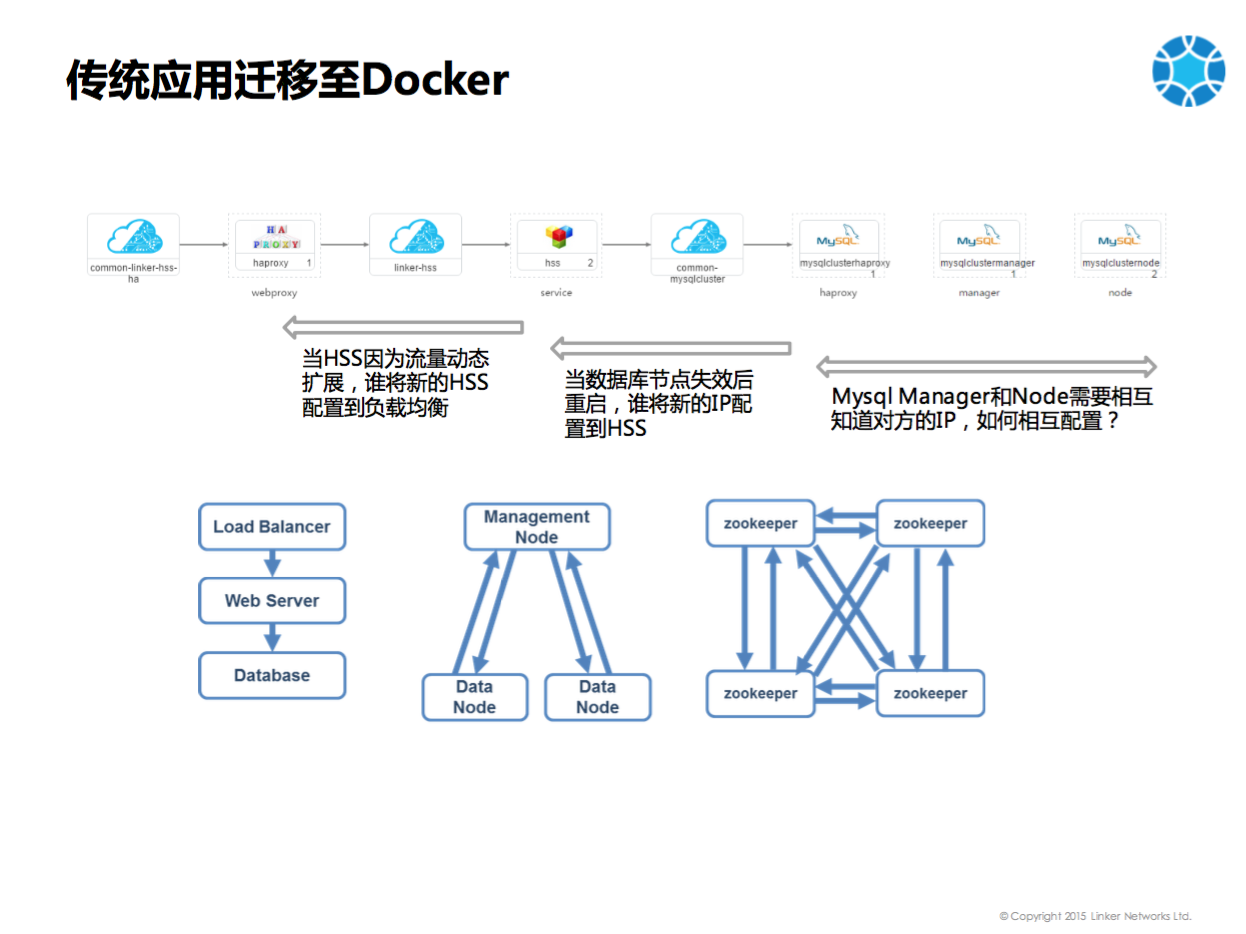
最后是相互关系的问题。随着互联网行业包括云计算发展,如上图最左边这种Load Balancer依赖于Web Server,Web Server依赖于Database这种简单的应用越来越少了。越来越多应用如Mysql Cluster和Zookeeper,都需要互相配置,互相发现,形成环形甚至网状的结构。对于这种应用,我们发现当前没有更好的方式去做,所以我们开发了一个基于模型的Linker Controller来做这件事情,我们借鉴了Puppet, Chef, Ansible等部署工具中Notify的方式,使得应用之间通过Notify修改相应的配置。
模型设计的第一个基本概念叫应用模型,所谓的应用模型就是一些原子模型,每个应用模型对应一个Docker Image,对于应用模型都会配置一些参数,如CPU、实例数量、镜像名称等。可以配置Linker的镜像,也可以配置Docker Hub的镜像,用户可以参考到Docker Hub上的镜像说明文档,按照文档上面的说明去配置参数即可。
有了应用模型,第二个概念是服务模型。服务模型是一个或者多个有相互依赖关系的应用模型的组合。举例来说,部署一个wordpress非常简单,只需要给这个服务模型起一个名字,然后设置这个服务模型依赖于wordpress,wordpress依赖于mysql,只需要把wordpress的应用模型拖拽进来,mysql的应用模型拖拽进来,服务模型就基本上配置完毕了。最后唯一要做的一件事情是,wordpress需要配置mysql的IP地址,只要在依赖关系中选择mysql,mysql的IP地址就会自动放入wordpress的环境变量中。最后保存并提交审核进行发布。这时候在Marketplace里面就能够看到这个服务模型了。用户点击订购,wordpress就会部署出来。所以想部署一个简单的wordpress,依赖于Mysql,根本不用写任何代码,也不用任何命令,只需要拖拽两下就可以搞定了。
wordpress应用是单向依赖的应用。还无法展示到这个平台的一些特性。对于相对复杂的应用,如zookeeper,每一个节点都要知道所有的其他节点的IP。一般Zookeeper采取使用Host的方式进行部署,如果部署在某三台机器上,这三台机器的IP地址事先就会就知道,创建Docker的时候,三个IP都传给环境变量,zookeeper集群就能正常启动了。但是我们的平台能解决一个扩展性的问题,也即可以从三个节点扩展到五个节点、七个节点。从三个节点扩展到五个节点的时候,如何让所有的节点获取另外的两个IP,这时候就需要大家去通知它,这需要一个通知的机制。我们从weave的命令行进入容器,就能看的5个IP全部配置进去了。
Docker化以后我们还可以CI/CD,大家通过这个系统还可以看到其实我们已经订购了CI/CD系统。包含的组件包括Gerrit, Nexus, LDAP等,这个CI/CD系统大家也是可以一点就直接出来,然后用户就可以直接使用了。对于创业的小公司,其实是非常好的。
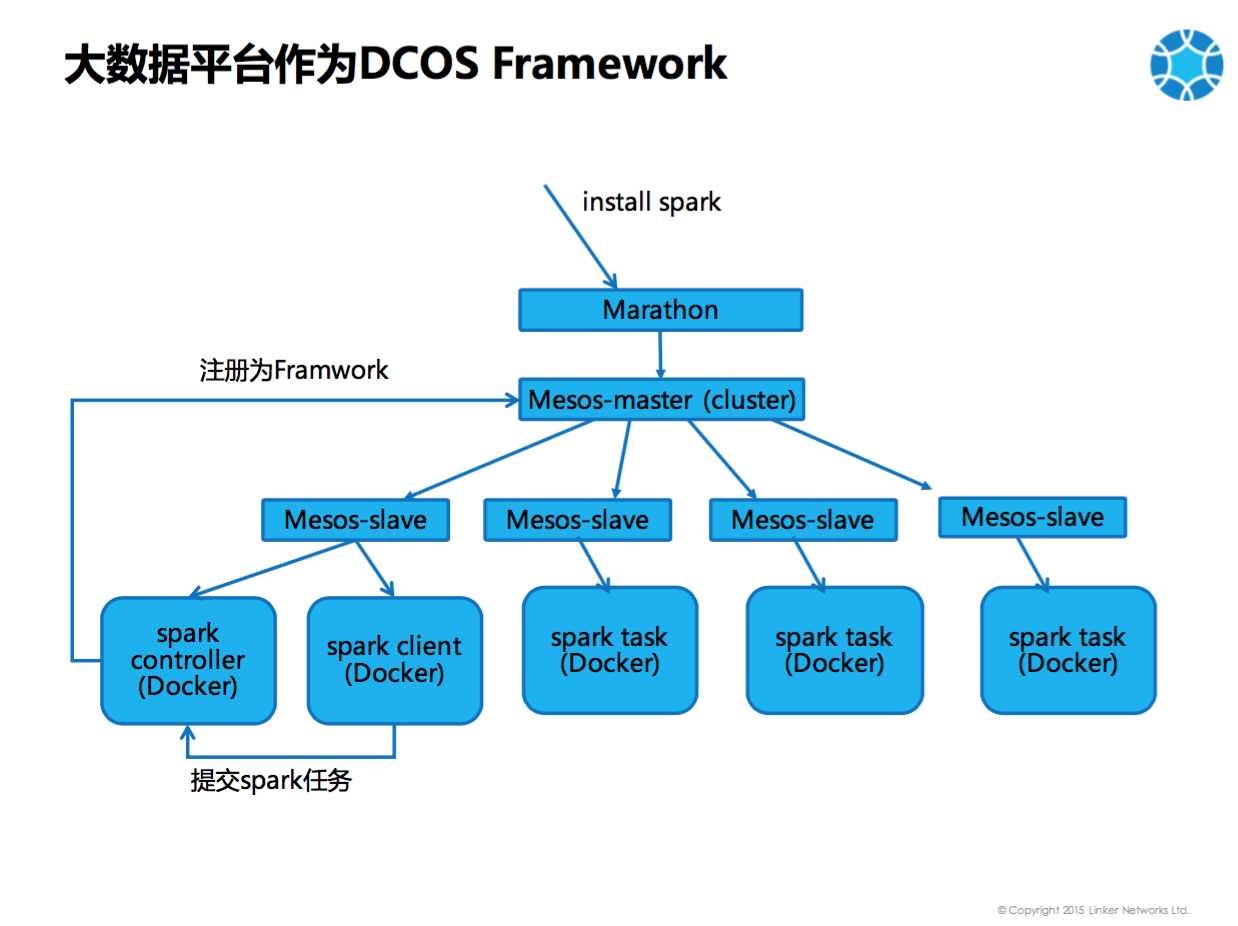
再就是大数据平台的Docker化。原来大数据平台需要手动部署,现在都是用DCOS的方式,基于Mesos的集群部署Framework。Spark和Hadoop都可以作为Framework共享整个集群。DC/OS安装Spark的方式为给Marathon发送一个Json,部署一个Docker,这个Docker会注册到Mesos master成为Framework,真正运行Spark的任务的时候就是远程对这个Docker发起指令,Spark Framework会告知Mesos说要执行spark的命令,那么Mesos就会把所有的东西下发下去,然后所有的Mesos slave就会执行spark的task。
再就是智能硬件的Docker化。JAVA程序和Gateway程序都Docker化了,大数据平台也Docker化了,最难做的就是智能硬件的Docker化,智能硬件的更新是比较复杂的。原来方式是有一个更新服务器,智能硬件可以通过3G、4G网络连接更新服务器。智能硬件上面会运行下列程序:监控程序、更新程序,转发程序,web界面,安卓程序等。每次更新需要保持这些程序的一致性,如果不一致则智能硬件就不工作。但是问题是如何保持一致?一个办法是每次都全部下载,全部重装一遍,因为你永远不知道用户的硬件状态,那么如何保持一致性就是一个很大的问题。另外一个问题是如何保持完整性。原来是用过MD5做checksum。还有一个问题是如果更新不成功如何回滚。回滚就比较困难了,采取的一些比较传统的方式,比如说有三个文件夹,update,running,backup来回倒,当前运行的是running,将来要更新的是update,正在更新的时候backup,backup不行,把backup拷回来再装一遍。最难解决的问题是如何更新新加的功能。更新程序只能写更新当前有的功能。
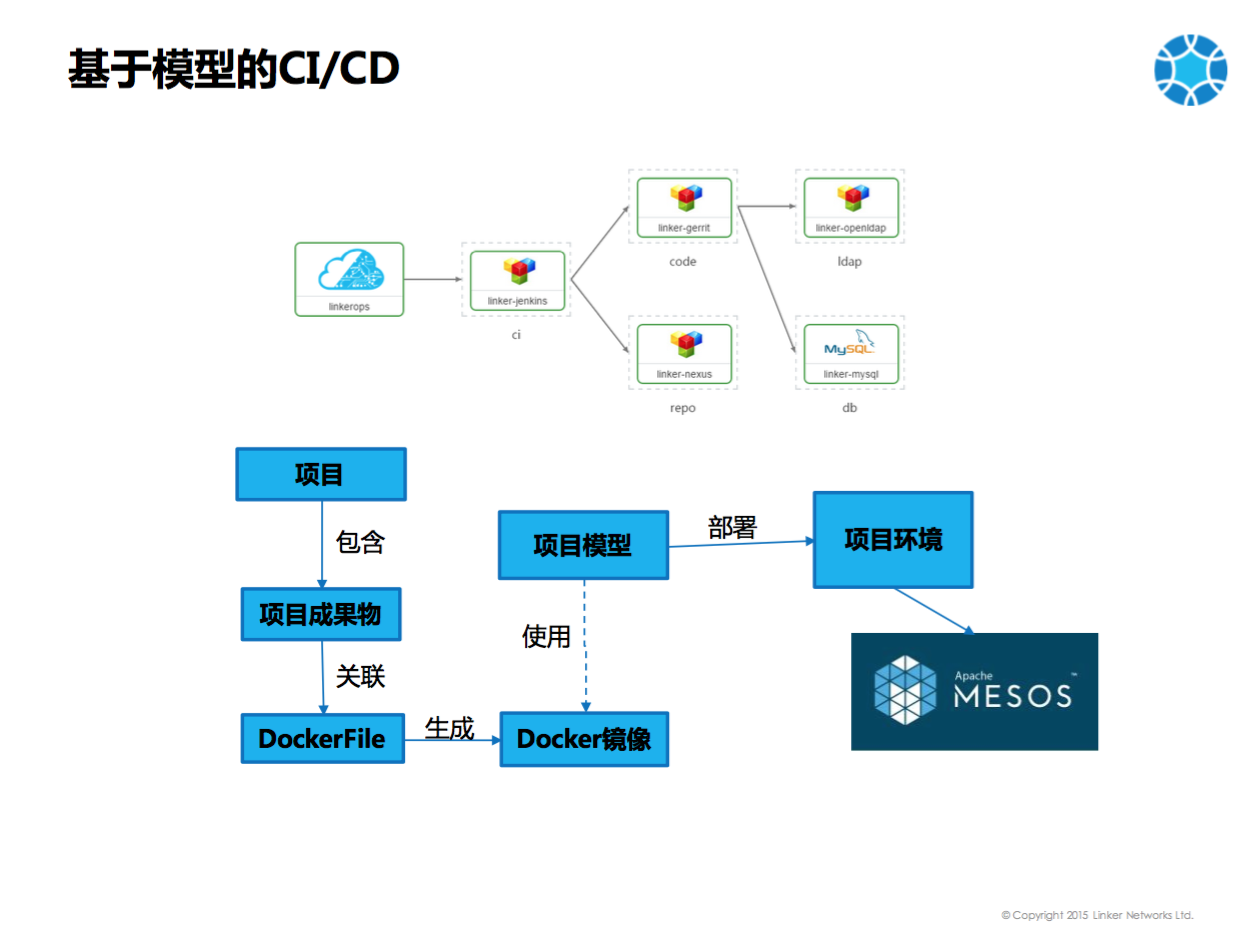
我们能不能用Docker?就是说在硬件的盒子里面装上Docker,采取上面这么一个架构来进行智能硬件的更新和管理。开发者可以把代码上传到Git Server上,因为硬件是基于arm CPU的,所以说不能在普通的X86平台上进行编译,需要用qemu。然后来模拟一个机器和一个arm cpu,把代码pull下来进行编译,编译成一个Image,放在一个Docker registry里面,这时候IoT Controller发现有更新了,就会去通知智能硬件,这个硬件就会把Image pull下来进行更新。这种情况下更新程序关心的,并不是里面的一个个的程序而是Docker。
有了Docker这些问题其实都能解决了,比如把所有的程序放在一个Docker里面,那么无论是从1.0升到2.0,其实你肯定能够保证2.0这个版本的一致性和完整性。回滚就很简单了,我们原来有个1.0,那现在升到2.0,如果2.0功能不正确,可以完全回到1.0,能确保回滚就是原来1.0的版本。另外可以更新新的功能,就是说我们本来只有A功能,现在突然想要有B功能,只要拉一个新的Docker下来就可以了。
再做一个简单的演示。在这个智能硬件盒子上插了一根线,上面是温度、湿度测试的这么一个仪器,能够把本地的温度和湿度测试出来。盒子里面有两个Image,一个是1.0,一个是2.0,1.0我们只能取到温度,我们模拟这种场景,这个模块既可以测温度,也可以测湿度,突然有一天除了测温度,还想再测一下湿度,那么就可以1.0升到2.0,那么湿度也可以测试出来了。
在我们把所有应用程序都可Docker化了以后,最后做的事情就是做领科云自身的Docker化。
核心组件Docker化,一是Mesos和Marathon的Docker化 。第二个就是使用Weave。第三个是Ceph的Docker化。所有东西Docker化了以后, 我们就可以Docker Machine和Docker Swarm部署整个集群。整个数据中心的部署将来给客户时是从一个Docker开始的,这个Docker里面安装Docker Machine, Swarm, Compose,先用Docker Machine创建出虚拟机并安装Swarm,然后Compose通过swarm部署marathon, mesos, weave, ceph这些核心组件。
原文 http://dockone.io/article/1620正文到此结束
- 本文标签: js zookeeper PaaS App dubbo Word update Hadoop git 集群 数据 智能 开发 http java 认证 网卡 cat 开发者 UDP 操作系统 公网IP 云 测试 ip 互联网 UI 代码 参数 主机 mysql 编译 tomcat 数据库 配置 IaaS 阿里云 ask ORM linux ldap db 创业 安装 OpenStack Docker src 物联网 wordpress 服务器 端口 map 管理 json 企业 下载 Nginx tab 负载均衡 sql 大数据 实例 Amazon ACE web
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

