My future of programming
正常的题目应该是 the future of programming 才对,
不过我知道我的套路始终是旁门左道, 很多人并不喜欢,
再者说, 编程探索的方向有很多, Cirru 只是很窄的一个.
大概在编译器, 文本语法, IDE 这些方向依然会是改进的主流.
半图形编程嘛, 太奇怪了, 而且也不通用, 也许就把人吓怕了.
但我还是想把自己的想法整理出来, 并且希望我是对的.
语法的烦恼
你可以暂且认为我有代码洁癖, 相信很多人也是有的, 而且各不一样,
其实我最初上手的 语言是 Python, 缩进的, 语法很简洁,
不管怎样, 我对 C 风格的语法一直有反感, 有着很硌脚的感觉.
于是我去思考怎么人类才能写更少的代码, 而完成对应的工作.
我的结论大概是, 代码的布局应该有算法来控制, 避免人类手写.
Cirru 出发点就是用 Canvas 绘制语法树, 然后直接编辑语法树,
现在为了方便使用, 实际上用了 DOM, 但还是尽量让布局更漂亮一些.
而这样的结构其实很契合 Lisp 的风格, 而同时使用自动布局算法.
所以这基本就是我对于程序的理解了, 写一棵语法树, 然后运行,
按照表达式增删改查, 而不是一个个字符一行还点啊, 而是有结构的操作.

文件的麻烦
"文件"这个概念已经在程序员脑子里深深扎根, 我要攻击, 恐怕是叛逆,
来看一些场景吧, 我说 Clojure, namespace 的用法,
namespace 跟文件是对应的, 所以, 其实两份信息, 一份是冗余的,
如果改变了文件名, 对应的 namespace 也就需要更改,
一般程序当中出现这种情况, 我们会设置函数, 响应式地修改第二个值,
但文件这种存在, 脱离于程序语法树, 无法被控制, 其实就是两个 scope.
这中间确实存在一些麻烦, 或者说冗余, 只是未必大家觉得严重.
然而站在我的角度看, 或者说, 逆向思维吧, 如果没有文件呢?
namespace 是管理代码的手段, 问题的本源是, 函数太多, 不方便管理,
如果没有文件, 我们有没有办法管理数量上百上千上万的函数名?
我觉得有, 它依然是 Group 的概念, 但是为什么一定要用文件?
比如你在浏览器收藏上千个书签, 可以用文件夹分割, 但不需要真的文件,
所以文件是可以被替换的实现, 仅仅是需要个 Group, 怎么样都可以.
而且, 如果我们能搜索, 比如 Google 当中那么多数据, 不用文件夹依然能找到.
所以真实的问题是, 大量数据, 怎样管理, 怎样查找?
程序是什么?
从文件的反思就衍伸到这个问题, 你究竟怎样看待程序, 程序是什么?
我们知道存在高级语言低级语言的分别, 知道编程语言和机器码的分别,
我还截而了一些图用来对比 http://weibo.com/1651843872/E...
首先 Quicksort 算法, 有个我完全看不懂的汇编的版本,
汇编对应的是 CPU 指令, 或者稍微高级一些, 包含简单的标记, 操作, 移动等等:

然后是稍微高级一些的 C, 函数的概念已经有了, 还有 for/while 的概念,
这就是结构化编程的开始, 这些常用的流程控制语句涵盖了大量场景,
同时我们不用一直思考底层的硬件究竟是怎样工作的, 只要知道程序的结构如何设计:

Ruby 引入了混合范式的抽象, 程序进一步简化, 这当中真的是混用的:
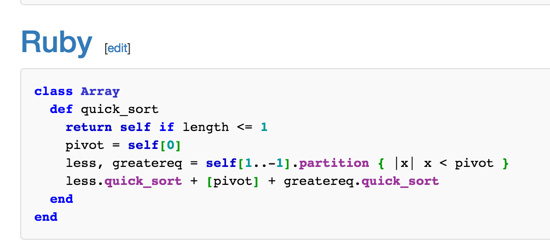
最后一个是我最佩服的 Haskell 的例子, 几乎是数学化的表述,
这是可以运行的代码, 性能尽管不高, 但是抽象之后完全不像是第一种了.

我想说的是 Quicksort 一个算法, 有那么多种程序的结构, 你想到了什么?
我对程序的理解
在我看来, 对于程序大家可以有着很多不同的看法, 完全可以,
也因此, 我觉得找到适合自己的一种抽象尤为可贵.
熟悉我的人知道我鼓吹函数式编程, 也就是偏向 Haskell, 虽然不彻底...
在我的眼里, 程序是数据之间相互依赖的关系形成的复杂结构,
怎么说, 我举一个 Clojure 的例子, 比如我的程序计算 c :
(defn c [a b] (+ a b))
那么这里的 c 依赖 a 和 b , 只要拿到两个依赖, c 就解了,
找一个具体的例子, 下载文件, 这中间依赖好几个步骤,
当所有的三个步骤完成, 那么下载文件的程序也就完成了.
而这里特殊的是, 它的依赖是用副作用写的, 而且限定了顺序,
(defn download-file [url] (request-file url) (save-file) (print-success))
也就是说, print-success 依赖 save-file , 而后者又依赖 request-url .
在 Haskell 当中副作用被封装, 这一点尤为夸张... 但确实这个道理.
还有一些并行计算的例子, 这种依赖关系还能派上用场..
所以我认为程序就是函数和数据等等内容依赖关系形成的复杂体.
因而推论就是, 我应该基于函数基于数据的依赖来编写程序,
这个说起的比较抽象, 但是写 Clojure 确实慢慢能积累这种感觉.
Stack Editor
Stack Editor 的理念, 主要基于函数来管理程序, 同时弱化文件的概念.
当你需要编辑函数, 你尽量通过函数之间的依赖关系之间打开函数,
你也可以把函数放在侧边栏, 方便在不同的函数之间切换,
而你不需要去管文件怎么创建, 函数摆放的顺序谁先谁后,
你要做的是定义好依赖关系, 而具体怎样保存, 那是编译器的工作.
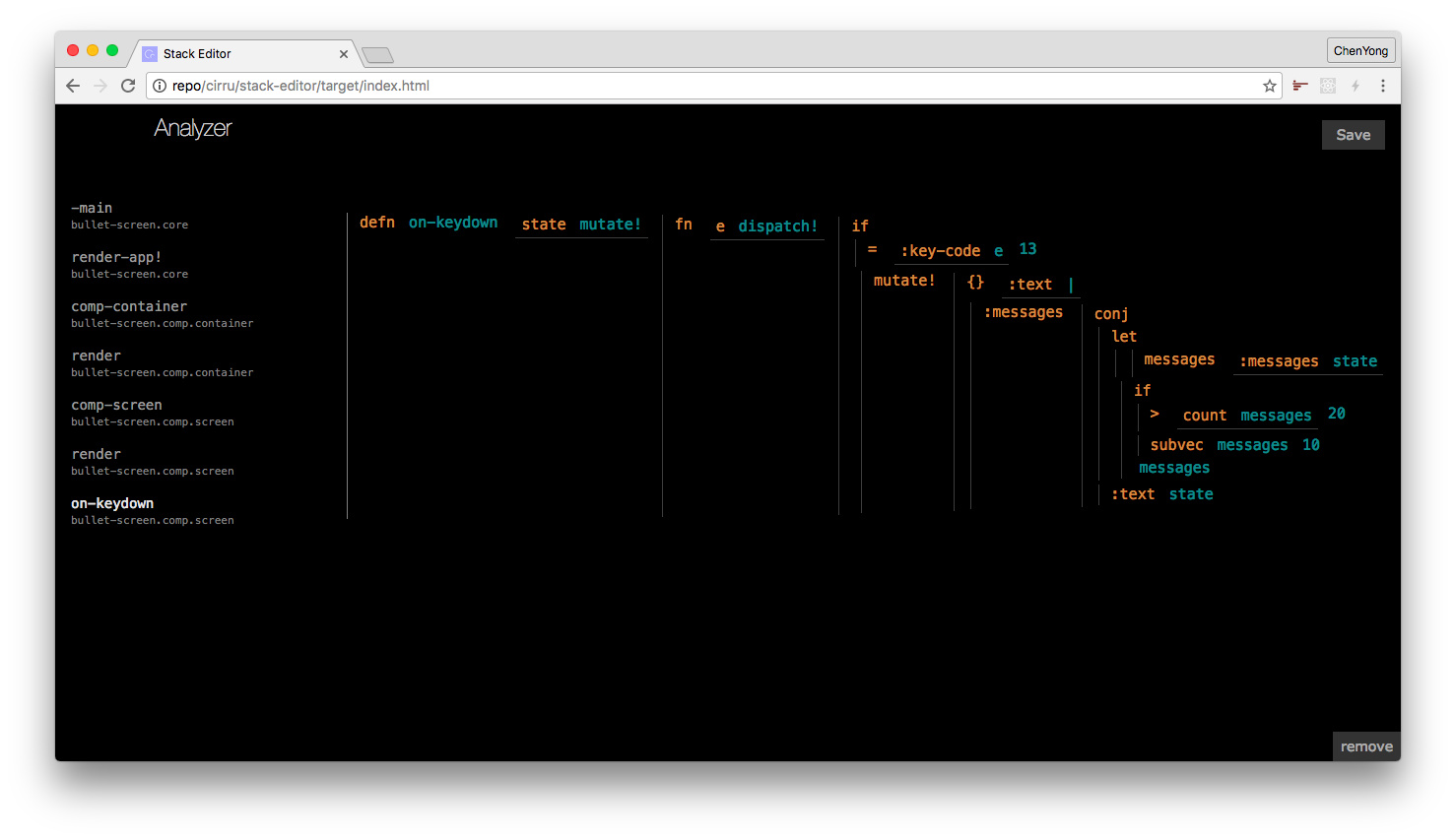
我知道根据依赖关系, 我们能分析出更多关于程序的细节,
编译器可以比我们更清楚地了解程序每一个细节, 从而给出指导.
这些未来依然能改进, 这个版本我当然还做不到的.
人脑的极限
还有一点非常重要的是, 我们需要了解自己的弱点在什么地方,
特别是面对机器所拥有的海量的内存和强大的计算能力,
人类大脑依赖的是神经元信号分析模式, 然后得出一些结果,
而越是抽象的内容, 越是需要消耗脑力去认为创建大量的联系,
很显然, 人脑并不是处理这类问题合适的计算单元,
而编程当中这类问题并不少, 特别是大型软件会遭遇的种种问题.
英文社区有篇文章归纳了一些, 我非常认同的作者, 大致列举了这些:
http://www.chris-granger.com/...-
Programming is unobservable
-
Programming is indirect
-
Programming is incidentally complex
关键的问题就是, 编程不像是我们日常当中遇到的可观可感的各类问题,
不像是几十万年来我们从生活中积累, 大脑适应去解决的那些问题,
流动在代码当中复杂的关系, 可以让一个没有经过编程训练的人束手无策!
因而我的看法, 应该尽可能把更适合机器处理的部分分离出来,
然后写成程序让计算机完成, 而人类尽量只做自己擅长的事情.
用工具去生成代码和管理函数只是开始的几个步骤,
我应该在未来会更多地思考图形编程相关的问题, 希望能给出一些成果.
可组合性
用用户体验的话说, 应该是"最小学习成本", 用户不需要学习额外的内容,
但放在计算机的领域当中, 做减法往往不能直接砍掉东西.
比如说编程语言 A 有一系列功能, 但为了简单, 不能说就直接去掉某些,
而是, 应该像是数学当中, 如果概念要去掉, 它应该是从其他概念推导得到,
那么, 就像 Scheme 的指定规范能制定出一个精简的版本, 而功能全面.
而达成这种目标, 就值得让每个单元都具备足够强大的组合能力,
这样, 才能最大限度地复用, 最大限度地用有限的元素组合出更多功能.
在我看来"一切皆是表达式"是非常重要的一个特性!
"一切皆是表达式"意味着每个单元都可以被组合, 可以在所有恰当的地方使用,
在命令式语言当中, 或者自定义的 DSL 当中, 往往这项功能是残缺的.
就像是数学, 数字可以扩展用在几乎所有的计算当中, 会计算就能上手新事物.
而这项特性一旦丧失, 当你面对新事物, 那就是全新的事物.
显然我们希望学到一个 x 就能拿 x 组合已有的 y 创造 x * y 中可能,
而不是一个 x 学完之后, 我们只有 x + y 中种新的手段.
考虑的未来编程会怎样, 我当然是希望向前者靠拢的, 带来更多可能.
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

