Data Guard跳归档恢复的案例
自前些天写了一个脚本之后,今天特意测试了一下,没想到一下子发现了一个大问题。有一套一主两备的10gR2环境,一个异机备库一直在READ ONLY状态,也就意味着数据库在打开之后一直忘了恢复应用归档,然后在某一天发现时,已经延迟了好几个月。无论怎样,还得庆幸发现了这个问题。
目前来看一种行之有效的方法就是重搭备库,但是这种修复方式需要大量的磁盘空间,而且需要恢复的时间较长,怎么改进呢,可以考虑通过基于SCN的增量备份来跳归档恢复。目前的环境是一主两备,再怎么改进呢,我们可以基于备库1来完成基于SCN的增量备份,在备库2完成恢复,对于主库几乎是完全透明,无影响的。
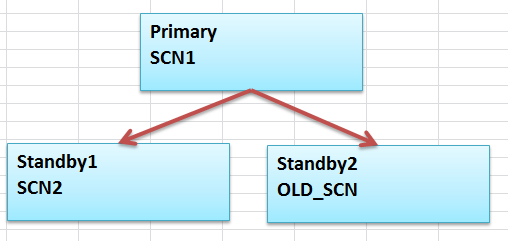
整个示意图如下,通过在Standby1上面基于SCN导出增量备份,拷贝到备库2上去恢复,最后再和主库汇合即可。
所以在这个问题上,还是对10g的DG Broker颇有微词,因为11g中是ADG不会存在这类问题,在10g中备库为READ ONLY,哪怕丢失了大量的归档,备库也是检查通过的。
直到在切换到恢复模式的时候,后台日志还不清楚到底发生了什么。
目前来看一种行之有效的方法就是重搭备库,但是这种修复方式需要大量的磁盘空间,而且需要恢复的时间较长,怎么改进呢,可以考虑通过基于SCN的增量备份来跳归档恢复。目前的环境是一主两备,再怎么改进呢,我们可以基于备库1来完成基于SCN的增量备份,在备库2完成恢复,对于主库几乎是完全透明,无影响的。
整个示意图如下,通过在Standby1上面基于SCN导出增量备份,拷贝到备库2上去恢复,最后再和主库汇合即可。
所以在这个问题上,还是对10g的DG Broker颇有微词,因为11g中是ADG不会存在这类问题,在10g中备库为READ ONLY,哪怕丢失了大量的归档,备库也是检查通过的。
直到在切换到恢复模式的时候,后台日志还不清楚到底发生了什么。
其实这个时候问题已经很严峻了。
我们首先在备库1上查看SCN的情况。
idle> col CURRENT_SCN format 99999999999999999999999999999
idle>SELECT CURRENT_SCN FROM V$DATABASE;
CURRENT_SCN
------------------------------
188670376120
备库2上的SCN情况如下:
SQL> col CURRENT_SCN format 99999999999999999999999999999
SQL> SELECT CURRENT_SCN FROM V$DATABASE;
CURRENT_SCN
------------------------------
188611153769
可以看到延迟已经很大了。可能通过这个数字对比还不够明显。从后台日志可以看到,上一次启动到READ ONLY的时候是在3月份了,也就意味着这个问题已经过去了快半年了。这种情况下增量恢复还有希望吗,在主库端查看了下最近的归档情况,发现这个数据库的数据变更频率很低,基本是每天一次,所以近半年的时间大概是150~180个左右的归档,好像还能勉强接受。
在备库1增量导出的情况如下,我们基于SCN 188611153769,也就是备库2上一个较旧的SCN
[@TEST.test.com backup_stage]$ rman target /
Recovery Manager: Release 10.2.0.4.0 - Production on Mon Aug 15 11:32:56 2016
Copyright (c) 1982, 2007, Oracle. All rights reserved.
connected to target database: TEST (DBID=1731005384, not open)
RMAN> BACKUP INCREMENTAL FROM SCN 188611153769 DATABASE FORMAT '/home/oracle/backup_stage/stest2_%U' tag 'FORSTANDBY';
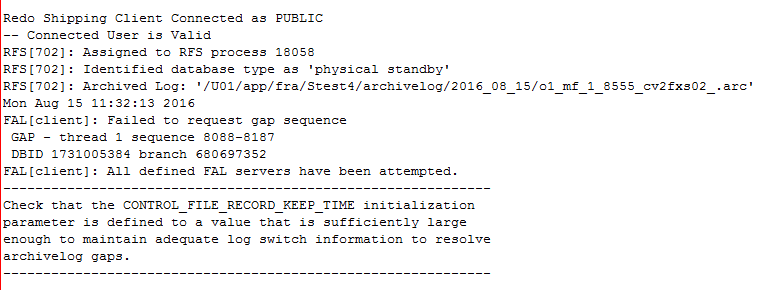
在真实环境尝试,和实验还是有很大的差别,短暂的等待后竟然抛出了一个错误。
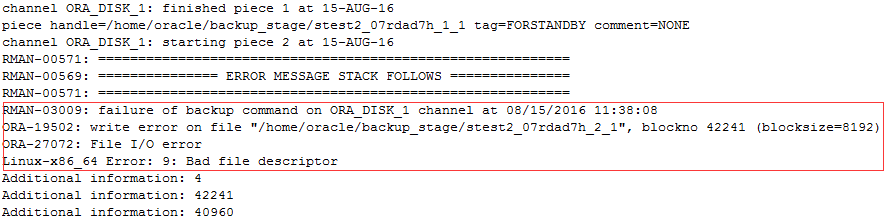
不过虚惊一场,这个是备份的路径问题,导致空间不足,切换了一个路径再次尝试,很快就完成了,大概用了7分钟的时间。
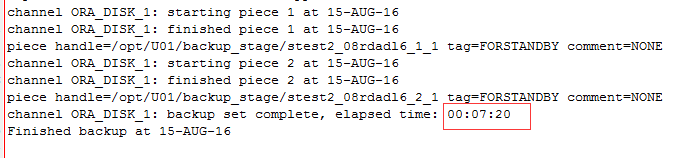
这个时候拷贝到备库2上会恢复,当然还是需要先恢复控制文件,可以从主库生成一个镜像过去,或者从备库2拷贝也可以。
否则在恢复的时候会抛出类似下面的错误。

备库2先注册这个增量备份,/U01/backup_stage/increment_backup是增量备份存放的路径
[@stest4.test.com ~]$ rman target /
RMAN> catalog start with '/U01/backup_stage/increment_backup';
Starting implicit crosscheck backup at 15-AUG-16
using target database control file instead of recovery catalog
采用下面的方式恢复:
RMAN> recover database noredo ;
恢复的时间更短,大概是1分多钟。
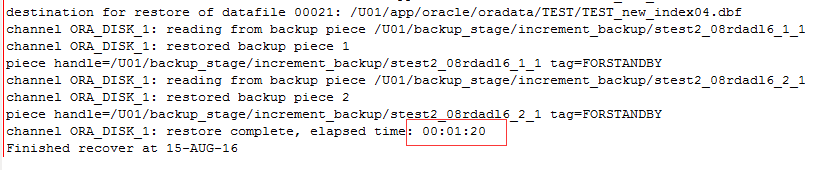
后台的日志会输出类似下面的内容:

恢复后查看SCN的情况如下,已经有了更新。
SQL> col CURRENT_SCN format 9999999999999999999999
SQL> SELECT CURRENT_SCN FROM V$DATABASE;
CURRENT_SCN
-----------------------
188670376925
后面所做的就是开启恢复模式。
SQL> recover managed standby database disconnect from session;
Media recovery complete.
这个时候查看数据库日志就会发现备库2很快就追评了归档GAP,一切又恢复了正常。
通过这个案例可以看到Data Guard的恢复在有些时候还是有一些捷径可走,明白了原理,加上点运气,问题就可以引刃而解。
idle> col CURRENT_SCN format 99999999999999999999999999999
idle>SELECT CURRENT_SCN FROM V$DATABASE;
CURRENT_SCN
------------------------------
188670376120
备库2上的SCN情况如下:
SQL> col CURRENT_SCN format 99999999999999999999999999999
SQL> SELECT CURRENT_SCN FROM V$DATABASE;
CURRENT_SCN
------------------------------
188611153769
可以看到延迟已经很大了。可能通过这个数字对比还不够明显。从后台日志可以看到,上一次启动到READ ONLY的时候是在3月份了,也就意味着这个问题已经过去了快半年了。这种情况下增量恢复还有希望吗,在主库端查看了下最近的归档情况,发现这个数据库的数据变更频率很低,基本是每天一次,所以近半年的时间大概是150~180个左右的归档,好像还能勉强接受。
在备库1增量导出的情况如下,我们基于SCN 188611153769,也就是备库2上一个较旧的SCN
[@TEST.test.com backup_stage]$ rman target /
Recovery Manager: Release 10.2.0.4.0 - Production on Mon Aug 15 11:32:56 2016
Copyright (c) 1982, 2007, Oracle. All rights reserved.
connected to target database: TEST (DBID=1731005384, not open)
RMAN> BACKUP INCREMENTAL FROM SCN 188611153769 DATABASE FORMAT '/home/oracle/backup_stage/stest2_%U' tag 'FORSTANDBY';
在真实环境尝试,和实验还是有很大的差别,短暂的等待后竟然抛出了一个错误。
不过虚惊一场,这个是备份的路径问题,导致空间不足,切换了一个路径再次尝试,很快就完成了,大概用了7分钟的时间。
这个时候拷贝到备库2上会恢复,当然还是需要先恢复控制文件,可以从主库生成一个镜像过去,或者从备库2拷贝也可以。
否则在恢复的时候会抛出类似下面的错误。
备库2先注册这个增量备份,/U01/backup_stage/increment_backup是增量备份存放的路径
[@stest4.test.com ~]$ rman target /
RMAN> catalog start with '/U01/backup_stage/increment_backup';
Starting implicit crosscheck backup at 15-AUG-16
using target database control file instead of recovery catalog
采用下面的方式恢复:
RMAN> recover database noredo ;
恢复的时间更短,大概是1分多钟。
后台的日志会输出类似下面的内容:
恢复后查看SCN的情况如下,已经有了更新。
SQL> col CURRENT_SCN format 9999999999999999999999
SQL> SELECT CURRENT_SCN FROM V$DATABASE;
CURRENT_SCN
-----------------------
188670376925
后面所做的就是开启恢复模式。
SQL> recover managed standby database disconnect from session;
Media recovery complete.
这个时候查看数据库日志就会发现备库2很快就追评了归档GAP,一切又恢复了正常。
通过这个案例可以看到Data Guard的恢复在有些时候还是有一些捷径可走,明白了原理,加上点运气,问题就可以引刃而解。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

