数据挖掘可挖掘的知识类型
一、概念/类 描述
概念/类描述就是通过对某类对象关联数据的汇总,分析和比较,用汇总的简洁的精确的方式对此类对象的内涵进行描述,并概括这类对象的有关特征。概念描述分为:特征性描述和区别性描述。
特征性描述:是指从与某类对象相关的一组数据中提取出关于这些对象的共同特征。生成一个类的特征性描述只涉及该类对象中所有对象的同性。。
区别性描述:描述两个或者更多不同类对象之间的差异。生成区别性描述则涉及目标类和对比类中对象的共性。
数据特征的输出可以用多种形式提供:包括 饼图,条图,曲线,多维数据方和包括交叉表在内的多维表。结果描述也可以用泛化关系或规则(称作特征性规则)形式提供
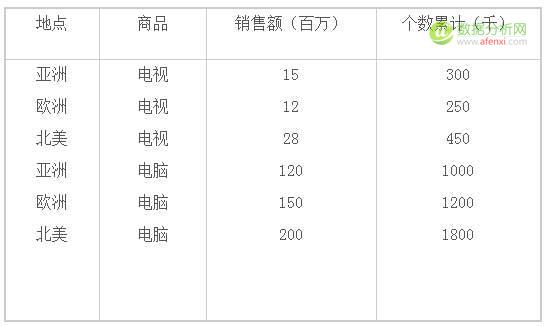
例如:利用面向属性的归纳方法(AOI),在一个商场数据库(2000销售)中进行属性归纳操作,获得了如下的归纳结果:
表2-1 AOI方法挖掘结果表格表示示意描述
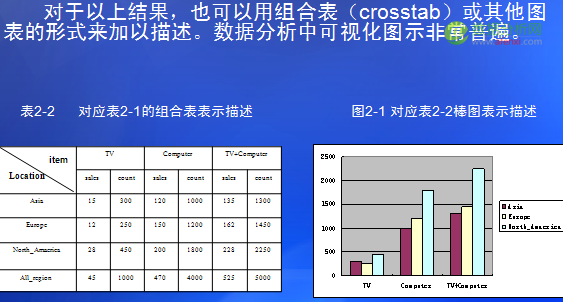
区别性描述是将目标类对象的一般特性与一个或多个对比类对象的一般特性比较,这种比较必须是在具备可比性的两个或多个类之间进行。
例如,对某校讲师和副教授的特征进行比较,可能会得到这样一条规则: “讲师:(78%)(paper<3)and (teaching course<2)”,而 “副教授:(66%)(paper>=3)and (teaching course>=2)”; 该对比规则表示该校讲师中约有四分至三的人发表论文少于三篇且主讲课程不超过一门;而对比之下该校副教授中约有三分至二 的人发表论文不少于三篇且主讲课程不少于一门。
二、关联模式
关联模式挖掘旨在从大量的数据当中发现特征之间或者数据之间的相互依赖关系。这种存在于给定数据集中的频繁出现的关联模式,又称为关联规则。关联可以分为简单关联,时序关联,因果关联等 。这些关联并不总是事先知道,而是通过数据库中数据的关联分析获得的,其对商业决策具有重要的价值,因而关联分析广泛用于市场营销,事物分析等领域。
挖掘关联知识的一个典型应用实例就是市场购物分析。根据被放到一个购物袋的(购物)内容记录数据而发现的不同(被购买)商品之间所存在的关联知识无疑将会帮助商家分析顾客的购买习惯。发现常在一起被购买的商品(关联知识)将帮助商家指定有针对性的市场策略。
比如:顾客在购买牛奶时,是否也可能同时购买面包或会购买哪个牌子的面包,显然能够回答这些问题的有关信息肯定回有效地帮助商家进行有针对性的促销,以及进行合适的货架商品摆放。如可以将牛奶和面包放在相近的地方或许会促进这两个商品的销售。
根据关联规则所涉及变量的多少, 可以分为多维关联规则和单维关联规则 , 通常,关联规则具有:X=>Y的形式,即:A1^…^Am=>B1^…^Bn的规则,其中, Ai (i属于{1,…,m}), Bj (j属于{1,…,n})是属性-值对。关联规则X => Y解释为“满足X中条件的数据库元组多半也满足Y中条件”。
例如:一个数据挖掘系统可以从一个商场的销售(交易事务处理)记录数据中,挖掘出如下所示的关联规则: age(X,”20-29”)∧income(X,”20K-30K”) Þbuys(X,”mp3”)[support=2%,confidence=60%]上述关联规则表示:该商场有的顾客年龄在20岁到29岁且收入在2 万到3万之间,这群顾客中有60%的人购买了MP3,或者说这群顾客购买MP3的概率为六成。这一规则涉及到年龄、 收入和购买三个变量(即三维),可称为多维关联规则。
对于一个商场经理,或许更想知道哪些商品是常被一起购买,描述这种情况的一条关联规则可能是:Contains(X,”computer”) =>contain(X,”software”) [support=1%,confidence=60%]上述关联规则表示:该商场1%销售交易事物记录中包含“computer”和 “software”两个商品;而对于一条包含(购买)“computer”商品的交易事物记录有60%可能也包含(购买)”software”商品。这条记录中由于只 涉及到购买事物这一个变量,所以称为单维关联规则。
三、分类
分类是数据挖掘中一项非常重要的任务,利用分类可以从数据集中提取描述数据类的一个函数或模型(也常称为分类器),并把数据集中的每个对象归结到某个已知的对象类中。从机器学习的观点,分类技术是一种有指导(我们通常称之为有监督)的学习,即每个训练样本的数据对象已经有类的标识,通过学习可以形成表达数据对象与类标识间对应的知识。从这个意义上说,数据挖掘的目标就是根据样本数据形成的类知识并对源数据进行分类,进而也可以预测未来数据的分类。(十一城注:这里的分类和日常生活中的分类含义有些不一样,它是将数据映射到预先定好的群组或者类中。所以很明显,它是有监督/指导的,即它预先定好了东西来引导别人分类。)
分类挖掘所获的分类模型可以采用多种形式加 以描述输出,其中主要的表示方法有:分类规则(IF-THEN),决策树(decision tree),数学公式(mathematical formulae)和神经网络。
决策树是一个类似于流程图的结构,每个节点代表一个属性上的值,每个分枝代表测试的一个输出,树叶代表类或者类分布。 决策树容易转换成分类规则。
神经网络用于分类的时候,是一组类似于神经元的处理单元,单元之间加权连接。
另外,最近有兴起了一种新的方法—粗糙集(rough set)其知识表示是生产式规则。
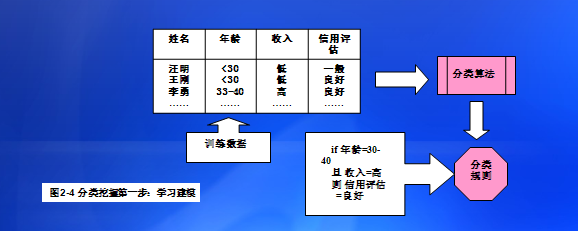
分类通常用来预测对象的类标号。例如,银行信贷部门可以根据一个顾客信用信息数据库,将功课的信用等级记录为一般或良好,然后根据挖掘得出信用良好的顾客信息特征,应用这些特征描述,可以有效发现优质客户。这一分类过程主要含有两个步骤:
(1)建立一个已知数据集类别或概念的模型。
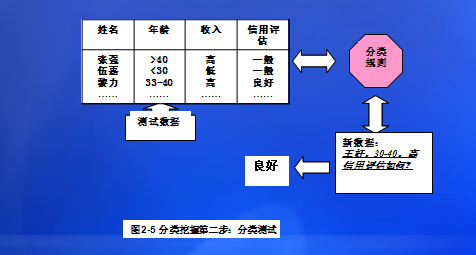
(2)对学习所获模型的准确率进行测试。如下图所示
四、 聚类分析
与分类技术不同,在机器学习中, 聚类是一种无指导学习 。也就是说, 聚类分析是在预先不知道欲划分类的情况下,根据信息相似度原则进行信息集聚的一种方法。聚类的目的是使得属于同一类别的个体之间的差别尽可能的小,而不同类别上的个体见的差别尽可能的大 。因此, 聚类的意义就在于将观察到的内容组织成类分层结构,把类似的事物组织在一起。 通过聚类,人们能够识别密集的和稀疏的区域,因而发现全局的分布模式,以及数据属性之间的有趣的关系。(十一城注:聚类和分类的区别在于聚类是无监督学习,分类是有监督学习。聚类其实也可以理解为是一种分类,只是它这种分类)
数据聚类分析是一个正在蓬勃发展的领域。 聚类技术主要是以统计方法、机器学习、神经网络等方法为基础。 比较有代表性的聚类技术是基于几何距离的聚类方法,如欧氏距离、曼哈坦(Manhattan)距离、明考斯基(Minkowski)距离等。
聚类分析广泛应用于商业、生物、地理、网络服务等多种领域。例如,聚类可以帮助市场分析人员从客户基本库中发现不同的客户群,并能用不同的购买模式来刻画不同的客户群的特征,如图2-6显示了一个城市内顾客位置的二维图,数据点的三个簇是显而易见的。聚类还可以从地球观测数据库中帮助识别具有相似土地使用情况的区域;以及可以帮助分类识别互联网上的文档以便进行信息发现等等。

五、预测
预测型知识(Prediction)是指由历史的和当前的数据产生的并能推测未来数据趋势的知识。这类知识可以被认为是以时间为关键属性的关联知识,因此上面介绍的关联知识挖掘方法可以应用到以时间为关键属性的源数据挖掘中。
前面介绍分类知识挖掘时曾经提到过: 分类通常用来预测对象的类标号 。 然而,在某些应用中,人们可能希望预测某些遗漏的或不知道的数据值,而不是类标号。当被预测的值是数值数据时,通常称之为预测。
也就是说,预测用于预测数据对象的连续取值,如:可以构造一个分类模型来对银行贷款进行风险评估(安全或危险);也可建立一个预测模型以利用顾客收入与职业(参数)预测其可能用于购买计算机设备的支出大小
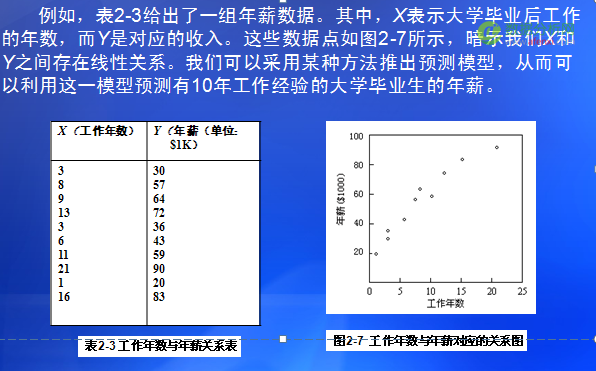
- 预测型知识的挖掘可以利用统计学中的回归方法 ,通过历史数据直接产生连续的对未来数据的预测值; 可以借助于经典的统计方法、神经网络和机器学习等技术 。无论如何, 经典的统计学方法是挖掘预测知识的基础。
六、时间序列
具有一个或多个时间属性的预测应用称为时间序列问题。时间序列是数据存在的特殊形式,序列的过去值会影响到将来值,这种影响的大小以及影响的方式可由时间序列中的趋势周期及非平稳等行为来刻画。
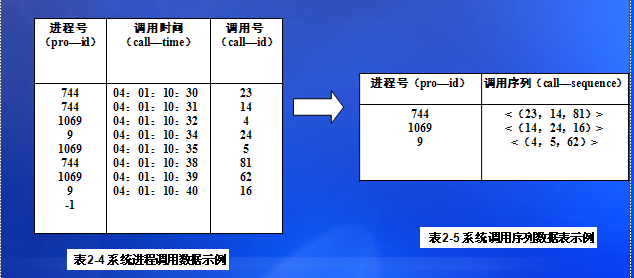
例如:系统调用日志记录了操作系统及其系统进程调用的时间序列,通过对正常调用序列的学习可以预测随后发生的系统调用序列、发现异常的调用。表2-4给出了一个系统调用数据表。 这样的数据源可以通过适当的数据整理使之成为调用序列,如表2-5,再通相应的挖掘算法达到跟踪和分析操作系统审计数据的目的。
七、偏差检测
- 偏差检测 (deviation detection)就是对数据集中的偏差数据进行检测与分析。
- 在要处理的大量数据中,常常存在一些异常数据,它们与其它的数据的一般行为或模型不一致。这里数据记录就是偏差(deviation),也就是孤立点。
- 偏差包括很多潜在的知识,如不满足常规类的异常例子、分类中出现的反常实例、在不同时刻发生了显著变化的某个对象或集合、观察值与模型推测出的期望值之间有显著差异的事例等。
- 偏差的产生可能是某种数据错误造成的,也可能是数据变异所固有的结果。从数据集中检测出这些偏差很有意义,例如在欺诈探测中,偏差可能预示着欺诈行为。
作者:十一城
来自: http://www.elevencitys.com/
注:数据分析网遵循行业规范,任何转载的稿件都会明确标注作者和来源,若标注有误或遗漏,请联系主编邮箱:afenxi@afenxi.com
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

