一天几十亿条消息:Yelp的实时数据管道
本文翻译自: Billions of Messages a Day - Yelp's Real-time Data Pipeline ,已获得原网站授权。
这是关于Yelp的实时流数据基础设施系列文章的第一篇。这个系列会深度讲解我们如何用“确保只有一次”的方式把MySQL数据库中的改动实时地以流的方式传输出去,我们如何自动跟踪表模式变化,如何处理和转换流,以及最终如何把这些数据存储到Redshift或Salesforce之类的数据仓库中去。
在研发团队急剧扩张的挑战下,Yelp将系统架构转成了面向服务的体系结构( Service Oriented Architecture,SOA )。转型成功的提升了开发效率,但却引入了新的通信问题。为了解决这些问题,Yelp构建了实时流数据平台。
我们为生产者和消费者程序打造了标准平台,来让他们在彼此之间高效地、可扩展地传输流数据。程序通过通用消息总线通信,消息格式也是标准化的。这让我们可以把数据库的数据变更和日志事件传送到任何需要它们的服务或系统中,比如Amazon Redshift、Salesforce和Marketo等。
横向扩展的挑战
在2011年时,Yelp在“yelp-main”这一个庞大的代码库中就有超过100万行代码。我们决定把这一大块改造成SOA架构,到2014年底我们已经有了超过150个生产服务,其中100多个服务要处理数据。将“yelp-main”拆散让Yelp的研发团队和程序都得以扩展,特别是与我们的平台即服务(platform-as-a-service, PaaSTA )结合起来之后。
服务化并不是万能的,特别是在处理通信和数据的时候,服务还引入了新问题。
服务与服务之间通信
服务与服务之间通信很难扩展
梅特卡夫定律( Metcalfe's Law )表明,通信网络的价值与连接在网络中的通信节点数的平方成正比。套用到SOA上,就是说服务网络的价值和与它相连的服务数量的平方成正比。问题是,服务与服务之间通信的典型实现方式对开发来说并不算非常高效。
在两个通信节点之间实现RESTful的HTTP连接很难扩展。HTTP连接通常是用非常定制化的方式实现的,而且他们也几乎是定向的。要让Yelp的150个生产服务相互之间有效连接起来,就要建立起22350条服务与服务之间的定向HTTP连接。打个比方,这意味着每一次你要访问一个新的网站,你就要先拨一次号,在你的电脑和网站之间建立一条直连链路,这种方式低效得可怜。
故障时失效
除了复杂度,一致性也非常有问题。考虑一下数据库事务和服务通知:
session.begin() business = Business() session.add(business) session.commit() my_service_client.notify_business_changed(business.id)
如果服务调用失败了,那这个business的创建事件就永远没办法通知到服务了。这个可以被重构成:
session.begin() business = Business() session.add(business) my_service_client.notify_business_changed(business.id) session.commit()
可是这样的话commit又可能失败,结果这样又导致服务被通知到创建了一个business,可事实上又不存在。
变通方法也是有的。可以让服务自己来查看是否有新的business被创建了,也可以用消息队列然后再回调来确保business确实被创建成功了。可无论哪种方法都不会象看起来一样简单。在大型SOA部署中,很容易看到有多种这样的通知机制的实现方案,每种实现对问题的解决程度都不同。
跨服务处理数据很困难
约8600万是个魔法数字
在2016年3月Yelp就发送了上亿条评论消息。考虑一下问个问题:“我可以每天从你的服务拉取这些消息吗?”换种说法则是:“我想每秒钟向你的服务发送1000个请求,每秒钟都这样,一直持续下去,可以吗?”系统上规模后有了8600万个对象,这时候这两个问题是相同的。在系统上了规模后合理的东西都会变得不合理。业务数据量大会成为服务扩展的难题。
联接操作会特别难实现。“ N+1次查询问题 ”最终会变成N次服务调用问题,而且代码还不是作了N次查询,实际上是N次服务调用。大家已经非常了解“N+1次查询问题”了,很多ORM都已经内置提供了预先加载的解决方案。但并没有针对服务连接处理的现成方案。
如果没有现成的解决方案,开发者就会设计专用的获取大数据的API。这样的API设计不具有一致性,因为开发者是来自于不同团队、实现不同服务的。如果没有清晰的标准可依照,分页是特别容易导致不一致问题的。应用广泛的公共API也会有各种实现形式,从定制的回复消息到 HTTP链接头 都有。
要做分布式的服务联接操作就要你升级你的服务栈了。每一个拥有数据的服务和客户端库都有工作量。
有可能的解决方案吗?
第一个解决方案是开发者通常会设计获取大数据的API。当然,让每个服务为每种存储的数据都设计一个获取大数据API会耗费非常多的精力。很自然,设计一个通用的获取大数据API就呼之欲出了,让它接收原始的SQL,执行,再返回结果。不幸的是这非常严重地打破了服务的边界。这等于是连上一个服务的数据库去产生新数据,最终会导致分布式单体架构,而且也非常容易出问题。如果一个调用者想找一个服务获取数据,它就要对服务内部的数据结构非常了解,而且要对服务内的数据变更步调一致的做响应,这就把调用者和服务紧密地耦合起来了。
对于分享大数据的一个可能的解决方案是周期性的为服务的数据库创建快照,并将快照分享出去。这种方案解决了大数据API的问题,但又引入了新问题,即增量更新数据是非常难以正确实现的,而获取全量更新数据又代价太大。快照还有个问题是如果没有一些底层解释代码的话,某些数据其实是无意义的,事情就更复杂了。打个比方,假如没有上下文,boolean标志位或者枚举类型压根就是无意义的。
一个通用解决方案
现在你已经明白问题的背景了,我们接下来从顶层设计的角度解释一下怎样使用消息总线和标准数据格式来解决这个问题。我们也将讨论一下把这两个模块集成进来后系统架构会是怎么样,这样的架构可以解决什么问题。
消息总线
从架构上看,消息总线看起来象是解决这些问题的一个良好开端。
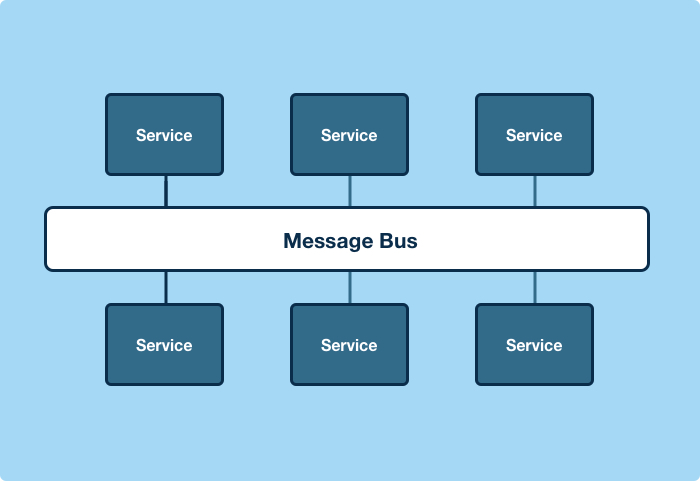
消息总线可以将连接复杂度从n^2降低为n,在我们的案例中是把22000个连接减少成了仅仅150个。
Apache Kafka 是一个分布式的、分区的、基于副本的提交日志服务,非常适用于这样的应用场景。除了速度快和可靠性高,它还有个对这种场景非常适合的特性:日志压缩。日志压缩功能会在一个非常简单的前提下整合Topic中的日志:保证对一个指定的Key来说至少有一条最新的消息一定会保存下来。这是一个非常有用的特性,比如你把数据库某张表中的数据变更都发送到一个Topic中,并且以表的主键作为Key,那回放Topic数据时就会取到数据库表的全部最新数据。
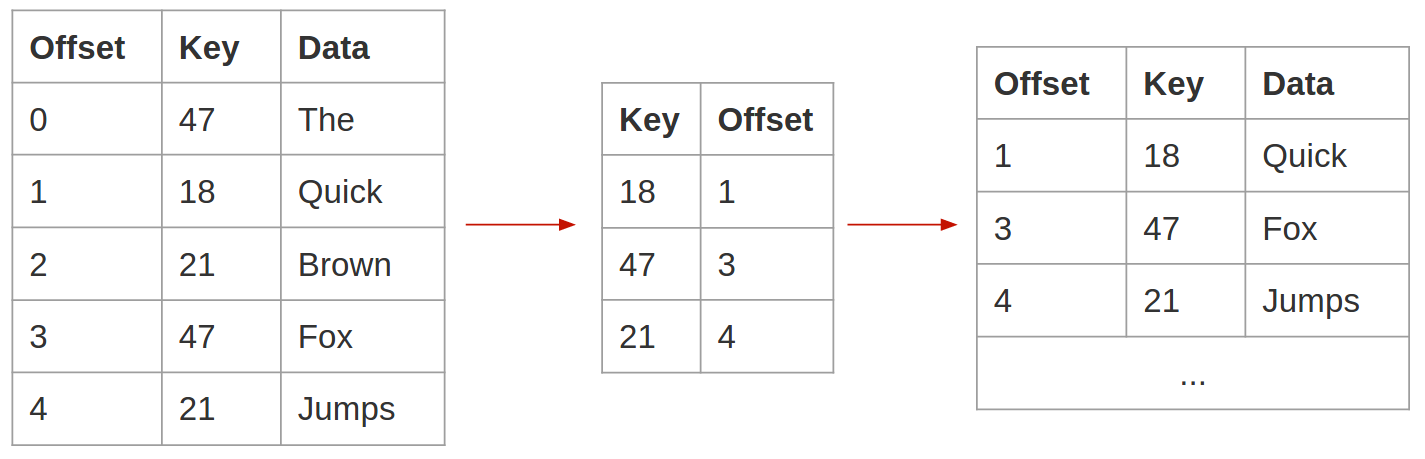
日志压缩技术会为每个Key至少保留最新的一条消息。
Jay Krep在他的文章“ What every software engineer should know about real-time data’s unifying abstraction ”中很好的阐述了流表二象性问题,这一点在 Kafka流文档 中也有所提到。日志压缩技术对这种二象性问题的处理可以帮我们解决非常多问题。我们可以提供流式的增量更新数据,这样就可以保证一个新的消费者在从头回放一个Topic中的全部内容时,最终会达到和数据库的表中一致的数据状态。在Yelp的数据管道中,这个特性让技术团队可以把数据变更以流的形式转换传递出去,最终应用到Redshift集群中。
解耦的数据格式
选择数据的传输方式只是解决方案的一部分。与之同等重要的是决定被传输的数据该使用什么格式。对于Kafka来说,所有的消息都是字节流,所以用什么消息格式对它来说无所谓。对这个问题第一反应应该是要用JSON,因为很多语言都支持它,而且很多语言的JSON解析实现都比较高效,还非常好用。可惜JSON有个致命缺点:非常脆弱。开发者可以在任何时候随意改变内容、类型或者JSON数据的布局等,但在分布式应用中很难评估数据改变造成的影响。更不幸的是,JSON的数据改变一般都是先被当成产品错误发现的,因此会导致紧急修复或者回滚,以及相应的后续问题。
Yelp的数据处理架构是树状的。我们的核心数据处理模块会产生中间状态的输出,然后被后续的各层、各个分支消费、再处理或再改造。上游的数据问题会在下游许多模块引发各种问题,甚至进一步引发上游的新问题,尤其是在错误不能被尽早捕获的情况下。这是我们决定改成流式架构之后想避免的问题之一。
我们最终选择了 Apache Avro ,这是一个数据序列化系统,有着诸多优良特性。Avro是一种非常节约空间的二进制序列化格式,Python等动态语言对它支持非常好,而且不需要生成代码。但对我们来说最重要的特性是它支持模式演进,这意味着在版本兼容的前提下,写程序和读程序可以用不同版本的模式来各自生产和消费数据。这就非常完美地把生产者和消费者解耦开了,生产者可以按需要迭代演进数据的模式,而不需要消费者亦步亦趋地跟着改变。
我们构建了一个名为Schematizer的HTTP模式存储,用于存储Yelp数据管道中用到的所有模式,这样我们就可以在发送数据时不必携带模式信息了。事实上,所有用Avro编码的数据报文都已经用有模式定义的消息头封装起来了,消息头包括消息UUID、加密细节、时间戳、报文编码所使用的模式编号等。这样程序就可以动态地在解码时再获取模式。
概要体系结构
当我们把数据传输和编码都标准化了之后,我们就不必再关心数据本身,从而可以构建通用程序了。
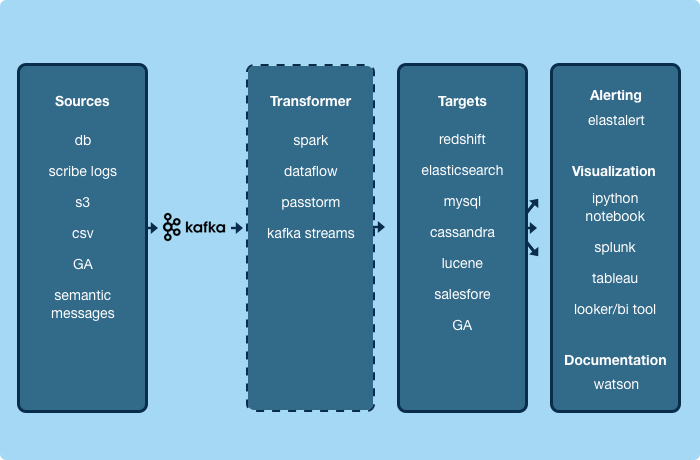
我们对日志系统生成的消息的处理方式是与对数据库复制或服务事件的处理方式完全一样的。再回到梅特卡夫定律,这样的架构提升了Yelp的流数据架构的价值,它与接入的生产者和消费者程序数量的平方成正比增长,接入的程序越多,价值越大。具体对于一个服务的生产者来说,这意味着当你产生了一个事件之后,无需增加任何代码,这个事件就会被存入Amazon Redshift、会存入我们的 数据湖 、会为查询需求增加索引、会缓存到Cassandra中、也会发送到Salesforce或Marketo。这个事件还会被任何其他服务或我们将来构建的应用程序消费,我们都不用做任何改动。
Yelp的实时数据管道
数据管道的概要体系结构给了我们一个可以构建流处理应用程序的框架。接下来的几节会讨论一下Yelp实时数据管道的核心设计,主要关注几个系统级选项,以及相对应的系统特性。在本系列的后续文章中将深度讨论具体的应用程序。
一套用于通信的协议
Yelp的实时数据管道从根本上来说是一套有了一定保障的通信协议。实践中,就是若干个Kafka Topic,Topic中的内容是被Schematizer服务处理过的。Schematizer服务负责注册和验证模式,Kafka Topic和模式之间关联起来。有了这些简单的功能,我们就可以做出很多强有力的保障了。
格式有保障
所有发布出来的消息都一定是符合某种模式定义的,而所有模式也一定是注册到了模式仓库中的。数据管道的生产者和消费者都根据模式来处理数据,Topic反而被抽象化了。模式注册是幂等的,注册完了的模式都是不可改变的。
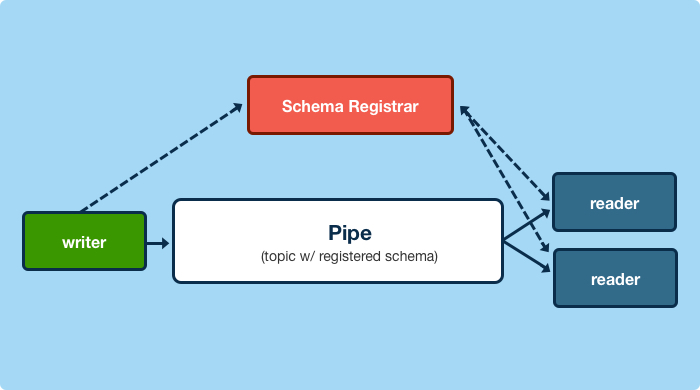
消费者在第一次碰到某种根据未知模式定义的数据时,需要并且只需要一次获取模式定义的操作,然后再根据模式定义去解码数据就可以了。
兼容性有保障
Schematizer的核心功能之一是将向Topic指定模式定义。Schematizer保证如果一个消费者开始按照某种模式从一个Topic中读出数据并解析后,那不管接下来上流的模式怎么变,这个消费者都仍然可以用手上的模式继续解析消息。换句话说,指定到一个Topic的任意有效的模式都必须保证它与这个Topic上的任意其他有效的模式是兼容的。不管模式怎么变,应用程序都不会出错。
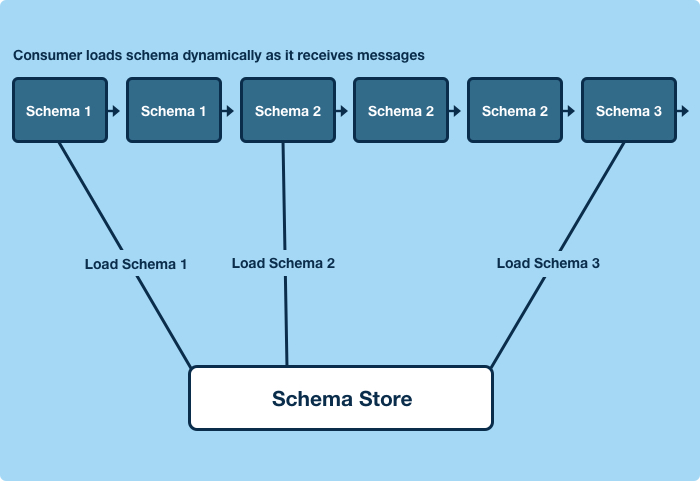
当Topic中出现了按某种没见过的模式编码的消息时,运行中的应用程序会去动态地获取模式定义。生产者可以自己改变它生产的数据的格式,不必要求任何下游消费者跟着改变。消费者会自动的获取新生产者写入消息的模式,同时仍会用手上的模式去解析已知数据。生产者和消费者的数据演进是解耦的。
注册有保障
数据生产者和消费者在生产或消费数据时都必须注册。这样我们就知道是公司内的哪些团队和程序在生产和消费数据,用着哪些模式,频率怎么样,等等。
生产者借此与它们的消费者协调一些重大的数据改变,可以在数据出错的时候做自动预警。如果必须要做不兼容的模式升级,生产者也因此可以提前与消费者进行协调。注册机制还让我们有了将过期的模式下线和废弃的方法。我们可以检测到什么时候某些模式已经不再被任何生产者使用了,可以协调消费者将它们使用的模式换成较新版的。注册机制简化了兼容性问题,因为我们可以人为地限制一个Topic中有效的模式数量,这样模式的兼容性问题就简化成了只需要与某几个现有模式兼容。
文档与数据属主有保障
Schematizer要求必须有文档解释每个模式中的每个字段,并且每个模式都必须要有团队来作为数据的属主。不能完整地提供这些信息的模式都通不过验证。文档和属主权信息会通过名为Watson的网站接口展示出来,在上面可以用和Wiki类似的方法添加文档和注释。
(点击放大图像)
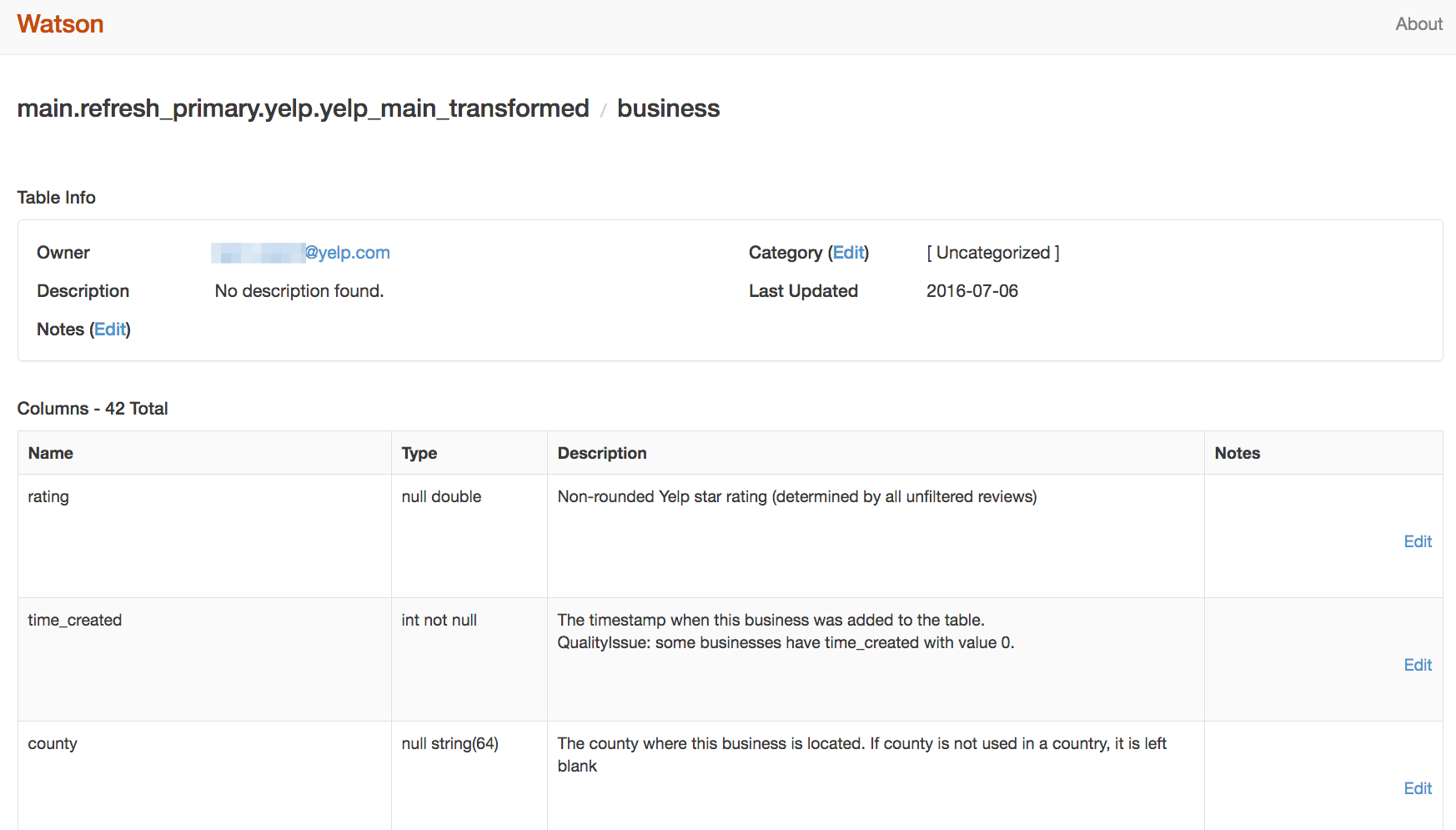
在许多情况下,我们都把这样的功能扩展到了可以自动生成消息和模式的系统中。比如,对于来源于数据库中表的模式,我们从代码库中抽取相应模型的注释和属主信息来生成文档。自动化测试可以禁止添加没有文档或属主的新数据模式,也禁止在不增加文档的情况下修改现有的数据模式。
Watson让用户可以公开地向数据属主提问,也可以浏览和联系数据的生产者和消费者。Schematizer也可以跟踪数据源端和目标端的情况,比如某个模式产生自一张MySQL数据库的表,数据流向一张Redshift表等。它可以动态的为数据源端和目标端生成文档视图。所以,为代码添加文档也就相应自动地为Redshift表、MySQL表和Kafka Topic等都添加了文档,这样的方式非常有效。
数据可用性有保障
如上所述,数据在服务之间传输的一个大问题就是处理大量数据的效率。借助于Kafka的日志压缩机制并为每条消息添加主键,我们就可以保证每个主键的最新一条消息可以被保存下来。
这个保障在捕获数据库变更的场景下特别有用。在把一个包含了数据库表的所有变更信息的Topic转换成表时,如果消费者把Topic中的所有信息从最开始一直回放到最新的实时状态,我们就可以保证它有了表中所有数据的最新值。而对于类似的提供增量更新的系统,就可以用于重建一个完整的镜像。文章“ All Aboard the Databus! ”描述了一种使用数据库变更流的情况,实际上就是在我们的标准架构中的一个通用生产者程序。
下一阶段
在本文中,我们讲述了SOA架构下碰到的通信和大量数据处理问题,并简介了Yelp为解决这些问题而构建的实时流数据平台的核心设计。我们介绍了在一些简单的保障前提下,如何使用消息总线、标准消息格式等构建出强大的、不关心数据细节的生产者和消费者程序。
请在接下来的一段时间继续关注我们,我们会深入剖析这个平台内部以及平台之上的一些程序,包括Schematizer和它的文档前端Watson、我们的“确保只有一次”的MySQL数据变更捕获系统、我们的流处理器、以及我们的Salsforce和Redshift连接器等。
这是关于Yelp的实时流数据基础设施系列文章的第一篇。这个系列会深度讲解我们如何用“确保只有一次”的方式把MySQL数据库中的改动实时地以流的方式传输出去,我们如何自动跟踪表模式变化,如何处理和转换流,以及最终如何把这些数据存储到Redshift或Salesforce之类的数据仓库中去。
正文到此结束
- 本文标签: 协议 开发者 需求 key http ORM apache js UI 代码 消息队列 src Service mysql ip 系统架构 API json client Action 自动化 sql SOA 解析 schema 处理器 tab 集群 RESTful Cassandra Amazon message 测试 网站 大数据 空间 开发 文章 定制 产品 PaaS 注释 分页 python 翻译 数据库 数据 时间 REST Architect 自动生成
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

