小米人脸检测算法水平到底如何?看看业内人士怎么说
继百度深度学习研究院、腾讯优图以及Face++之后,小米最新的人脸检测算法日前也在业界最权威的FDDB数据集上拿下了第一的成绩。
根据小米联合创始人黄江吉公开的信息,小米此次研发的新算法基于深度卷积检测网络(Faster RCNN Bootstrapped by Hard Negative Mining),即利用深度卷积检测网络,同时学习人脸和非人脸特征,从而准确识别出人脸的位置和大小。
雷锋网 (搜索“雷锋网”公众号关注) 第一时间联系了参与这一项目的小米联合创始人黄江吉,他表示小米人脸检测改良了现有的方法,尤其是针对比较模糊的人脸有明显的优化,不过具体细节还要等到相关论文公布才能知晓。
当然,在此之前我们需要了解的是,人脸测试可分为人脸识别、人脸检测、人脸表情、人脸年龄、人脸性别等等,这其中人脸识别和人脸检测是最主流的两个方向。
人脸识别
人脸识别的目的就是找出图片中的人脸,然后识别人脸是谁,目前,全球人脸识别的数据集最多,如WebFace、MegaFace以及LFW(Labeled Faces in the Wild)等。LFW是人脸识别研究领域比较有名的人脸图像集,LFW库共有13233幅图像,其中5749个人,其中1680人有两幅及以上的图像,4069人只有一幅图像。
例如,Facebook Deepface、香港中文大学汤晓鸥教授的DeepID以及Face++都在LFW上进行了相应的测试。
人脸检测
事实上,人脸检测比人脸识别的任务要稍微简单一些,它只关注第一步,就是给出一张照片,找出有人脸的区域(椭圆型或矩阵)就完成任务了。
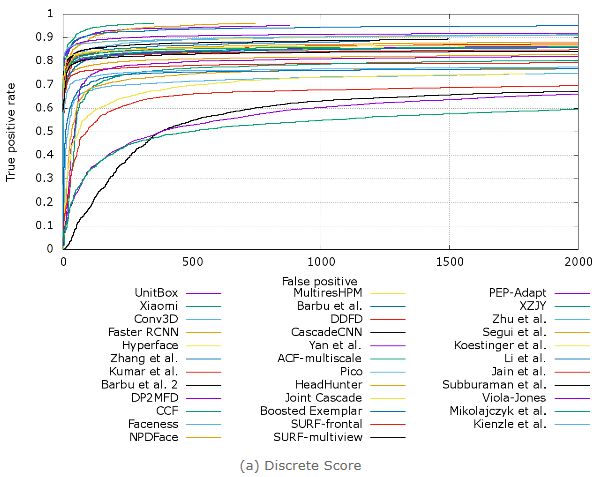
FDDB(Face Detection Data Set and Benchmark)是最具权威的人脸检测评测平台。FDDB和LFW一样,都是马萨诸塞大学的人脸数据库,它包含2845张图片,共有5171个人脸作为测试集。测试集范围包括:不同姿势、不同分辨率、旋转和遮挡等图片,同时包括灰度图和彩色图,标准的人脸标注区域为椭圆形。小米这次就是在FDDB进行测试的。

“检测和识别都是基于特征提取,检测相当于一张图上有足够多的选框(例如:20X20 的选框,各个像素点逐一筛选。)可先识别出人脸的位置,然后做选框,再根据选框内部的像素点逐一筛选。”宇泛智能CEO赵弘毅如是说。
通俗点讲,在图片上任意给出一个框,判断框是不是人脸,然后选框逐渐移动去判断是不是人脸。这个过程在学术领域称为“滑窗”,是特征提取的一个过程。所以,在一张图片中至少需要对几万个框做分别提取特征,从而来识别人脸。
FDDB的数据集,有人脸的位置都会用椭圆形框好。要求自动算法标识出来的区域和真实有人脸的区域,重叠部分(交集)对比并集超过一个阈值(例如50%),就算识别准确了。
那么小米人脸检测算法水平到底如何?
雷锋咨询了几位业内人士,一起看看他们是如何评价小米人脸检测算法的。
深图智服创始人吴鹏程:
FDDB数据集有两个组,一个是有公开方法的,另一个是没有公开方法的。小米这次特别厚道的把方法公开了,因此大家都可以去重现。
从结果看,他们在公开方法的组里,performance特别好,基本上和不公开方法的组里最好的很接近。
另外,小米这次也是改进了faster RCNN来做人脸检测,faster RCNN原本是孙剑(Face++首席科学家)提出来用来做对象检测的,国内不少用其来做人脸检测,包括我们自己,效果确实不错。
涂图科技CMO王楠:
技术指标只是一方面,还要看如何落地,因为难点都在商业化。
小米作为大公司有丰富的资源,BAT都在涉足这一领域,人脸识别还是最简单的一部分。
阅面科技创始人赵京雷:
模糊的图片会影响检测和识别的准确率,可以通过算法和数据等方式进行优化。小米所用的模糊人脸优化应该是刷了不少数据,FDDB刷数据大家都能做到,但实际应用如何又是另一回事了。
图普科技创始人李明强:
从这个评测结果来看,小米的人脸检测确实做得还不错,不过这个榜单中大家的水平都差不多,而且在LFW、FDDB甚至是ImageNet库中都存在统计误差。
宇泛智能CEO赵弘毅:
单一的刷榜单意义不大,国内有些企业就在FDDB这些数据集恶意刷榜单,但要注意的是人脸检测不仅要求精度还要速度。
另外还有业内人士告诉雷锋网,小米这一表现确实很优秀,但也不能说明什么问题。FDDB的库只有2000多张图片,而Wider库比它的照片数量多两三个数量级,而且单张图片多的有将近一百个人脸,虽然FDDB是主流的数据集,但没有挑战性。
从几位业界专家的观点可以得出结论,小米在跑分上击败其它企业和机构已经证实了其人脸检测算法的能力,但是回到应用层,跑分的意义就大打折扣了。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

