同程旅游Redis缓存系统设计
导读:高可用架构 7 月 30 日在上海举办了『互联网架构的基石』专题沙龙,进行了闭门私董会研讨及对外开放的四个专题的演讲,期望能促进业界对互联网基础服务及工具的讨论,本文是王晓波分享同程旅游缓存系统架构经验。
王晓波,同程旅游首席架构师,专注于高并发互联网架构设计、分布式电子商务交易平台设计、大数据分析平台设计、高可用性系统设计,基础云相关技术研究,对 Docker 等容器有深入的实践。另对系统运维和信息安全领域也大量的技术实践。曾设计过多个并发百万以上、每分钟 20 万以上订单量的电商交易平台,熟悉 B2C、B2B、B2B2C、O2O 等多种电商形态系统的技术设计。熟悉电子商务平台技术发展特点,拥有十多年丰富的技术架构、技术咨询经验,深刻理解电商系统对技术选择的重要性。
旅游大家现在比较熟悉,同程旅游涵盖的业务比较多,从火车票到住宿都有。今天我们讲一下同程旅游的缓存系统,包括整个缓存架构如何设计。先来看一下缓存我们走过了哪些历程。
- 从 memcache 开始使用缓存
- 再从 memcache 转到 Redis
- 从单机 Redis 升级到集群 Redis
- 从简单的运维升级到全自动运维
- 重开发 Redis 客户端
- 开发 Redis 调度治理系统
- Redis 部署全面 Docker 化
旅游是比较复杂的业务,住、吃、玩相关功能都会压到平台上,整个在线旅游应用量非常大,酒店、机票,或者是卖一个去泰国旅行团,业务逻辑完全不一样,因此众多业务会带来大量系统的访问压力。
Redis 遍地开花的现状及问题
Redis 集群的管理
所有互联网的应用里面,可能访问最多的就是 cache。一开始时候一些团队认为 cache 就像西游记里仙丹一样,当一个系统访问过大扛不住时,用一下 Redis,系统压力就解决了。在这种背景下,我们的系统里面 Redis 不断增多,逐渐增加到几百台服务器,每台上面还有多个实例,因此当存在几千个 Redis 实例后,可能运维也很难说清楚哪个 Redis 是什么业务。
单点故障
这种背景下会存在什么样痛苦的场景?正常情况下 cache 是为了增加系统的性能,是画龙点睛的一笔,但是当时我们 cache 会是什么样?它挂了就可能让我们整个系统崩溃。比如说 CPU 才 5%,也许就由于缓存问题系统就挂了。
高可用与主从同步问题
因为 cache 有单点,我们想放两个不就好了吗,所以就做了主从。这时候坑又来了,为什么呢?比如有些 Redis 值非常大,如果偶尔网络质量不太好,就会带来主从不同步,当两边主和从都死或者出问题的时,重启的时间非常长。
监控
为了高可用,我们需要全面的监控。当时我们做了哪些监控呢?
- connected_clients : 已连接客户端的数量
- client_longest_output_list : 当前连接的客户端当中,最长的输出列表
- client_longest_input_buf : 当前连接的客户端当中,最大输入缓存
- blocked_clients : 正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量
- used_memory_human : 以人可读的格式返回 Redis 分配的内存总量
- used_memory_rss : 从操作系统的角度,返回 Redis 已分配的内存总量(俗称常驻集大小)。这个值和 top 、 ps 等命令的输出一致。
- replication : 主/从复制信息
- instantaneous_ops_per_sec : 服务器每秒钟执行的命令数量。
下面是一个接近真实场景运维与开发的对话场景。
- 开发:Redis 为啥不能访问了?
- 运维:刚刚服务器内存坏了,服务器自动重启了
- 开发:为什么 Redis 延迟这么大?
- 运维:不要在 Zset 里放几万条数据,插入排序会死人啊
- 开发:写进去的 key 为什么不见了?
- 运维:Redis 超过最大大小了啊,不常用 key 都丢了啊
- 开发:刚刚为啥读取全失败了
- 运维:网络临时中断了一下,从机全同步了,在全同步完成之前,从机的读取全部失败
- 开发:我需要 800G 的 Redis,什么时候能准备好?
- 运维:线上的服务器最大就 256G,不支持这么大
- 开发:Redis 慢得像驴,服务器有问题了?
- 运维:千万级的 KEY,用 keys*,慢是一定了。
因此我们一个架构师最后做了以下总结
从来没想过,一个小小的 Redis 还有这么多新奇的功能。 就像在手上有锤子的时候,看什么都是钉子 。渐渐的,开发规范倒是淡忘了,新奇的功能却接连不断的出现了,基于 Redis 的分布式锁、日志系统、消息队列、数据清洗等,各种各样的功能不断上线,从而引发各种各样的问题。 运维天天疲于奔命,到处处理着 Redis 堵塞、网卡打爆、连接数爆表……
总结了一下,我们之前的缓存存在哪些问题?
- 使用的者的乱用、烂用、懒用。
- 运维一个几百台毫无规则的服务器
- 运维不懂开发,开发不懂运维
- 缓存在无设计无控制中被使用
- 开发人员能力各不相同
- 使用太多的服务器
- 懒人心理(应对变化不够快)
我们需要一个什么样的完美缓存系统?
我相信上面这些情况在很多大量使用 Redis 的团队中都存在,如果发展到这样一个阶段后,我们到底需要一个什么样的缓存?
- 服务规模 :支持大量的缓存访问,应用对缓存大少需求就像贪吃蛇一般
- 集群可管理性 :一堆孤岛般的单机服务器缓存服务运维是个迷宫
- 冷热区分 :现在缓存中的数据许多并不是永远的热数据
- 访问的规范及可控 :还有许多的开发人员对缓存技术了解有限,胡乱用的情况很多
- 在线扩缩容 :起初估算的不足到用时发现瓶颈了
这个情况下,我们去考虑使用更好的方案,本来我们是想直接使用某个开源方案就解决了,但是我们发现每个开源方案针对性的解决 Redis 上述痛点的某一些问题,每一个方案在评估阶段跟我们需求都没有 100% 匹配。每个开源方案本身都很优秀,也许只是说我们的场景的特殊性,没有任何否定的意思。
下面我们当时评估的几个开源方案,看一下为什么当时没有引入。
- CacheCloud :跟我们需要的很像,它也做了很多的东西,但是它对我们不满足是部署方案不够灵活,对运维的策略少了点。
- Codis :这个其实很好,当年我们已经搭好了准备去用了,后来又下了,因为之前有一个业务需要 800G 内存,后来我们发现这个大集群有一个问题,因为用得不是很规范,如果在这种情况下给他一个更大的集群,那我们可能死的机率更大,所以我们也放弃了。另外 800G 也很浪费,并不完全都是热数据,我们想把它存到硬盘上一部分,很多业务使用方的心理是觉得在磁盘上可能会有性能问题,还是放在 Redis 放心一点,其实这种情况基本不会出现,因此我们需要一定的冷热区分支持。
- Pika :Pika 可以解决上面的大量数据保存在磁盘的问题,但是它的部署方案少了点,而且 Pika 的设计说明上也表示主要针对大的数据存储。
- Twemproxy :最后我们想既然直接方案不能解决,那可以考虑代理治理的方式,但是问题是它只是个代理,Redis 被滥用的问题还是没有真正的治理好,所以后面我们准备自己做一个。
全新设计的缓存系统——凤凰
我们新系统起了一个比较高大上的名字,叫凤凰,愿景是凤凰涅磐,从此缓存不会再死掉了。
凤凰是怎么设计的?
- 在应用中能根据场景拆分(应用透明)
- 能从客户端调用开始全面监控
- 能防止缓存的崩塌
- 动态扩容缩容
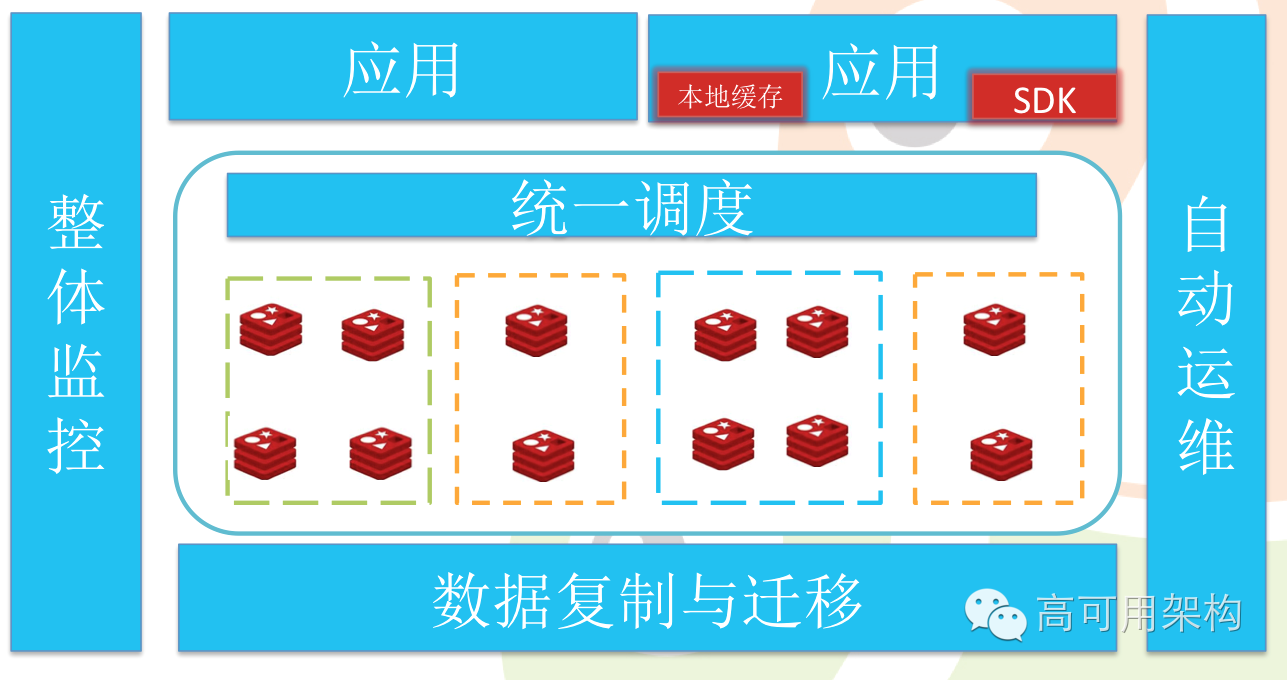
自定义客户端方式与场景配置能力
在支持 Redis 本身的特性的基础上,我们需要通过自定义的客户端来实现一些额外的功能。
支持场景配置,我们考虑根据场景来管控它的场景,客户端每次用 Redis 的时候,必须把场景上报给我,你是在哪里,用这件事儿是干什么的,虽然这个对于开发人员来说是比较累的,他往往嵌在它的任务逻辑里面直接跟进去。曾江场景配置之后,在缓存服务的中心节点,就可以把它分开,同一个应用里面两个比较重要的场景就会不用同一个 Redis,避免挂的时候两个一起挂。
同时也需要一个调度系统,分开之后,不同的 Redis 集群所属的服务器也需要分开。分开以后我的数据怎么复制,出问题的时候我们怎么把它迁移?因此也需要一个复制和迁移的平台去做。
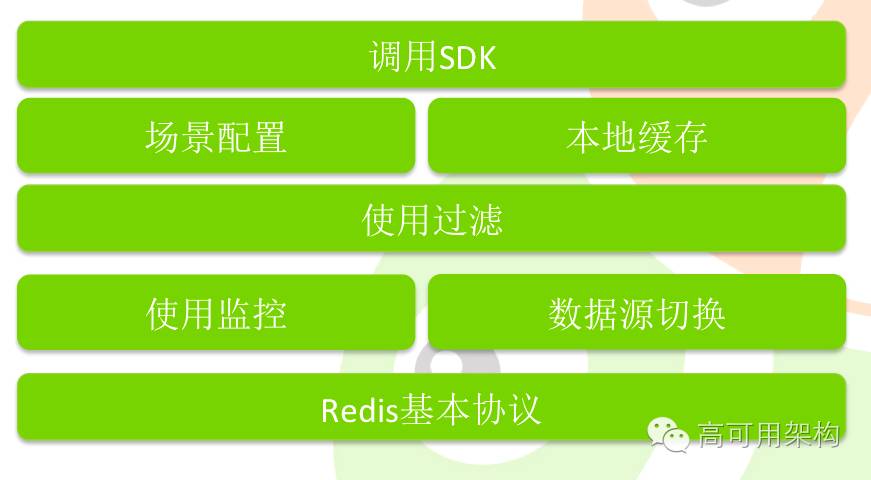
另外这么一套复杂的东西出来之后,需要一个监控系统;客户端里也可以增加本地 cache 的支持。在业务上也可能需要对敏感的东西进行过滤。在底层,可以自动实现对访问数据源的切换,对应用是透明的,应用不需要关心真正的数据源是什么,这就是我们自己做的客户端。
代理层方式
客户端做了之后还发生一个问题,前面分享的唯品会的姚捷说了一个问题,很多情况下很难升级客户端。再好的程序员写出来的东西还是有 bug,如果 Redis 组件客户端发现了一个 bug 需要升级,但我们线上有几千个应用分布在多个业务开发团队,这样导致很难驱动这么多开发团队去升级。另外一个现状就是是中国在线旅游行业好像都喜欢用 .net,我们之前很多的系统也都是 .net 开发,最近我们也把客户端嵌到 .net,实现了 .net 版本,但是由于各种原因,要推动这么多历史业务进行改造切换非常麻烦,甚至有些特别老的业务最后没法升级。
因此我们考虑了 proxy 方案,这些业务模块不需要修改代码,我们的想法就是让每一个项目的每一个开发者自己开发的代码是干净的,不要在他的代码里面嵌任何的东西,业务访问的就是一个 Redis。
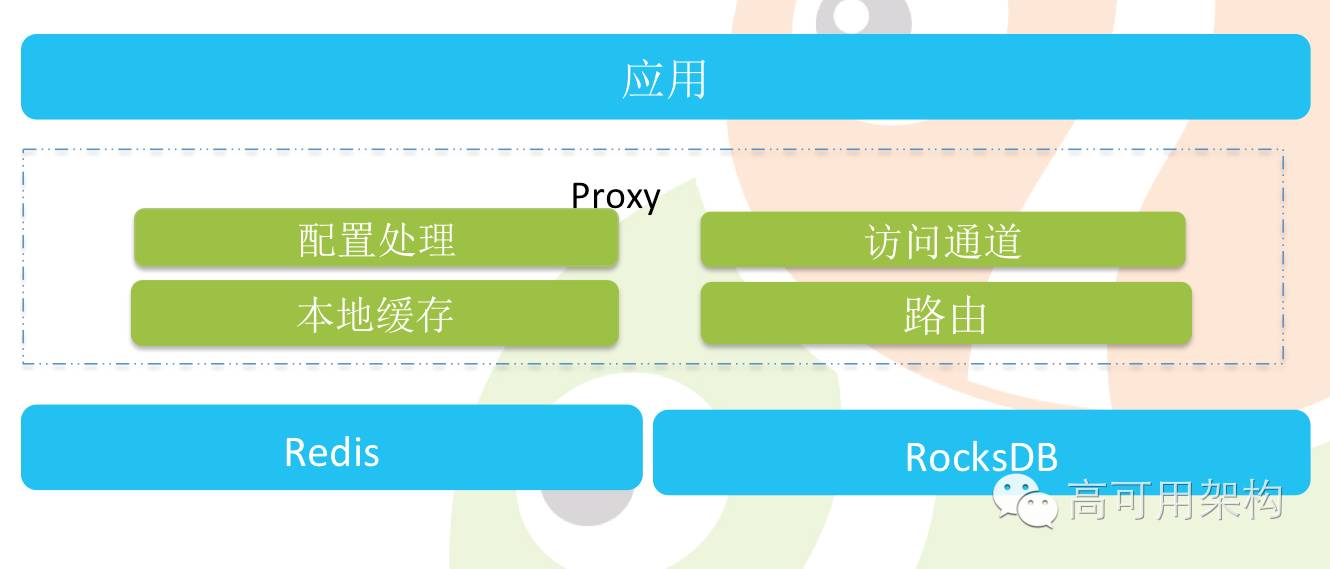
那么我们就做了,首先它是 Redis 的协议,接下来刚才我们在客户端里面支持的各种场景配置录在 proxy 里面,实现访问通道控制。然后再把 Redis 本身沉在我们 proxy 之后,让它仅仅变成一个储存的节点,proxy 再做一些自己的事情,比如本地缓存及路由。冷热区分方面,在一些压力不大的情况下,调用方看到的还是个 Redis ,但是其实可能数据是存在 RocksDB 里面了。
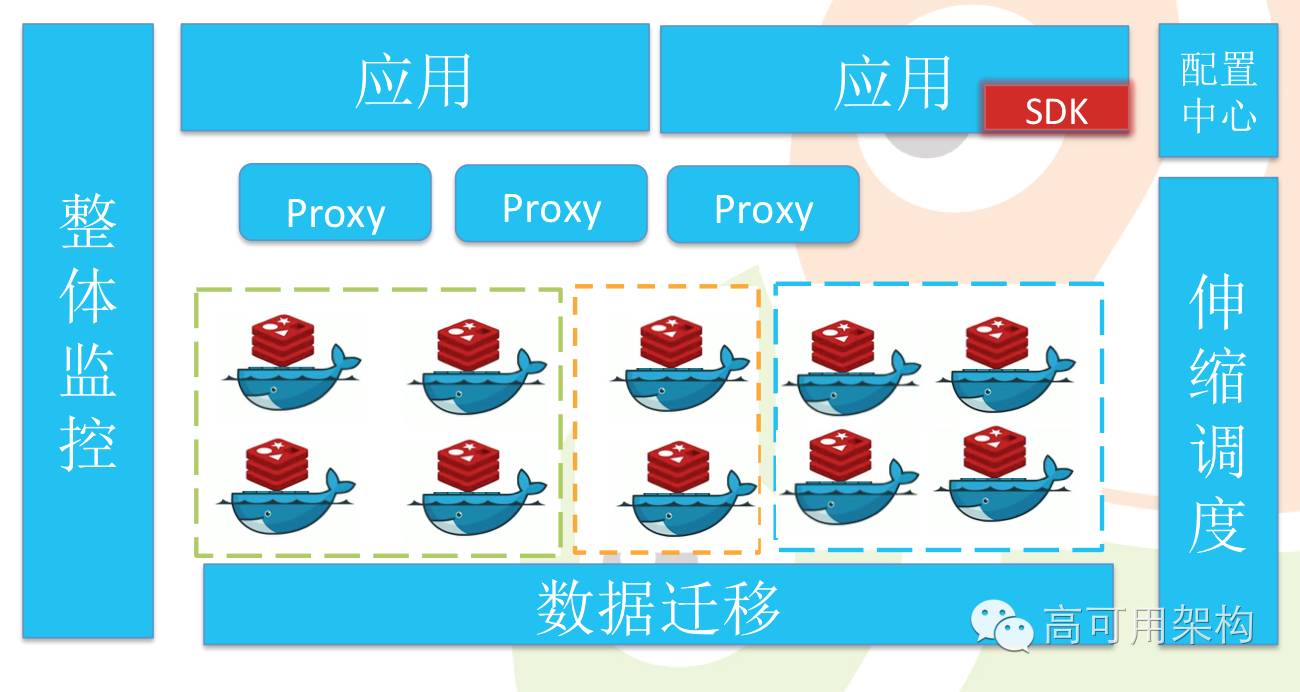
缓存服务的架构设计
- 多个小集群 + 单节点, 我们要小集群的部署和快速的部署,到当时一个集群有问题的时候,快速移到另一个集群。
- 以场景划分集群
- 实时平衡调度数据
- 动态扩容缩容
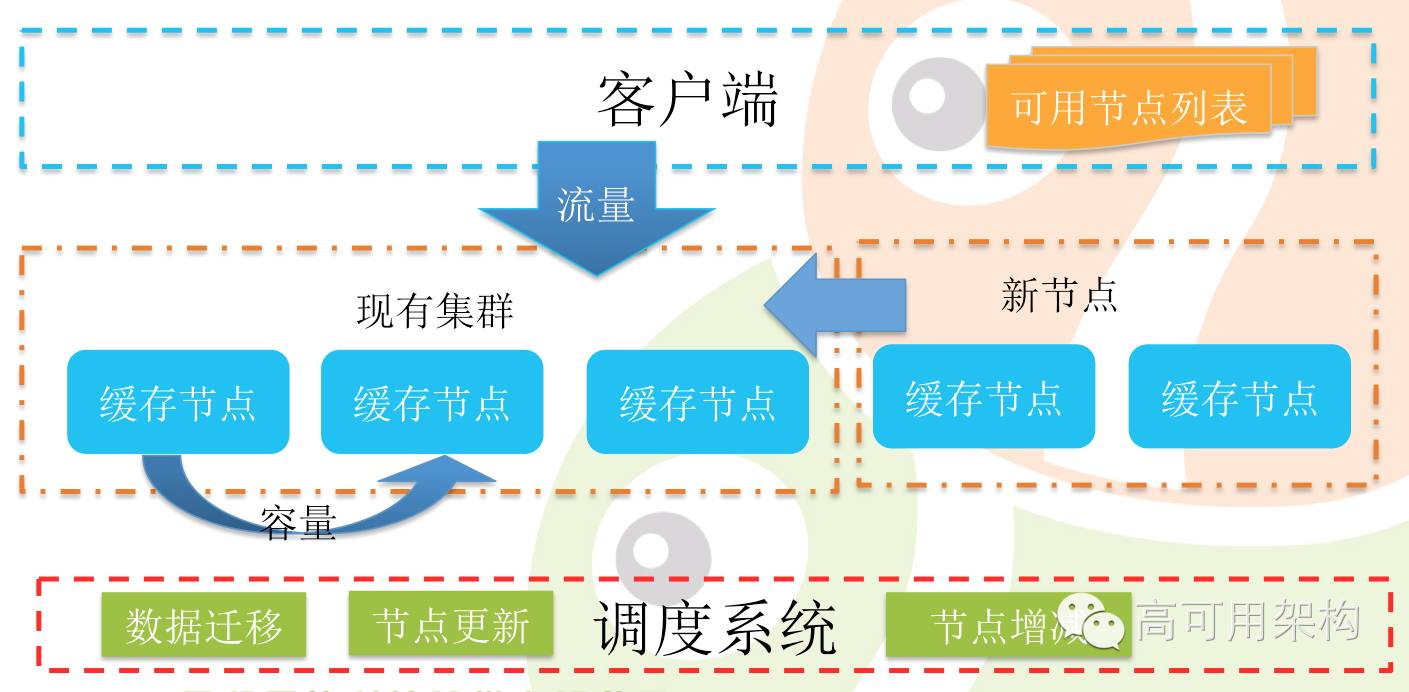
可扩容能力
- 流量的快速增加必然带扩容的需求与压力
- 容量与流量的双扩容
- 如何做到平滑的扩容?容量动态的数据迁移(集群内部平衡,新节点增加);流量超出时的根据再平衡集群。
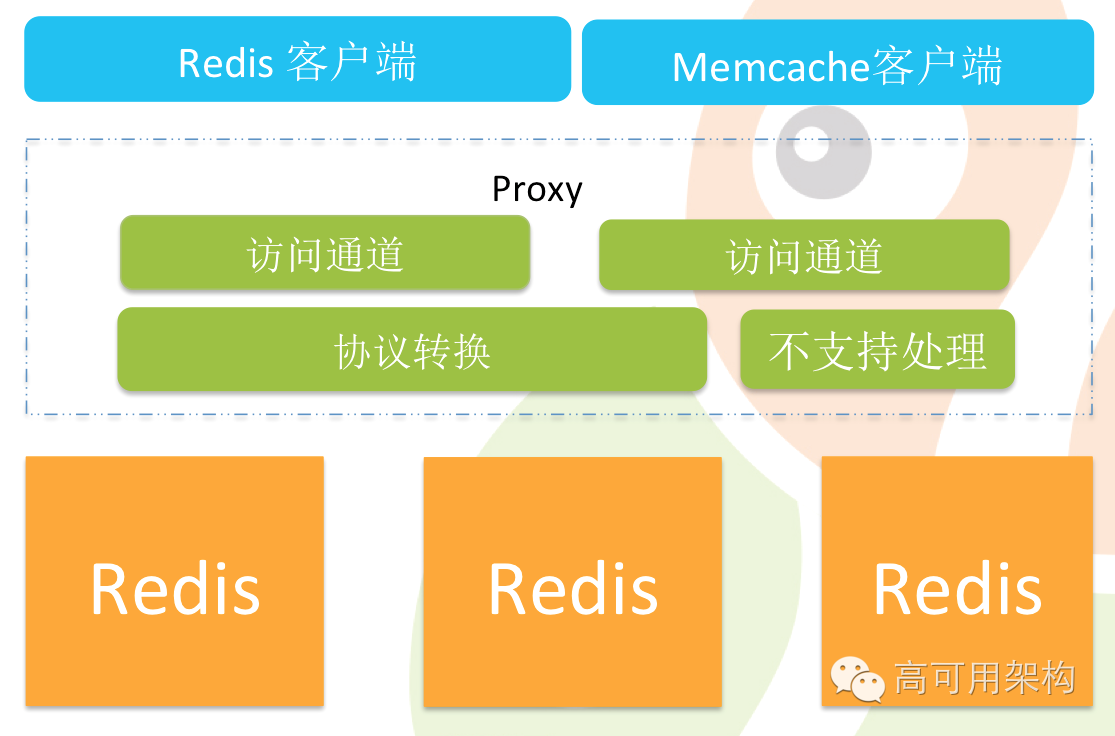
多协议支持
还有一块老项目是最大的麻烦,同程有很多之前是 memcache 的应用,后来是转到 Redis 去的,但是转出一个问题来了,有不少业务由于本身事情较多没有转换成 Redis,这些钉子户怎么办?同时维护这两个平台是非常麻烦的,刚才 proxy 就派到用场了。因为 memcache 本身它的数据支持类型是比较少的,因此转换比较简单,如果是一个更复杂的类型,那可能就转不过来了。所以我们 proxy 就把这些钉子户给拆掉了,他觉得自己还是在用 memcache,其实已经被转成了 Redis。
管理与可监控能力
最后一块,我们这样一个平台怎么去监控它,和怎么去运维它?
- 整体的管制平台,
- 运维操作平台,让它可以去操作,动态的在页面上操作做一件事情,
- 整体监控平台。我们从客户端开始,到服务器的数据,全部把它监控起来。
- 自扩容自收缩。动态的自扩容,自收缩。
一些业务应用场景
也是用了一些场景,比如说同程前两年冲的比较狠的就是一元门票,大家肯定说抢购,这个最大的压力是什么,早上的九点半,这是我们系统最大的压力,为什么呢,一块钱的门票的从你买完票到景区里面去,这件事情是在九点半集中爆发的,你要说这个是系统挂了入不了园了,那十几万人不把这个景区打砸了才怪。那个时候系统绝对不能死。抢购没有关系,入园是我们最大的压力,
我们是靠新的系统提供了访问能力及可用性的支持,把类似这种场景支撑下来,其实缓存本身是可以支撑住的,但是如果滥用管理失控,可能碰到这种高可用的需求就废了。
还有一个是火车票系统,火车票查询量非常大,我们这主要是用了新系统的收缩容,到了晚上的时候查的人不多了,到了早上的时候特别多,他查询量是在一个高低跌荡的,所以我们可以根据访问的情况来弹性调度。
Q&A;
提问:你们监控是用官方的,还是用自己开发的监控软件?
王晓波:我们监控是执行命令查过来,是我们开发的。
提问:收缩和扩容这块你们是怎么做的?
王晓波:收缩和扩容,其实现在我们 Redis 本身就是 Redis Cluster,直接往里面加节点,加完节点有一个问题,要去执行一些命令把数据搬走,我们就会自动的把它数据平衡掉。
上面说的是 Redis 3.0 集群的情况,还有一些不是 3.0 的怎么办?我们有一个程序模拟自己的从机拷出来,然后分配到另外两个点上去,本来是一台,我有个程序模拟自己是一个 Redis 从,它同步过来之后就根据这个数据分到另外两台里面去,这个我的成本比较低,因为我的 Redis 集群可以做的很小。为什么会这样呢,我们之前也是碰到一些麻烦点,一个机器很大,但是往往我要的 Redis 没这么多,但是最高的时候是每家隔开,对一些小的应用是最好的,但是我服务器那么多,所以当我们 Redis Cluster 上来之后我们第一个用的。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

