Seq2Seq的DIY简介
Seq2Seq技术,全称Sequence to Sequence,该技术突破了传统的固定大小输入问题框架,开通了将经典深度神经网络模型(DNNs)运用于翻译与智能问答这一类序列型(Sequence Based,项目间有固定的先后关系)任务的先河,并被证实在英语-法语翻译、英语-德语翻译以及人机短问快答的应用中有着不俗的表现。笔者尝试用自己的语言对Seq2Seq进行简单的介绍,帮助有兴趣的朋友撬开人工智能神秘的大门。
问世
Seq2Seq被提出于2014年,最早由两篇文章独立地阐述了它主要思想,分别是Google Brain团队的《Sequence to Sequence Learning with Neural Networks》和Yoshua Bengio团队的《Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation》。这两篇文章针对机器翻译的问题不谋而合地提出了相似的解决思路,Seq2Seq由此产生。

核心思想
Seq2Seq解决问题的主要思路是通过深度神经网络模型(常用的是LSTM,长短记忆网络,一种循环神经网络)将一个作为输入的序列映射为一个作为输出的序列,这一过程由编码输入与解码输出两个环节组成。
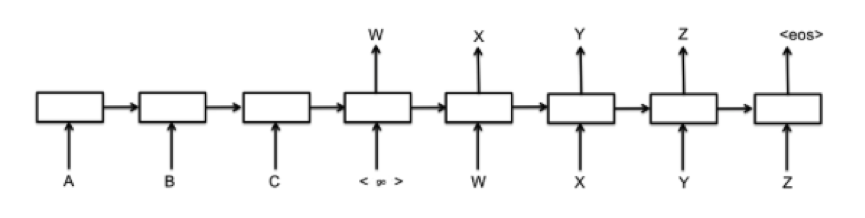
由上图所示,在这个模型中每一时间的输入和输出是不一样的,比如对于序列数据就是将序列项依次传入,每个序列项再对应不同的输出。比如说我们现在有序列“A B C EOS” (其中EOS=End of Sentence,句末标识符)作为输入,那么我们的目的就是将“A”,“B”,“C”,“EOS”依次传入模型后,把其映射为序列“W X Y Z EOS”作为输出。
(1)编码(Encode)
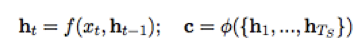 在Seq2Seq中,各类长度不同的输入序列x将会经由循环神经网络(Recurrent neural Network,RNN)构建的编码器编译为语境向量c。向量c通常为RNN中的最后一个隐节点(h,Hidden state),或是多个隐节点的加权总和。
在Seq2Seq中,各类长度不同的输入序列x将会经由循环神经网络(Recurrent neural Network,RNN)构建的编码器编译为语境向量c。向量c通常为RNN中的最后一个隐节点(h,Hidden state),或是多个隐节点的加权总和。
(2)解码(Decode)
 编码完成之后,我们的语境向量c将会进入一个RNN解码器中进行解译。简单来说,解译的过程可以被理解为运用贪心算法(一种局部最优解算法,即选取一种度量标准,默认在当前状态下进行最好的选择)来返回对应概率最大的词汇,或是通过集束搜索(Beam Search,一种启发式搜索算法,可以基于设备性能给予时间允许内的最优解)在序列输出前检索大量的词汇,从而得到最优的选择。
编码完成之后,我们的语境向量c将会进入一个RNN解码器中进行解译。简单来说,解译的过程可以被理解为运用贪心算法(一种局部最优解算法,即选取一种度量标准,默认在当前状态下进行最好的选择)来返回对应概率最大的词汇,或是通过集束搜索(Beam Search,一种启发式搜索算法,可以基于设备性能给予时间允许内的最优解)在序列输出前检索大量的词汇,从而得到最优的选择。
(3)注意机制(Attention Mechanism)
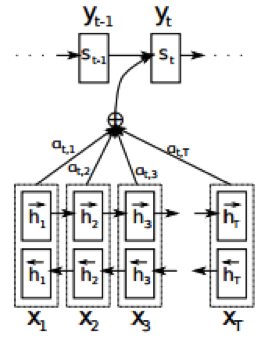
作为Seq2Seq中的重要组成部分,注意机制最早由Bahdanau等人于2014年提出,该机制存在的目的是为了解决RNN中只支持固定长度输入的瓶颈。在该机制环境下,Seq2Seq中的编码器被替换为一个双向循环网络(bidirectional RNN)。如上图所示,在注意机制中,我们的源序列x=(x1,x2,…,xt)分别被正向与反向地输入了模型中,进而得到了正反两层隐节点,语境向量c则由RNN中的隐节点h通过不同的权重a加权而成,其公式如下:
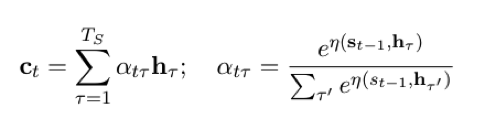
其中,η为一个调整“注意回应强度”的函数。我们知道每一个隐节点hi都包含了对应的输入字符xi以及其对上下文的联系,这么做意义就在于现在模型可以突破固定长度输入的限制,根据不同的输入长度构建不同个数的隐节点,故不论我们输入的序列(比如待翻译的一段原文)长度如何,都可以得到模型输出结果。
应用领域
经过上文所述的几个环节,我们的Seq2Seq模型就基本搭建完成了,接下来让我们看看这种技术目前能在那些领域得到具体的应用:
(1)机器翻译
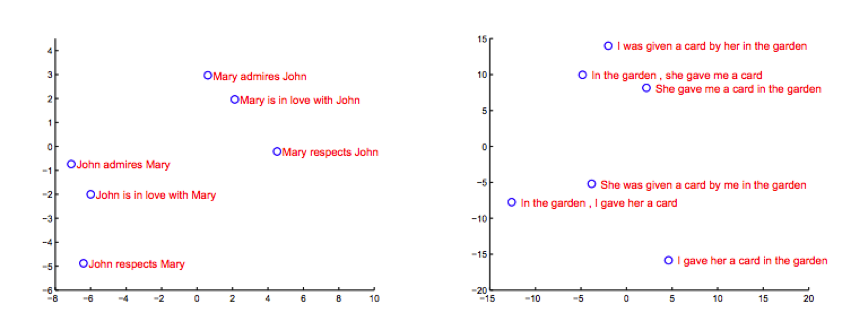 作为Seq2Seq研发的起点,机器翻译领域中Seq2Seq技术已有了长足的应用。Google Brain团队在其2014年论文《Sequence to Sequence Learning with Neural Networks》的应用案例中对LSTM的隐节点做了主成分分析,从图像可以看出,模型中的语境向量很明显的包涵了输入序列的语言意义,能够将由不同次序所产生的不同意思的语句划分开来,这对于提升机器翻译的准确率很有帮助,该团队应用这个技术进行了英法语翻译的具体试验,并得到了令人满意的结果。
作为Seq2Seq研发的起点,机器翻译领域中Seq2Seq技术已有了长足的应用。Google Brain团队在其2014年论文《Sequence to Sequence Learning with Neural Networks》的应用案例中对LSTM的隐节点做了主成分分析,从图像可以看出,模型中的语境向量很明显的包涵了输入序列的语言意义,能够将由不同次序所产生的不同意思的语句划分开来,这对于提升机器翻译的准确率很有帮助,该团队应用这个技术进行了英法语翻译的具体试验,并得到了令人满意的结果。
(2)智能对话与问答
上文我们曾经提过,除了翻译,Seq2Seq还被用于人机智能对话与问答的实现,基于IT Helpdesk Troubleshooting和OpenSubtitles语料集,2015年Google的Oriol Vinyals和Quoc V.Le通过Seq2Seq训练了两个自动问答程序,程序的具体效果如下图所示:

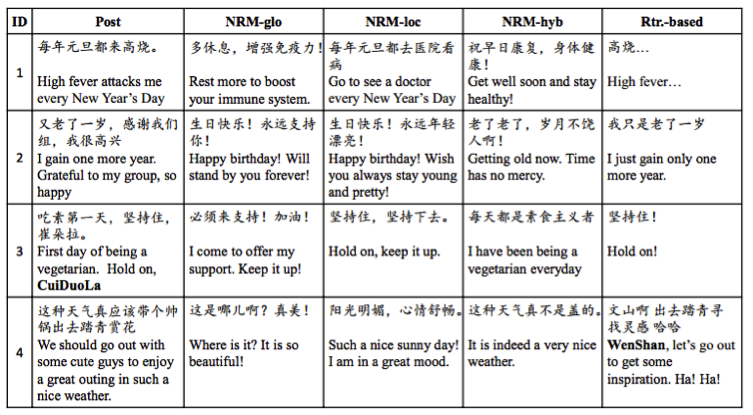
类似的工作也被应用于我国的微博语料,2015年,华为团队的Lifeng Shang等人通过Seq2Seq实现了计算机对微博的自动回复,并通过模型间的对比得到了一系列有意思的结果(下图中,post列为微博主发文,其余四列为不同模型对该条微博做出的回复)。
(3)自动编码与分类器训练
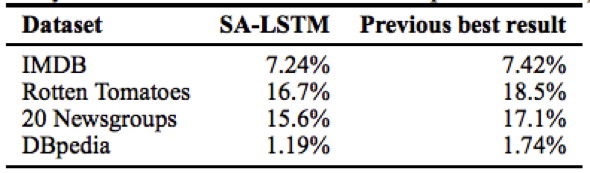
2015年,Google的Andrew M.Dai和Quo V.Le提出了将Seq2Seq的自动编码器作为LSTM文本分类的一个预训练步骤,从而提高了分类的稳定性。这使得Seq2Seq技术的目的不再局限于得到序列本身,为其应用领域翻开了崭新的一页。

原文: https://github.com/jxieeducation/DIY-Data-Science/blob/master/research/seq2seq.md
翻译&整理:SD Cry!!!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

