准确率更高的问答系统和概率程序语言
机器之心原创
技术顾问:赵巍、YanChen、石晶、张俊
作者:赵云峰
李磊是今日头条实验室科学家,原百度美国深度学习实验室少帅科学家。卡耐基梅隆大学计算机系博士,曾在加州大学伯克利分校作博士后研究。李磊博士的研究论文在 IJCAI 等学术会议上多有收录,如今正在召开的 ACL 2016 同样收录了李磊博士的一篇论文。机器之心近日对李磊进行了专访,在此篇专访中,他向我们介绍了被收录的论文,还有他对概率程序语言、自然语言处理方面的理解。
 李磊博士在 ACL 2016 现场,右侧是本篇论文
李磊博士在 ACL 2016 现场,右侧是本篇论文
一、关于 ACL2016 收录的论文

机器之心:首先能否介绍一下这篇论文吗?包括研究背景,研发方法,以及核心的 CFO 模型等。
李磊 :这项工作是我当时在美国百度深度学习研究院时开展的,当时 CMU 的实习生戴自航,百度 IDL 同事徐伟,和我一起合作,来了头条之后这项研究继续进行 。
首先,我们研究的问题是要解决知识类问答,比如说「美国总统是谁」、「哈利波特是谁写的」,它有别于更加开放和困难的通用问答。我们做的是整个问答系统中的知识类。知识类的背后有个知识库,我们用的是谷歌做的Freebase,解决的英文问题,但同样的技术也适用于其他语言的知识库上,只要有生成好的知识数据。
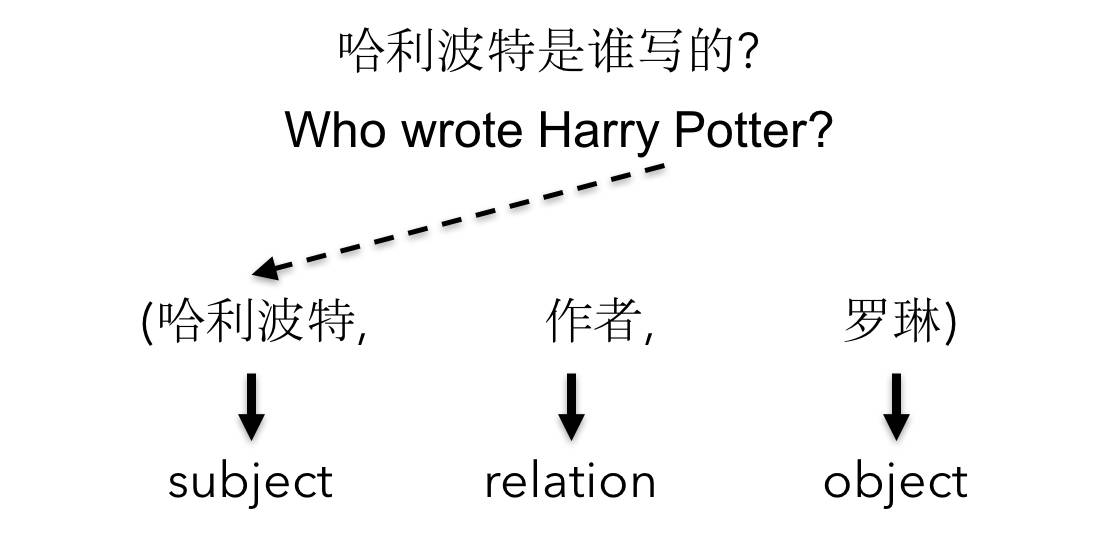
知识库里的信息表达成三元组形式,比如说有哈利波特、J.K.罗琳,以及两者之间的「作者关系」。但我们系统回答的问题实际上不是这种三元组形式(直接提三元组形式的问题比较简单),而是一个自然语言问题,比如说「Who wrote harry potter ?」。知识在知识库里表达成三元组形式的结构化信息,系统要做的事情是问了这个自然语言问题后,从知识库里找出这样的答案。
这个问题的难度在于,1)知识库非常大,经过筛选后还有 500 万实体信息、 7,500 组关系和 筛选之后的 2,200 万三元组事实信息(筛选之前是 19 亿事实)。因此,从这些海量数据中找出答案是非常困难的。2)除了知识库很大之后,自然语言的问题本身也比较复杂,因为有多种问法和表达方式。即使同一个问题,对于同一个实体和关系,也会有不同表示,同一个名字也会指向不同实体。比如说「哥伦布因什么而闻名?」这个主题有可能指发现新大陆的哥伦布,也有可能是俄亥俄州的哥伦布市,甚至是其他实体。3)而我们的训练数据是有限的,只有 10 万个标注数据(注:Facebook做的数据集),包括问题和答案,我们用了其中的 7 万来做训练,剩下的 来做验证和测试。
我们用的方法是深度学习方法加上知识库,我们的方法分为几步,首先,我们观察到,需要把自然语言问题表达成结构化 query ,这种query形式比较接近数据库里的SQL,也是选择一个什么样的 object 满足什么样的条件,我们需要把这个结构化 query 里的条件信息从问题里找出来,比如说 Harry Potter 对应知识库里的哪个实体(subject),我们需要把这个问句里的关系(relation)找出来,有了这两个之后,就能做一个结构化的查询语句,然后从知识库里找出答案。
举个例子,比如说「What theme is the book that amies of memory ?」,传统的做法是,为了找到实体,需要把这句话里所有的词都当成可能出现实体的集合,比如说 the book 是一个实体,theme、memory 等。但我们真正要找的实体是 amies of memory ,而且要知道这指的是那本书。如果按照传统方法,会出现很多噪音。
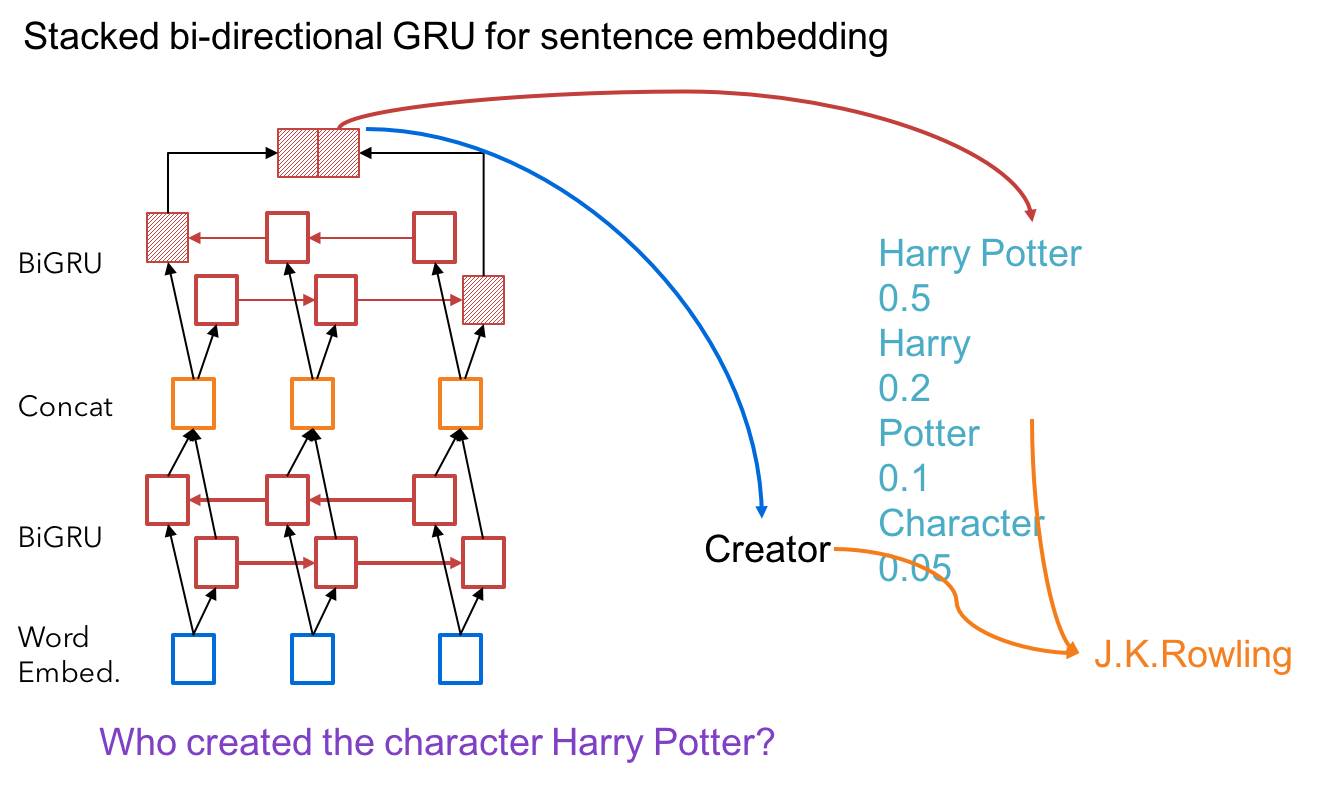
而我们的方法是通过神经网络,用了一个Stacked Bidirectional GRU ,它是一个上下叠加起来的多层双向循环神经网络,我们通过这个模型去计算出问题中的实体以及实体之间的关系,之后就是构建结构化的查询语句以及从知识库里寻找答案。
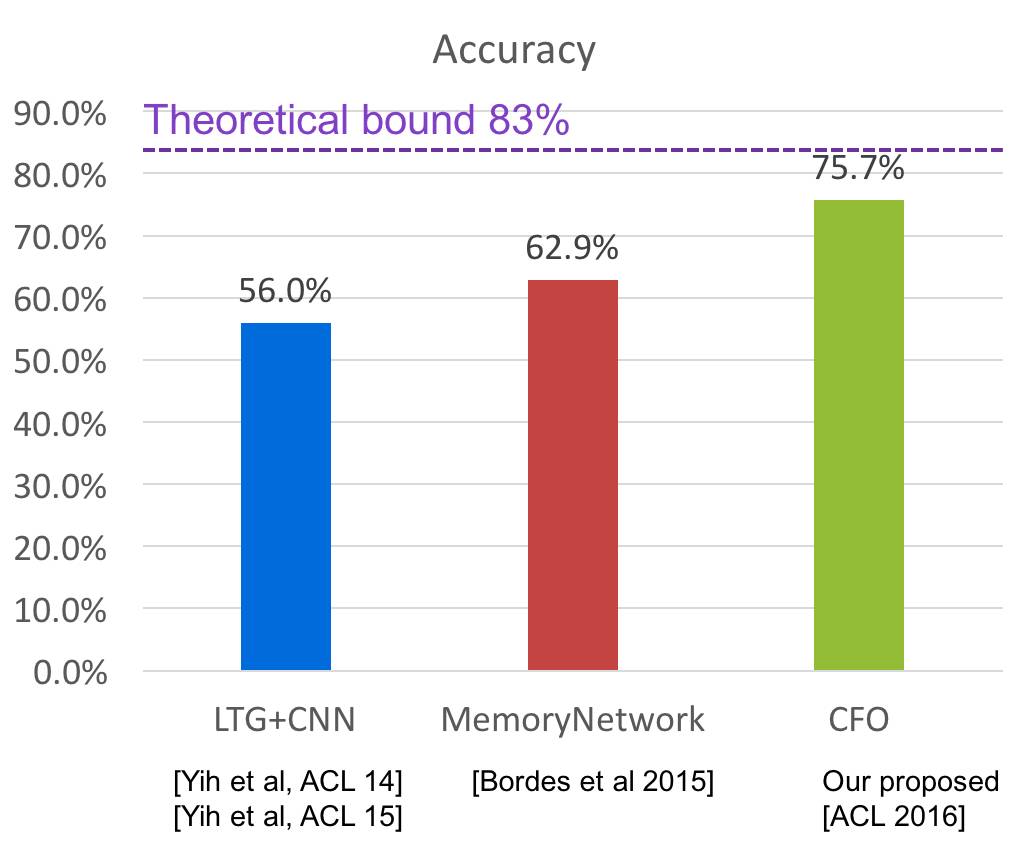
此外,在测试结果上,我们的准确率超过了微软和 Facebook。(见下图)
机器之心:这次提出的 CFO 方法会考虑上下文的语境理解吗?
李磊: 现在还没有用上下文信息,问题之间都是独立的。
机器之心:在整个模型的几个部分中,比如说 relation network 、subject network,词向量是共享的吗?
李磊: 并没有共享,但也可以做成共享的。另外,我们也基于额外训练好的词向量做了实验,发现效果差不多。
机器之心:在 relation network 中, 对问题用双向 GRU 建模的时候,在测试阶段是不是可能出现了词汇表以外的 unknown words(文章中提到有) 出现了之后,是怎么处理这些词的,随机初始一个相应维度的 embedding 吗?
李磊: 对 unknown words 我们是用了传统方法,特殊标记。
机器之心:注意到整个模型的不同部分之间的关联性,应该是比较拟合数据集的。最终选择的从 subject-relation 构建的查询,应该几乎都可以从知识库中找到答案(不论正确与否),是这样吗?
李磊: 如果这个问题的答案没有在这个知识库的话,是没有办法找到答案。但我们不需要知识库里的每个知识点都有人提过问题,比如说我问过「哈利波特是谁写的」这个问题,但从来没有遇到过「冰与火之歌是谁写的」这个问题,但它依然知道冰与火之歌是本书,而且知道要找的是两者的关系。
机器之心:把联合概率的求解近似为分步计算确实是极大提高了计算的效率。那么,更高层地,有没有考虑在 single-fact question 的基础上,做一些多轮的推理工作? 从某种意义上来说,都是一种链式优化的过程。
李磊: 多轮推理我们已经做了,我们现在也基于 CFO 的方法做了多轮推理,但论文还没发表。
机器之心:这项研究是在哪个平台上完成的?
李磊: 模型和运算用的是 Torch ,整个问答系统是 Python 加 Torch,再加存储查询三元组知识库的 Virtuoso 系统。
机器之心:论文中的方法其实是用神经网络等方法改进了传统问答系统 pipeline 的查询语句的 suject 和 relation 的选择。有没有考虑过用生成式模型自动来构建类似于 SPARQL 语句? 目前为止,端对端的模型是否还是比较难以在这种场合下应用?
李磊: 我们现在已经是生成式模型,生成了一个 SPARQL Query,只不过这个 SPARQL 是非常结构化的,实际上这是一个模板,我们只需要把模板中空的地方填进去就行了,而这些空的地方是通过我们的模型从问题里找出来的。
端对端还是有必要的,如果以后要处理通用问题,有些问题会有非常复杂的 SPARQL 问法,需要非常复杂的 SPARQL 语句才能问出来,在这种情况下就需要生成了,这也是非常难的。
现在流行的端对端训练的确可以优化整个流程里面的所有参数,同时获得新的数据后,非常容易对系统重新训练。但同时端对端的训练对模型里面的每一步都要求能够后向传输梯度。通过知识库来自动回答问题,实际上是一个多步决策过程,里面的每一步决策是离散的,包含的知识实体的搜索和候选结果排序,这里面通过反向梯度比较困难。更好的做法是通过强化学习(reinforcement learning),就是今年大红的AlphaGo的类似算法。如何更高效的做到搜索与排序统一的端对端的训练,这是一个非常值得研究的问题。
机器之心:接下来,这项研究成果会应用在今日头条的那些产品和功能中?
李磊: 今日头条有个产品叫「头条问答」,类似于 Quora 。我们希望对于一些简单的问题和事实类的问题可以通过自动回答的方式去解决,这样就可以节省专家人力。头条问答中还有大量复杂的问题以及观点性的问题,目前我们的方法还不能解决这些问题,但我相信这方面的研究是会在这类产品上有应用的。
机器之心:根据你的了解,其他问答类产品有用到类似的方法吗?
李磊: Quora 等比较难的社区类问答还没有用到,但像 Stackoverflow 这种就用到了机器学习,它不一定是直接回答,而是说可以去做推荐。比如,这个问题推荐给谁来回答,那就需要对问题进行语义理解,以及回答了之后怎么来评判这个答案正确与否,质量有多高。所以 Stackoverflow 上的问题就更适合用机器学习来做。因为这些问题通常比较具体,且答案唯一。
二、关于概率程序语言(PPL)
机器之心:能否解释一下概率程序语言的概念,它和贝叶斯网络、马尔科夫网络之间的关系?以及概率程序语言的研究进展?
李磊: 概率程序语言是 2013 年兴起的提法,这条线的研究非常多,从最早的贝叶斯网络开始,对于含有逻辑和不确定两部分内容的事件如何表示,这个问题从八十年代末到现在一直都有研究。
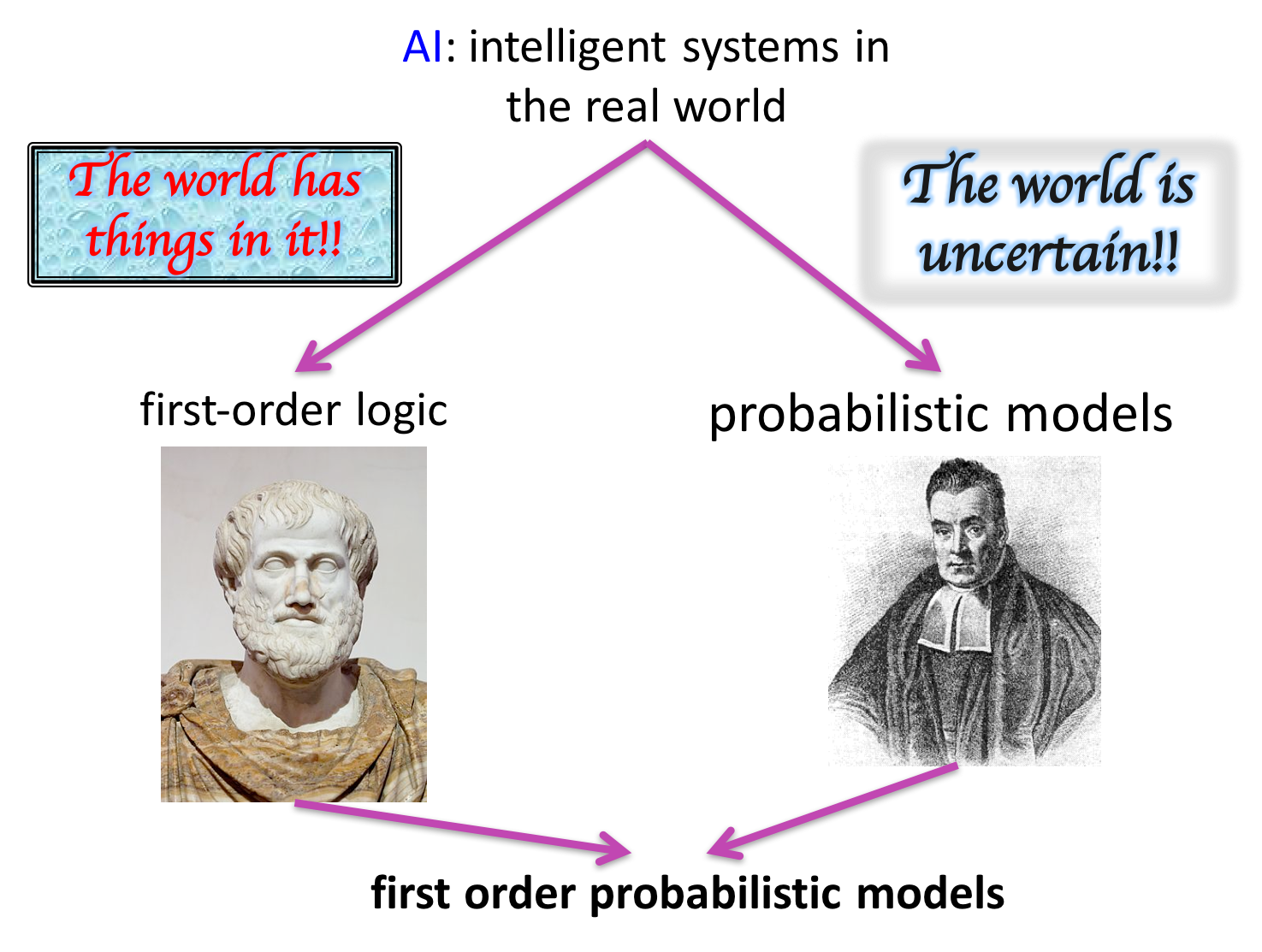
1)八十年代出现的是 Judea Pearl 提出的贝叶斯网络,他在 2011 年拿到了图灵奖。九十年代中期研究比较多的是逻辑编程,那时主要是基于逻辑规则的,当时有个很著名的编程语言叫 Prolog ,后来有人对它做了扩展,加上了概率,叫做概率逻辑程序(Probabilistic Logic Programming),把表达能力提升到可以去描述不确定事件。
2)2000 年到 2005 年前后,又有很多人把一阶逻辑和概率结合起来,因为一阶逻辑比传统的逻辑变成的表达能力还要强一些,这体现出追求表达能力的研究主线,最早的贝叶斯网络实际上是命题逻辑和概率结合,而一阶逻辑的表达能力比命题逻辑要强,后面要做的是把一阶逻辑和概率结合起来,这个叫做概率一阶逻辑。
3)这个发展到 2006 年,我当时的博士后导师 Stuart Russell(作者注:人工智能专家,经典教材《人工智能:一种现代方法》作者) 带领他的博士Brian Milch发明了贝叶斯逻辑 BLOG ,这不光包含了一阶逻辑和不确定,还融入了指代不确定性,比如「我知道这个屋子里有几个人,但我不知道他们是谁」。当时把一阶逻辑、概率和指代不确定三个东西都加起来,把概率程序语言方面的表达能力又提升了,从而发明了一种新的概率程序语言。
4)同期还有些其他语言,比如华盛顿大学在 2006 年提出的马尔科夫逻辑网络,也是把一阶逻辑和概率结合起来,但概率是用通过马尔科夫无向图来表示的;Joshua Tenenbaum和他的学生Vikash Mansinghka 和Noah Goodman在 2008 年发明的 Church,但表示方式是不一样的,这个语言也是非常通用的。
5)2012 年底 2013 年初,DARPA 把一些机器学习、程序语言和计算机系统的专家集中起来去探讨如何扩展机器学习技术,让更多的人去使用机器学习,我当时代表加州大学伯克利分校去参加。当时会议上提出来的一个新的概念就是概率编程(Probabilistic Programming),包含了之前的很多特例。概率编程的核心思路是给机器学习或者人工智能提供一个编程语言,它可以很容易的描述一些模型,同时自动为这个语言上的模型做概率推理和逻辑推理。一些应用方,比如社会学家、心理学家、经济学家和数据科学家,他们不需要特别深入的了解机器学习,只需要了解他们所在领域的问题,然后建立一个模型来描述人的认知,他就可以很容易的用这个语言去写一些模型出来,而且可以自动推理。建模的人不需要写非常多的程序去做计算和推理,因为通常这些部分都是比较难且耗时间的。这是当时提出的一个目标。
6)2013 年 DARPA 还发布了一个很大的研究计划(作者注:即 PPAML 项目,用于先进机器学习的程序编程) ,现在美国在概率程序和程序推理系统方面的研究是非常前沿的。当然,目前这个领域的研究还处在初级阶段,因为大家很有野心,一方面要把概率程序语言做的非常通用,能够去描述各种模型,不管是概率的,还是非概率的;同时又希望最后做出来的自动推理算法运算速度非常快,既要有表示性又要有高效性,这两个目标同时达到是非常困难的。
机器之心:之后,你还为 Blog 语言做了优化概率推理的 Swift 。

李磊: 在这个之前,大家做概率程序推理采用的方法都是通过解释型的,而我们是写了一个编译器对概率推理做优化,使得我能够为用户写出来的每一个模型专门做推理方面的优化,就像我写了一个 C++ 程序,用编译器可以对这个程序做优化,使它的计算速度可以非常快。如果类比一样,用 C++ 写的程序要比用 Python 写的快几十倍,同样,我们写的编译器也会比传统的概率推理快几十到上百倍。
三、关于知识表示、问答和自然语言处理
机器之心:知识表示是人工智能领域里的研究难题,你能否介绍一下这方面的研究进展?
李磊: 知识表示是人工智能最核心的问题,一般有五个框架。第一个是深度学习,它是用神经网络去逼近任何一个函数,这种表示方法在有监督学习里是非常有效的,尤其是在现在数据量非常大的情况下。第二类是基于概率图模型,比如贝叶斯网络和马尔科夫网络,这是去表达变量之间依赖关系的,不确定性。现在对这类框架又有了一些扩展,比如概率程序语言,可以表达既有概率同时又有逻辑的关系,将概率和逻辑结合起来去描述这个事件的不确定性。第三类是矩阵分解和稀疏方法,这种框架认为,表达每个物体需要多个特征,但并不是每个物体的所有特征上都有观测值,真实的表示可能是比较稀疏的,用稀疏模型去描述这个世界和物体之间的关系,这个在推荐里用的非常多。第四类是核方法(Kernel Method),它的核心是去描述两个物体之间的相似度,可以是用线性的方法和非线性的方法。最后一类是基于决策树,以及树的组合。这五类是从八十年代至今用的比较多的知识表示的框架,各有优劣。
具体到我们的这篇论文,我们在解决这个问题(知识类问答)是用的第一类深度学习的方法,我们在解决其他问题时也有用到概率图模型的。
机器之心:问答的发展离不开知识图谱,而目前知识图谱的构建又比较困难,你认为特定领域内的知识图谱有什么比较好的快速构建方法吗?
李磊: 我不是知识图谱方面的专家,专门做这方面的主要是研究信息提取,知识图谱还是比较困难的。那对于问答来说,并不一定依赖于知识图谱,后者只是其中的一个方法。但知识图谱确实非常有用的,在构建方面最近出现了一些新思路,比如华盛顿大学Oren Etzioni 提出了Open information extraction,CMU Tom Michell 提出了 Never Ending Learning ,不断去读网上的文本数据,希望从中抓出实体和实体之间的关系,然后每天不断的读,不断的积累 confidence ,这样对实体的信息获取就越来越多,每天都在进步,就像人在获取知识一样。
机器之心:问答和自然语言处理也有着密不可分的关系,你如何看待这方面的研究?
李磊: 我把自然语言处理问题分成简单任务和困难任务,简单的又分成两种,一是对句法结构进行分析,比如中文需要分词;另一种是浅层语义理解,比如说「从北京到上海乘火车怎么走?」,你把起点「北京」、终点「上海」找出来,把方式「乘火车」找出来,那整个句子的语义就理解了。这是浅层理解。
困难的任务包括机器翻译、阅读理解、对话、问答(问答是对话的一类),我认为可以把自然语言处理问题都归约成对话问题。
©本文由机器之心原创, 转载请联系本公众号获得授权 。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@almosthuman.cn
投稿或寻求报道:editor@almosthuman.cn
广告&商务合作:bd@almosthuman.cn
点击阅读原文,下载此论文↓↓↓
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

