比深度学习快几个数量级,详解Facebook最新开源工具——fastText
导读:Facebook声称fastText比其他学习方法要快得多,能够训练模型“在使用标准多核CPU的情况下10分钟内处理超过10亿个词汇”,特别是与深度模型对比,fastText能将训练时间由数天缩短到几秒钟。

Facebook FAIR实验室在最新博客中宣布将开源资料库fastText,声称相比深度模型,fastText能将训练时间由数天缩短到几秒钟。
| 使用fastText实现更快、更好的文本分类
理解人们交谈时的内容,或者敲打文章时的内容——这对于人工智能研究者来说是最大的技术挑战之一,但是也确实是关键的一个需求。自动文本处理在日常计算机使用中相当关键,在网页搜索和内容排名以及垃圾内容分类中占重要组成部分。且当它运行的时候你完全感受不到它。随着在线数据总量越来越大,需要有更灵活的工具来更好的理解这些大型数据集,来提供更加精准的分类结果。
为了满足这个需求,Facebook FAIR实验室开源了fastText。 fastText是一个资料库,能针对文本表达和分类帮助建立量化的解决方案 。关于fastText具体实现原理,Facebook另外发表了两篇相关论文,两篇论文具体信息如下:
Bag of Tricks for Efficient Text Classification(高效文本分类技巧)

Enriching Word Vectors with Subword Information(使用子字信息丰富词汇向量)

fastText结合了自然语言处理和机器学习中最成功的理念。这些包括了使用词袋以及 n-gram 袋表征语句,还有使用子字(subword)信息,并通过隐藏表征在类别间共享信息。我们另外采用了一个softmax层级(利用了类别不均衡分布的优势)来加速运算过程。这些不同概念被用于两个不同任务:
有效文本分类
学习词向量表征
举例来说:fastText能够学会“男孩”、“女孩”、“男人”、“女人”指代的是特定的性别,并且能够将这些数值存在相关文档中。然后,当某个程序在提出一个用户请求(假设是“我女友现在在儿?”),它能够马上在fastText生成的文档中进行查找并且理解用户想要问的是有关女性的问题。
| fastText对于文本分类的实现过程
在文本处理领域中深度神经网络近来大受欢迎,但是它们训练以及测试过程十分缓慢,这也限制了它们在大数据集上的应用。
fastText能够解决这个问题,其 实现过程 如下所示:
对于有大量类别的数据集,fastText使用了一个 分层分类器 (而非扁平式架构)。不同的类别被整合进树形结构中(想象下二叉树而非 list)。

考虑到线性以及多种类别的对数模型,这大大减少了训练复杂性和测试文本分类器的时间。fastText 也利用了类别(class)不均衡这个事实(一些类别出现次数比其他的更多),通过使用 Huffman 算法 建立用于表征类别的树形结构。因此,频繁出现类别的树形结构的深度要比不频繁出现类别的树形结构的深度要小,这也使得进一步的计算效率更高。
Huffman 算法
fastText 另外使用了一个低维度向量来对文本进行表征,通过总结对应文本中出现的词向量进行获得。在 fastText 中一个低维度向量与每个单词都相关。隐藏表征在不同类别所有分类器中进行共享,使得文本信息在不同类别中能够共同使用。这类表征被称为词袋(bag of words)(此处忽视词序)。在 fastText中也使用向量表征单词 n-gram来将局部词序考虑在内,这对很多文本分类问题来说十分重要。
实验表明 fastText 在准确率上与深度学习分类器具有同等水平,特别是在训练和评估速率上要高出几个数量级。 使用 fastText能够将训练时间从几天降至几秒 ,并且在许多标准问题上实现当下最好的表现(例如文本倾向性分析或标签预测)。

FastText与基于深度学习方法的Char-CNN以及VDCNN对比
| fastText也可作为专业工具
文本分类对于商业界来说非常重要。垃圾邮件或钓鱼邮件过滤器可能就是最典型的例子。现在已经有能为一般分类问题(例如 Vowpal Wabbit 或 libSVM)设计模型的工具,但是 fastText 专注于文本分类。这使得在特别大型的数据集上,它能够被快速训练。我们使用一个标准多核 CPU,得到了在10分钟内训练完超过10亿词汇量模型的结果。此外, fastText还能在五分钟内将50万个句子分成超过30万个类别。
| fastText对于许多语言都通用
除了文本分类以外,fastText也能被用来学习词汇向量表征。利用其语言形态结构,fastText能够被设计用来支持包括英语、德语、西班牙语、法语以及捷克语等多种语言。它还使用了一种简单高效的纳入子字信息的方式,在用于像捷克语这样词态丰富的语言时,这种方式表现得非常好,这也证明了精心设计的字符 n-gram 特征是丰富词汇表征的重要来源。FastText的性能要比时下流行的word2vec工具明显好上不少,也比其他目前最先进的词态词汇表征要好。
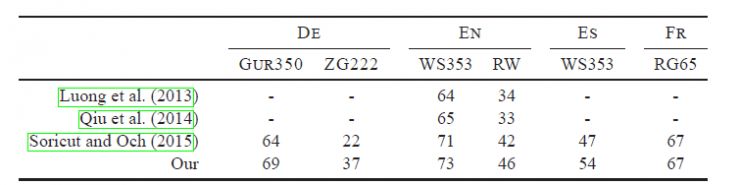
不同语言下FastText与当下最先进的词汇表征进行比较
fastText具体代码实现过程
fastText基于Mac OS或者Linux系统构筑,使用 C++11 的特性。需要 python 2.6 或者更高版本支持,以及 numpy & scipy等软件支持。
示例:
$ git clone https://github.com/facebookresearch/fastText.git
$ cd fastText
$ make
$ ./fasttext supervised
Empty input or output path.
The following arguments are mandatory:
-input training file path
-output output file path
The following arguments are optional:
-lr learning rate [0.05]
-dim size of word vectors [100]
-ws size of the context window [5]
-epoch number of epochs [5]
-minCount minimal number of word occurences [1]
-neg number of negatives sampled [5]
-wordNgrams max length of word ngram [1]
-loss loss function {ns, hs, softmax} [ns]
-bucket number of buckets [2000000]
-minn min length of char ngram [3]
-maxn max length of char ngram [6]
-thread number of threads [12]
-verbose how often to print to stdout [10000]
-t sampling threshold [0.0001]
-label labels prefix [__label__]
总结: Facebook FAIR实验室最新开源工具fastText能将训练时间由数天缩短到几秒钟,相较于基于深度学习的模型方法,在保证同等精度的前提下fastText速度上快了几个数量级。此外,fastText还能作为文本分类在实际应用中的专业工具,特别是对于大型数据集能实现相当快的训练速度。另外因其自身语言形态结构,fastText还能支持包括英语、德语、西班牙语、法语以及捷克语等多种语言。
PS : 本文由雷锋网 (搜索“雷锋网”公众号关注) 编译,未经许可拒绝转载!
via Facebook research blog
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

