Spark 2.0 Structured Streaming 分析
前言
Spark 2.0 将流式计算也统一到DataFrame里去了,提出了Structured Streaming的概念,将数据源映射为一张无线长度的表,同时将流式计算的结果映射为另外一张表,完全以结构化的方式去操作流式数据,复用了其对象的Catalyst引擎。
Spark 2.0 之前
作为Spark平台的流式实现,Spark Streaming 是有单独一套抽象和API的,大体如下
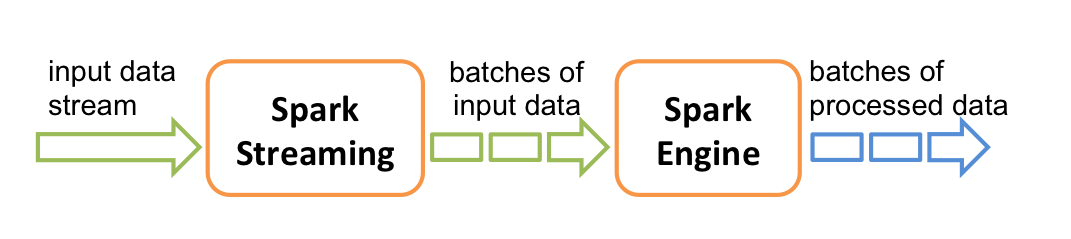
图片来源于Spakr官网
代码的形态如下:
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
//构建StreamingContext
val ssc = new StreamingContext(conf, Seconds(1))
//获取输入源
val lines = ssc.socketTextStream("localhost", 9999)
//逻辑计算
val wordCounts = lines.flatMap(_.split(" ")).
map(word => (word, 1)).
reduceByKey(_ + _)
wordCounts.print()
//启动流式计算
ssc.start()
ssc.awaitTermination()
上面都是套路,基本都得照着这么写。
Spark 2.0 时代
概念上,所谓流式,无非就是无限大的表,官方给出的图一目了然:
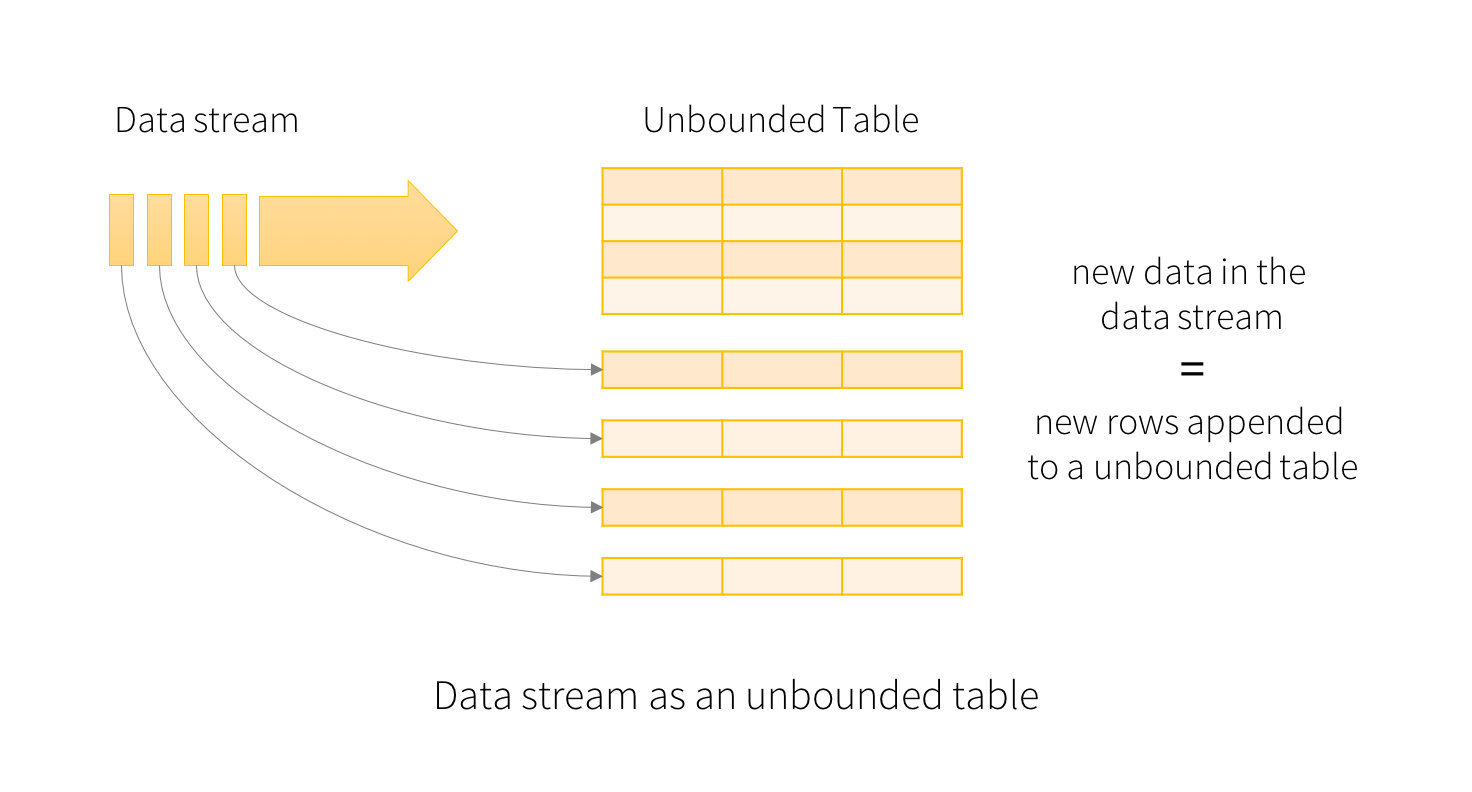
图片来源于官网
在之前的宣传PPT里,有类似的代码,给人焕然一新的感觉。当然,下面的代码你肯定要有上下文的,就这一句肯定跑不起来的。

图片来源于http://litaotao.github.io/images/spark-2.0-7.png
第一个是标准的DataFrame的使用代码。下面第二个则是流式计算的代码,看完这个demo你肯定会纳闷:
- 没有定时器么,我怎么设置duration?
- 在哪里设置awaitTermination呢?
- 如果我要写入到其他引擎,而其他引擎没有适配咋办?
这些疑问其实归结起来就是:
Structured Streaming 的完整套路是啥?
我们来看看代码(例子来源于 Spark源码 ,我稍微做了些修改):
val spark = SparkSession .builder .
master("local[2]") .
appName("StructuredNetworkWordCount").
getOrCreate()
val schemaExp = StructType(
StructField("name", StringType, false) ::
StructField("city", StringType, true)
:: Nil
)
//标准的DataSource API,只不过read变成了readStream
val words = spark.readStream.format("json").schema(schemaExp)
.load("file:///tmp/dir")
// DataFrame 的一些API
val wordCounts = words.groupBy("name").count()
//标准的DataSource 写入 API,只不过write变成了writeStream
val query = wordCounts.writeStream
//complete,append,update。目前只
//支持前面两种
.outputMode("complete")
//console,parquet,memory,foreach 四种
.format("console")
.trigger(ProcessingTime(5.seconds))//这里就是设置定时器了
.start()
query.awaitTermination()
这个就是Structured Streaming 的完整套路了。
Structured Streaming 目前Source源只支持File 和 Socket 两种。输出则是四种,前面已经提到。foreach则是可以无限扩展的。我举个例子:
val query = wordCounts.writeStream.trigger(ProcessingTime(5.seconds))
.outputMode("complete")
.foreach(new ForeachWriter[Row] {
var fileWriter: FileWriter = _
override def process(value: Row): Unit = {
fileWriter.append(value.toSeq.mkString(","))
}
override def close(errorOrNull: Throwable): Unit = {
fileWriter.close()
}
override def open(partitionId: Long, version: Long): Boolean = {
FileUtils.forceMkdir(new File(s"/tmp/example/${partitionId}"))
fileWriter = new FileWriter(new File(s"/tmp/example/${partitionId}/temp"))
true
}
}).start()
我把数据最后写到各个节点的临时目录里。当然,这只是个例子,不过其他类似于写入Redis的,则是类似的。
Structured Streaming 不仅仅在于API的变化
如果Structured Streaming 仅仅是换个API,或者能够支持DataFrame操作,那么我只能感到遗憾了,因为2.0之前通过某些封装也能够很好的支持DataFrame的操作。那么 Structured Streaming 的意义到底何在?
- 重新抽象了流式计算
- 易于实现数据的exactly-once
我们知道,2.0之前的Spark Streaming 只能做到at-least once,框架层次很难帮你做到exactly-once,参考我以前写的文章 Spark Streaming Crash 如何保证Exactly Once Semantics 。 现在通过重新设计了流式计算框架,使得实现exactly-once 变得容易了。
可能你会注意到,在Structured Streaming 里,多出了outputMode,现在有complete,append,update 三种,现在的版本只实现了前面两种。
- complete,每次计算完成后,你都能拿到全量的计算结果。
- append,每次计算完成后,你能拿到增量的计算结果。
但是,这里有个但是,使用了聚合类函数才能用complete模式,只是简单的使用了map,filter等才能使用append模式。 不知道大家明白了这里的含义么?
complete 就是我们前面提到的mapWithState实现。 append 模式则是标准的对数据做解析处理,不做复杂聚合统计功能。
官方给出了complete 模式的图:
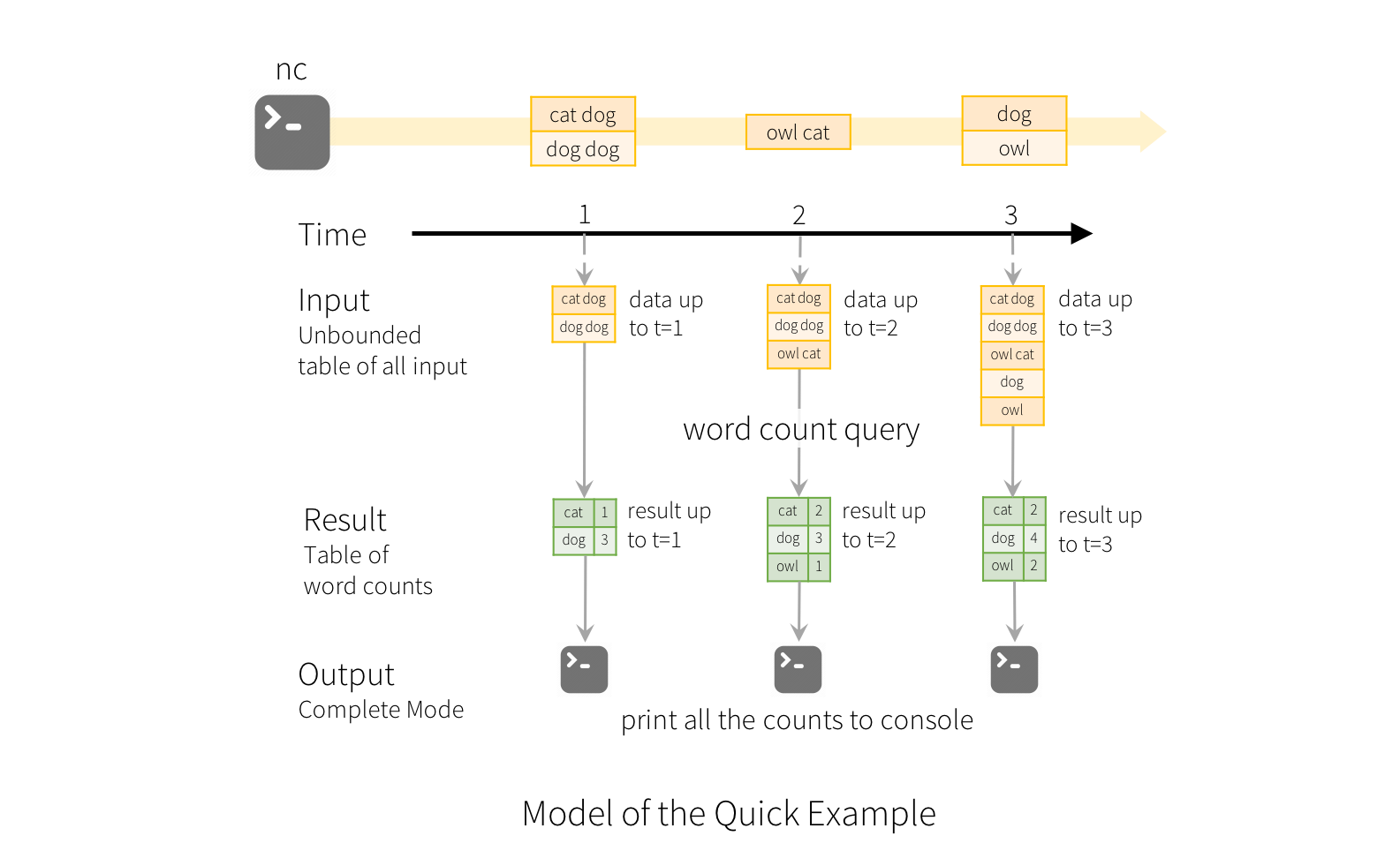
图片来源于官网
append 模式则是返回transform后最新的数据。
前面我们说到,现在的设计很简单,其实就是 无限大的 Source Table 映射到一张无限大的 Result Table上,每个周期完成后,都会更新Result Table。我们看到,Structured Streaming 已经接管了端到端了,可以通过内部机制保证数据的完整性,可靠性。
- offset 概念,流式计算一定有offset的概念。
- 对于无法回溯的数据源则采用了WAL日志
- state概念,对result table 的每个分区都进行状态包装,分区的的每个ADD,PUT,UPDATE,DELETE操作,都会写入到HDFS上,方便系统恢复。
其中第三点是只有在2.0才有的概念。不过比较遗憾的是,result table 和ForeachWriter 并没有什么结合,系统只是保证result table的完整性,通过HDFSBackedStateStoreProvider将result table 保存到HDFS。
以前的API就是给你个partition的iterator,你爱怎么玩怎么玩,但是到了现在,以ForeachWriter为例,
override def process(value: Row): Unit = {
数据你只能一条一条处理了。理论上如果假设正好在process的过程中,系统挂掉了,那么数据就会丢了,但因为 Structured Streaming 如果是complete模式,因为是全量数据,所以其实做好覆盖就行,也就说是幂等的。
如果是append 模式,则可能只能保证at-least once ,而对于其内部,也就是result table 是可以保证exactly-once 的。对于比如数据库,本身是可以支持事物的,可以在foreachWrite close的时候commit下,有任何失败的时候则在close的时候,rollback 就行。但是对于其他的,比如HBase,Redis 则较为困难。
另外在ForeachWriter提供的初始化函数,
override def open(partitionId: Long, version: Long): Boolean = {
返回值是Boolean,通过检测版本号,是否跳过这个分区的数据处理。返回true是为不跳过,否则为跳过。当你打开的时候,可以通过某种手段保存version,再系统恢复的时候,则可以读取该版本号,低于该版本的则返回false,当前的则继续处理。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

