超快的 FastText
Word2Vec 作者、脸书科学家 Mikolov 文本分类新作 fastText:方法简单,号称并不需要深度学习那样几小时或者几天的训练时间,在普通 CPU 上最快几十秒就可以训练模型,得到不错的结果。
1. fastText 原理
fastText 方法包含三部分:模型架构、层次 Softmax 和 N-gram 特征。下面我们一一介绍。
1.1 模型架构
fastText 模型架构如下图所示。fastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。fastText 在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数。

fastText 模型架构和 Word2Vec 中的 CBOW 模型很类似。不同之处在于,fastText 预测标签,而 CBOW 模型预测中间词。
1.2 层次 Softmax
在某些文本分类任务中类别很多,计算线性分类器的复杂度高。为了改善运行时间,fastText 模型使用了层次 Softmax 技巧。层次 Softmax 技巧建立在哈弗曼编码的基础上,对标签进行编码,能够极大地缩小模型预测目标的数量。具体细节参见 文章 。
1.3 N-gram 特征
fastText 可以用于文本分类和句子分类。不管是文本分类还是句子分类,我们常用的特征是词袋模型。但词袋模型不能考虑词之间的顺序,因此 fastText 还加入了 N-gram 特征。“我 爱 她” 这句话中的词袋模型特征是 “我”,“爱”, “她”。这些特征和句子 “她 爱 我” 的特征是一样的。如果加入 2-Ngram,第一句话的特征还有 “我-爱” 和 “爱-她”,这两句话 “我 爱 她” 和 “她 爱 我” 就能区别开来了。当然啦,为了提高效率,我们需要过滤掉低频的 N-gram。
2. fastText VS Tagspace
Mikolov 在 fastTetxt 的论文中报告了两个实验,其中一个实验和 Tagspace 模型进行对比。实验是在 YFCC100M 数据集上进行的, YFCC100M 数据集包含将近 1 亿张图片以及摘要、标题和标签。实验使用摘要和标题去预测标签。Tagspace 模型是建立在 Wsabie 模型的基础上的。Wsabie 模型除了利用 CNN 抽取特征之外,还提出了一个带权近似配对排序 (Weighted Approximate-Rank Pairwise, WARP) 损失函数用于处理预测目标数量巨大的问题。
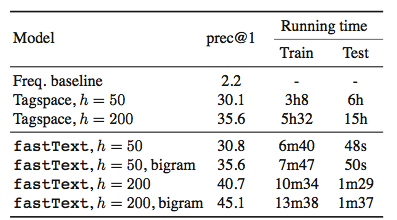
上面就是实验结果,从实验结果来看 fastText 能够取得比 Tagspace 好的效果,并拥有无以伦比的训练测试速度。但严格来说,这个实验对 Tagspace 有些不公平。YFCC100M 数据集是关于多标记分类的,即需要模型能从多个类别里预测出多个类。Tagspace 确实是做多标记分类的;但 fastText 只能做多类别分类,从多个类别里预测出一个类。而评价指标 prec@1 只评价一个预测结果,刚好能够评价多类别分类。
4. 总结
Facebook Research 已经在 Github 上公布了 fastText 的 项目代码 。不过这个项目其实是有两部分组成的,一部分是这篇文章介绍的 fastText 文本分类,另一部分是词嵌入学习。按论文来说只有文本分类部分才是 fastText,但也有人把这两部分合在一起称为 fastText,比如这篇文章 Comparison of FastText and Word2Vec 。fastText 的词嵌入学习比 word2vec 考虑了词组成的相似性。比如 fastText 的词嵌入学习能够考虑 english-born 和 british-born 之间有相同的后缀,但 word2vec 却不能。fastText 的词嵌入学习的具体原理可以参照 论文 。
好像大家对 fastText 吐槽甚多,比如在微博和 知乎 。
欢迎关注我的公众号,每周日的更新就会有提醒哦~

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

