HPACK 完全解析
去年五月, IETF 正式发布了 HTTP/2 协议与之配套的 HPACK 头部压缩算法。 RFC 如下:
- Hypertext Transfer Protocol Version 2 RFC 7540
- HPACK: Header Compression for HTTP/2 RFC 7541
笔者在研究 HPACK 时,翻阅了部分网上的博客与教程,不甚满意。要么泛泛而谈,要么漏洞百出,要么讲解不够完整。于是,笔者研读了 RFC7541 ,希望能写出一篇完备的 HPACK 讲解,给想要学习这个算法的朋友一些帮助。
如有不足或者疑惑之处,欢迎大家指出。
HPACK的由来
HTTP1.X 由于其设计的缺陷,已被大家诟病已久,其中头疼的问题之一,就是无意义的重复的头部。
于是出现了各种各样的解决方案, 如 Google 直接在 HTTP1.X 的基础上设计了 SPDY 协议, 对头部使用 deflate 算法进行压缩,一并解决了多路复用和优先级等问题。
而 HTTP/2 的实现就是参考了 SPDY 协议, 但是专门为头部压缩设计了一套压缩算法,就是我们的 HPACK 。
HPACK的实现
基本原理
简单的说,HPACK 使用2个索引表(静态索引表和动态索引表)来把头部映射到索引值,并对不存在的头部使用 huffman 编码,并动态缓存到索引,从而达到压缩头部的效果。
实现细节
HPACK 中有2个索引表,分别是静态索引表和动态索引表。
静态索引表
是预先定义在 RFC 里的固定的头部,这里展示部分:
Index | Header Name | Header Value
------- | ------- | ------- | 1 | :authority |
| 2 | :method | GET
| 3 | :method | POST
| 4 | :path | /
| 5 | :path | /index.html
| 6 | :scheme | http
| 7 | :scheme | https
| 8 | :status | 200
| 9 | :status | 204
| 10 | :status | 206
| 11 | :status | 304
| 12 | :status | 400
| 13 | :status | 404
| 14 | :status | 500
| 15 | accept-charset |
| 16 | accept-encoding | gzip, deflate
| ... | ... | ...
也就是说当要发送的值符合静态表时,用对应的 Index 替换即可,这样就大大压缩了头部的大小。
当然,这个表是预先定义好的,只有固定的几十个值,如果遇到不在静态表中的值,就会用到我们的动态表。
动态索引表
动态表是一个由先进先出的队列维护的有空间限制的表,里面同样维护的是头部与对应的索引。
每个动态表只针对一个连接,每个连接的压缩解压缩的上下文有且仅有一个动态表。
什么是连接,抽象的说是HTTP依赖的可靠的传输层的连接,一般来说指的是一个TCP连接。 HTTP/2 中引入了多路复用的概念,对于同一个域名的多个请求,会复用同一个连接。
那么动态表就是,当一个头部没有出现过的时候,会把他插入动态表中,下次同名的值就可能会在表中查到到索引并替换掉头部。为什么我说是可能呢,因为动态表是有最大空间限制的。
动态表的大小 = (每个 Header 的字节数的和+32) * 键值对个数
为什么要加32呢,32是为了头所占用的额外空间和计算头被引用次数而估计的值。
而动态表的最大字节数由 HTTP/2 的 SETTING 帧中的 SETTINGS HEADER TABLE_SIZE 来控制。
同时压缩时,可以插入一个字节来动态的修改动态表的大小,但是不可以超过上面预设的值。这个下面会介绍。
那么动态表是如何管理大小呢,2种情况下,动态表会被修改:
- 压缩方用上述方式要求动态修改动态表的大小。在这种情况下,如果新的值更小,并且当前大小超过了新值,就会从旧至新,不断的删除头,直到小于等于新的大小。
- 收到或发出一个新的头部,会触发插入和可能的删除操作。 RFC 里面说的比较复杂,我用等价的语义解释一下。新的值被插到队首,一样从旧到新删除直到空间占用小于等于最大值。那么在这种情况下,如果新来的头比最大值还要大,就等于变相的清除了动态表。
动态索引表中最 新 的值是索引值最 小 的,最 旧 的值是索引值最 大 的。 动态表与静态表共同组成了索引表的索引空间。
索引空间
索引空间就是动态表和静态表组成的头部与索引的映射关系。这个看起来很高深,实际上很简单。
静态表的大小现在是固定的 61, 因此静态表就是从1到61的索引,然后动态表从新到旧,依次从62开始递增。这样就共同的组成了一个索引空间,且互不冲突。
如果以后静态表扩充了,依次往后推即可。
编码解码
无符号整数编码
在 HPACK 中,经常会用一个或者多个字节表示无符号整数。在 HPACK 中一个无符号整数,并不总是在一个字节的开始,但是总是在一个字节的末尾结束。 这么说有些抽象,什么叫不是一个字节的开始。如下所示:
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | ? | ? | ? | Value | +---+---+---+-------------------+
0-2 bit可能会用于其他的标识, 那么表达数值只占了5个 bit , 因此只能表示 2^5-1 ,因此当需要表达的数值小于32时,一个字节足够表达了,如果超过了 2^n-1 以后,剩下的字节是如何编码的呢:
0 1 2 3 4 5 6 7 +-------+---+---+---+---+---+---+--- | (0/1) | ? | ? | ? | ? | ? | ? | ? | +-------+---+---+---------------+---
第一个字节的 n 个 bit 全部置1,然后假设这个数为 i, 那么 remain = i - (2^n - 1); 然后用剩余的字节表示这个 remain 值,然后首 bit 标识是否是最后一个字节,1表示不是,0表示是。
去掉首字节,就类似于用7个 bit 的字节的小端法表示无符号整数 remain 。
一个整数 0x12345678 用标准的 byte 数组 buffer 用小端法表示就是:
buffer[0] = 0x78; buffer[1] = 0x56; buffer[3] = 0x34; buffer[3] = 0x12;
那么我们整体的字节表示无符号数 i 的伪代码如下:
if I < 2^N - 1, encode I on N bits
else
encode (2^N - 1) on N bits
I = I - (2^N - 1)
while I >= 0x7f
encode (I & 0x7f | 1 << 7) on 8 bits
I = I >> 7
encode I on 8 bits
同样,解码的伪代码如下:
decode I from the next N bits
if I < 2^N - 1, return I
else
M = 0
repeat
B = next octet
I = I + (B & 0x7f) * (1 << M)
M = M + 7
while (B >> 7) & 1
return I
那么举例如果我们用 3 个 bit 作为前缀编码,
5 = ?????101 (101b = 5) 8 = ?????111 00000001 (111b + 1 = 8) 135 = 7 + 128 = ?????111 10000000 00000001 (111b + 0 + 128 * 1 = 135)
字面字符串编码
有了无符号整数编码的基础,我们可以对字符串进行编码,如下所示:
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | H | String Length (7+) | +---+---------------------------+ | String Data (Length octets) | +-------------------------------+
H : 表示是否是 huffman 编码,1 是 0 不是
StringLength : 表示随后跟随的字符串的长度,用上述的整数编码方式编码
StringData: 如果是 huffman 编码,则使用 huffman 编码后的字符串,否则就是原始串。
静态HUFFMAN编码
先简单介绍一下 huffman 编码,huffman 编码是一个根据字符出现的概率重新编排字符的二进制代码,从而压缩概率高的字符串,进而压缩整个串的长度。如果不了解的话,建议先去学习一下,这里不再赘述。
这里的 huffman 编码是静态的,是根据过去大量的 Http 头的数据从而选出的编码方案。整个静态表在这里 http://httpwg.org/specs/rfc7541.html#huffman.code
二进制编码
有了上述所有的准备,我们就可以真正的进行二进制编码压缩了。 有以下几种类型的字节流:
1 已被索引的头部
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 1 | Index (7+) | +---+---------------------------+
已被索引的头部,会被替换成如上格式: 第一个 bit 为1, 随后紧跟一个 无整数的编码表示 Index,即为静态表或者是动态表中的索引值。
2.1 name在索引 value不在索引且允许保存
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 0 | 1 | Index (6+) | +---+---+-----------------------+ | H | Value Length (7+) | +---+---------------------------+ | Value String (Length octets) | +-------------------------------+
第一个字节的前两个 bit 为 01,随后 无符号整数编码 Index 表示 name 的索引。
下面紧随一个字面字符串的编码,表示 value 。
这个 Header 会被两端都加入动态表中。
2.2 name, value都没被索引且允许保存
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 0 | 1 | 0 | +---+---+-----------------------+ | H | Name Length (7+) | +---+---------------------------+ | Name String (Length octets) | +---+---------------------------+ | H | Value Length (7+) | +---+---------------------------+ | Value String (Length octets) | +-------------------------------+
第一个字节为01000000, 然后紧随2个字面字符串的编码表示。
这个 Header 会被两端都加入动态表中。
3.1 name被索引, value未索引且不保存
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 0 | 0 | 0 | 0 | Index (4+) | +---+---+-----------------------+ | H | Value Length (7+) | +---+---------------------------+ | Value String (Length octets) | +-------------------------------+
第一个字节前四个 bit 为 0000, 随后是一个 无符号整数编码的 Index 表示 name ,然后跟随一个字面字符串编码 value 。
这个 Header 不用加入动态表。
3.2 name, value都未被索引且不保存
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 0 | 0 | 0 | 0 | 0 | +---+---+-----------------------+ | H | Name Length (7+) | +---+---------------------------+ | Name String (Length octets) | +---+---------------------------+ | H | Value Length (7+) | +---+---------------------------+ | Value String (Length octets) | +-------------------------------+
第一个字节为全0,紧跟2个字面字符串编码的 name 和 value 。
这个 Header 不用加入动态表。
4.1 name在索引表中, value不在,且绝对不允许被索引
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 0 | 0 | 0 | 1 | Index (4+) | +---+---+-----------------------+ | H | Value Length (7+) | +---+---------------------------+ | Value String (Length octets) | +-------------------------------+
和3.1是类似的,只是第一个字节第四个 bit 变成了1, 其他是一样的。
这个和3.1的区别仅仅在于,中间是否通过了代理。如果没有代理那么表现是一致的。如果中间通过了代理,协议要求代理必须原样转发这个 Header 的编码,不允许做任何修改,这个暗示中间的代理这个字面值是故意不压缩的,比如为了敏感数据的安全等。而3.1则允许代理重新编码等。
4.2 name 和 value 都不在索引表中,且绝对不允许被索引
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 0 | 0 | 0 | 1 | 0 | +---+---+-----------------------+ | H | Name Length (7+) | +---+---------------------------+ | Name String (Length octets) | +---+---------------------------+ | H | Value Length (7+) | +---+---------------------------+ | Value String (Length octets) | +-------------------------------+
和3.2类似,只是第一个字节的第4个 bit 修改为1。 对此的解释同4.1。
5 修改动态表的大小
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 0 | 0 | 1 | Max size (5+) | +---+---------------------------+
和前面的不一样,之前的都是传送数据,这个是用来做控制动态表大小的。
第一个字节前三个 bit 为001, 随后跟上一个无符号整数的编码 表示动态表的大小。上文有提过,这个数值是不允许超过 SETTINGS HEADER TABLE_SIZE 的, 否则会被认为是解码错误。
解码状态机
我们都知道,想要正确无误的解码,每个编码都要满足一个条件,就是每种编码方式,都不是另外一个编码的前缀。这里的 HPACK 的编码的最小单位是字节。我们看一下整个二进制流解码的状态机:
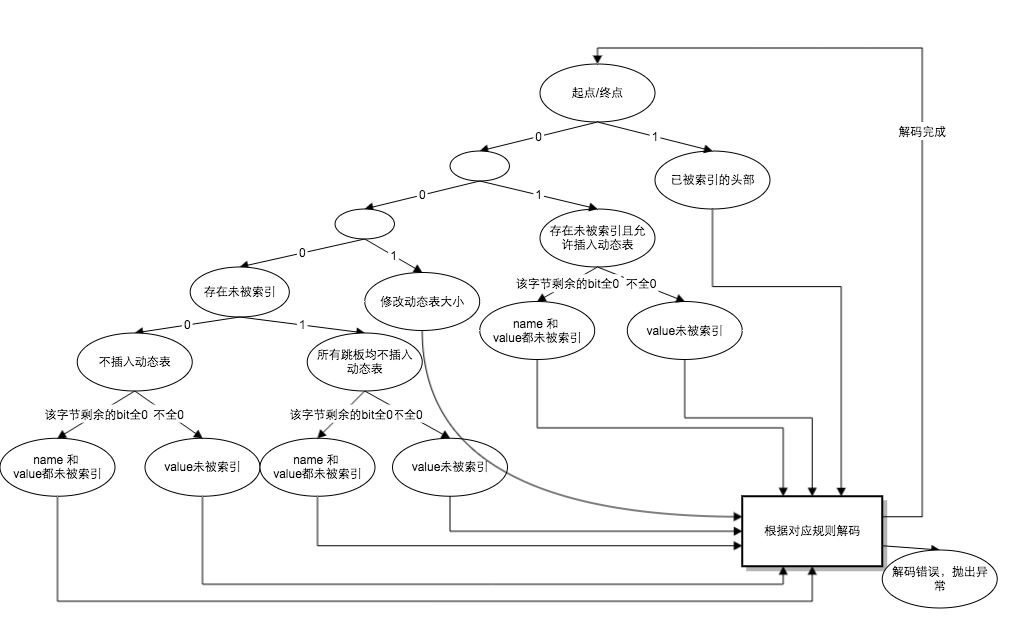
图例的根据对应规则解码就是上面介绍的编码规则。
实战举例
以下是要被编码的 Headers:
:method: GET :scheme: http :path: / :authority: www.example.com
这里大概说一下, :xxxx 为 name 的 header, 实际上是 HTTP/2 所谓的伪头的概念。就是把HTTP1.X的请求头替换成伪头对应的 name 和 value,然后再编码传输,完全的定义在这里 http://httpwg.org/specs/rfc7540.html#PseudoHeaderFields
好的,过掉整个话题,我们看整个 Headers 编码后的16进制字节如下:
8286 8441 8cf1 e3c2 e5f2 3a6b a0ab 90f4 ff
其实解析很简单,就按照上面我画的解码状态机来就好了:
82 = 10000010 -> 静态表Index = 2 -> :method: GET
86 = 10000110 -> 静态表Index = 6 -> :scheme: http
84 = 10000100 -> 静态表Index = 4 -> :path: /
41 = 01000001 -> name = 静态表4 = :authority
接着是一个字面字符串的解码,表示 header :authority 对应的 value
8c = 10001100 -> 第一个 bit 为1,表示 huffman 编码,字符串的长度为 1100b = 12
接着解析12个字节为 huffman 编码后的字符 f1e3 c2e5 f23a 6ba0 ab90 f4ff , 查表可知为 www.example.com
从而得到最后一个头部 :authority: www.example.com
小结
好的,至此我们的 HPACK 完全解析已经结束了,希望大家能通过本文对 HPACK 有更深入的了解。后面我会继续填坑,给大家带来 HTTP/2 与 OkHttp 对应的实现。
这里是笔者的个人博客地址:dieyidezui.com
也欢迎关注笔者的微信公众号,会不定期的分享一些内容给大家 
参考文献
RFC 7541
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

