HEIST攻击解析:从HTTPS加密数据中获取明文
*本文原创作者:Sunnieli,本文属FreeBuf原创奖励计划,未经许可禁止转载
在Black Hat 2016大会上,两名比利时的安全研究人员展示了他们今年的研究成果。他们发现了一个WEB攻击方式可以绕过HTTPS加密得到明文信息。他们把这种攻击方式叫做HEIST攻击。HEIST的全称是Encrypted Information can be Stolen through TCP-Windows。
HEIST攻击的利用条件十分简单,只需要几行简单的javascript代码即可,并且无需借助中间人攻击。
原始的论文内容
接下来我会详细介绍论文中的内容
理论基础
Fetch API
关于Fetch API有两个比较重要的点:
1.Fetch API作为Cache,Service Workers等API的基础,可以获取任何资源,包括需要认证的跨域资源。
2.fetch()返回的是一个Promise对象,一旦Response对象接收到了第一个字节的数据,Promise对象就开始resolve,并且已经可以访问Response对象,这时候Response对象仍然会有数据流入。
Performance API
浏览器获取网页时,会对网页中每一个对象(脚本文件、样式表、图片文件等等)发出一个HTTP请求。performance.getEntries方法以数组形式,返回这些请求的时间统计信息。
攻击过程

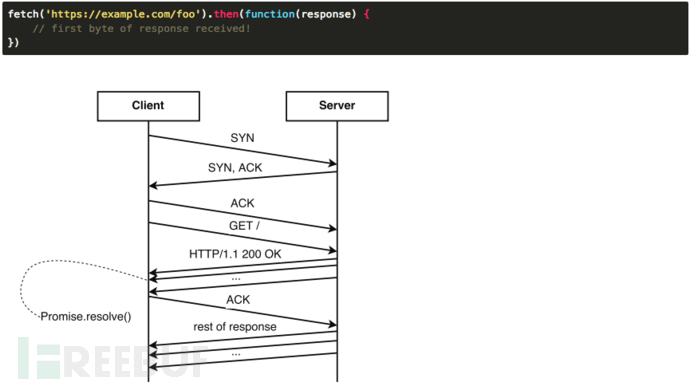
首先从TCP层看一下一个典型的HTTP请求,在三次握手之后,客户端发出一个包含请求的TCP包,通常只有几百字节,到达服务器之后,服务器生成一个response并发回给客户端。如果response的尺寸大于MSS(最大传输单元除去TCP+IP头,对于以太网来说是1460字节),服务器会将response拆成多个分组,这些分组会根据TCP慢启动算法来发送。
慢启动的算法如下(cwnd全称Congestion Window,拥塞窗口):
连接建好的开始先初始化cwnd = initcwnd,表明可以传initcwnd个MSS大小的数据。
每当收到一个ACK,cwnd++; 呈线性上升
每当过了一个RTT,cwnd = cwnd*2; 呈指数让升
还有一个ssthresh(slow start threshold),是一个上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”(这里不涉及这个算法)
Linux 3.0之后把cwnd初始化成了10个MSS。
通过fetch(),我们可以知道第一次TCP数据返回的时间,如果我们再知道数据完全返回的时间,我们就能知道数据是一次TCP返回的,还是多次返回的。
这时候就要另一个Performance API来配合,通过资源的responseEnd来得到资源完全下载需要的时间。
我们把发起请求的时间记为T0,第一次TCP返回时间记为T1,完全接收时间记为T2。如果是一次返回的,那么T2-T1将是一个很小的值,通常在1ms内。如果是两次及以上的,时间会明显增加很多。
这时候看起来还是没什么卵用。然而,下一步就是利用这一点得到response的确切大小(这个大小是经过gzip,以及加密过的)。
首先来看看一次返回的情况,很多时候一个请求参数在请求的结果里会有返回,然后就可以利用这一点。我们把response分为两部分,一部分是我们想得到的实际大小,一部分是攻击者控制的请求参数,暂且称之为反射参数吧。通过重复调整反射参数,我们可以得到第一次TCP返回的最大可能尺寸(对每个服务器来说一般是个固定值)。之后,只要减去HTTP和SSL/TLS的header的尺寸就可以了,而这两个都是可以预计的。
举例来说,当把反射参数调到708字节长时,正好可以一次TCP请求返回,而709就需要两次了,拿10*MSS(14600字节)- 528字节的http头 – 26字节的SSL/TLS头 – 708,得到response的实际大小为13337字节。论文里介绍了两种对该算法的优化方法,这里暂时跳过。
除了反射参数这种情况,还可以对目标网站发布大量不同尺寸的内容,通过调整正常的query参数来查看返回内容的大小达到同样的目的。
对于多次TCP返回的情况,会受到慢启动算法的影响,攻击者会向一个已知尺寸的资源发起一个请求,然后再向目标资源发起请求,服务器会将拥塞窗口提高。通过调整第一个请求资源的尺寸多次分析也可以得到结果。
接下来,只要配合BREACH/CRIME等攻击,就可以轻松获取E-mail地址,社保号等信息了,而不像BREACH攻击一样还要借助中间人攻击去得到资源的大小。
另外,在HTTP2下,利用一些新特性,这种攻击的情况还会更加糟糕。
CRIME/BREACH攻击
针对于HTTPS的攻击,多存在于中间人攻击的环境,攻击者要先能监听用户和网站之间的流量。
HTTP/TLS一般都启用了压缩算法,通过改变请求正文,对比被压缩后的密文长度,可以破解出某些信息。
HTTP压缩采用了Deflate算法。该算法可以将重复出现的字符串以一个实例的形式存储在HTML文件之中,并以此来缩小数据流所占的空间。当代码需要使用这一字符串时,系统会自动用一个指针来进行索引,这样就可以最大程度地节省空间了。一般而言,如果一个数据流中存在大量的重复字符串,那么这也就意味着在经过了压缩处理之后,可以显著地减少数据所占的空间。值得注意的是,Deflate算法是同时使用了LZ77算法与哈夫曼编码(Huffman Coding)的一个无损数据压缩算法。
CRIME攻击
CRIME通过在受害者的浏览器中运行JavaScript代码并同时监听HTTPS传输数据,能够解密会话Cookie,主要针对TLS压缩。
Javascript代码尝试一位一位的暴力破解Cookie的值。中间人组件能够观察到每次破解请求和响应的密文,寻找不同,一旦发现了一个,他会和执行破解的Javascript通信并继续破解下一位。
比如,攻击者可以构造出这样的请求

在secret=后面加上各种字符进行推测,当匹配到X的时候,密文因为被压缩会变的更短,就得到了第一位的X。依次往下推,就可以得到完整的cookie。
BREACH攻击
BREACH攻击是CRIME攻击的升级版,攻击方法和CRIME相同,不同的是BREACH利用的不是SSL/TLS压缩,而是HTTP压缩。所以要抵御BREACH攻击必须禁用HTTP压缩。
攻击防范
从上面可以看出,CRIME/BREACH攻击的条件都相对苛刻,而HEIST攻击则大大降低了其门槛,很容易被恶意广告利用。
HEIST攻击目前涉及到了浏览器, HTTP, SSL/TLS,TCP等多个层。
在浏览器层,目前修改Fetch API似乎是不太可能的,大概能做的只有禁用第三方cookie了,这样没办法攻击到一些需要登录或授权才能访问的资源。但对于依赖广告收入的谷歌来说,也不太会去触碰广告商的命根。
在HTTP层,浏览器可以禁止非法的请求(分析Origin或者referer,但可以绕过),server端可以通过关闭SSL/TLS压缩和HTTP压缩来避免CRIME/BREACH攻击,但是就无法享受到压缩带来的好处了。
在网络层,一种做法是将TCP拥塞窗口随机化,另一种做法也是类似,就是对返回的数据进行随机padding,但是也都是不太可能做的。
目前针对HEIST攻击暂时没有特别好的方法来防范,所以这类攻击方式在最近这几年或许会变得频繁起来。所以这两名研究人员也希望通过Black Hat大会一同寻找和制定一个合理有效的解决方案。
*本文原创作者:Sunnieli,本文属FreeBuf原创奖励计划,未经许可禁止转载
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

