分类问题的常用度量方式以及具体实现
在机器学习中,通常我们要衡量一个分类器分类结果的好坏,用于评价并改进分类器。本文将整理总结常见的度量指标并举例说明该指标在sklean中是如何实现的。
1. 准确率
所有测试样本中,被正确分类的比例。当然这个比例越高越好。最大值为1。在sklean中的计算也非常简单
Examples -------- >>> importnumpyas np >>> fromsklearn.metricsimportaccuracy_score >>> y_pred = [0, 2, 1, 3] >>> y_true = [0, 1, 2, 3] >>> accuracy_score(y_true, y_pred) 0.5
1.1 混淆矩阵
为了更加精细的评价一个分类器,需要对分类结果进行更加详细的分析,这个时候就引入混淆矩阵的概念。一个混淆矩阵的每一行代表了测试样本的真实归属,而每一列代表了测试样本的预测类别。以下表为例,第一行表示类别1的真实样本个数为50,其中有43个预测结果是正确的,另外有5个预测为类别2,2个预测为类别3。 如果一个混淆矩阵的非对角线全是0,那么这个分类器将是一个完美的分类器,所有样本的预测结果都完全正确。
这样通过混淆矩阵,我们不仅可以知道预测结果的准确率,还可以知道错误的预测是怎么错误的,这样就可以有针对性地改进分类器。
| 预测类别 | ||||
| 类别1 | 类别2 | 类别3 | ||
| 实际类别 | 类别1 | 43 | 5 | 2 |
| 类别2 | 2 | 45 | 3 | |
| 类别3 | 0 | 1 | 49 | |
Examples -------- >>> fromsklearn.metricsimportconfusion_matrix >>> y_true = [2, 0, 2, 2, 0, 1] >>> y_pred = [0, 0, 2, 2, 0, 2] >>> confusion_matrix(y_true, y_pred) array([[2, 0, 0], [0, 0, 1], [1, 0, 2]])
2. 精确率、召回率和F1分值
对于一个通常的预测问题,99.2%的准确率就是一个非常不错的预测结果,但是对于非均衡分类来说,这个准确率度量是有问题的。
例如对癌症检测来说,只有0.5%的癌症患者(1为癌症,0为非癌),就算是将所有的人都检测为非癌症患者,也可以有99.5%的准确率。提高准确率,无非就是提高预测为0的概率。 但是该分类器对癌症检测来说是一个无效的分类器。
为了更好地解决这种情况,引入精确率(precision)和召回率(recall)的概念。
首先对于二分类问题,上面的混淆矩阵可以简化为如下表所示。
| 预测类别 | |||
| 1 | 0 | ||
| 实际类别 | 1 | True Positive (TP,真正例) |
False Negative (FN,伪反例) |
| 0 | False Positive (FP,伪正例) |
True Negative (TN,真反例) |
|
精确率:预测的正例中,有多少是真正例:TP/(TP+FP)
召回率:所有的正例,有多少被成功预测: TP/(TP+FN)
以癌症检测的例子来说明。精确率就是指,预测的癌症,有多少是真正的癌症;而召回率所有真正的癌症患者,有多少被检测出来了。这个也是召回率概念的来源。
实际应用中,到底用哪种度量指标更好?这个要看代价和其他因素。以垃圾邮件检测为例,把重要邮件检测为垃圾邮件的代价可能会比较大,相反垃圾邮件无法识别出来,最多就是对用户有一些干扰。 这种情况下,就要求提高precision, 而不是recall。
以癌症检测为例,如果有病人没有检测出来,则可能就有生命危险,相反如果正常人检测为癌症,则最多只是不必要的医疗浪费。 这种情况下,就要提高recall,这个时候precision可能会降低
往往这两个指标互相矛盾,提高精确率,可能会引起召回率的下降,相反提交召回率也有可能引起精确率的下降。还是以癌症检测的例子来说明。为了提高召回率,“宁可枉杀千人,不可使一人漏网”,导致的结果是有很多本来不是患者的被检测出来,导致精确率下降。
所以一般可以综合考虑recall和precision,用 F1 score 来表示:
F1 = 2PR/(P+R),意思是:如果P或者R任何一个为0,则F1也为0,如果P和R都为1,则F1=1,其他都是【0,1】之间的值
sklean中计算这几个指标的函数如下:
metrics.precision_score metrics.recall_score metrics.f1_score
3. Logloss
通常情况下,上面提到的准确率、精确率、召回率、F1等已经可以比较好地度量一个分类器的好坏了。但是这些指标有的时候不够“精细”。例如,对手写数字识别来说,预测为0的概率为90%和60%,最后结果虽然都能正确预测为0,但是由于90%更加肯定一些,所以是一个更好的分类器。这就是为什么会引入Logloss这个度量指标的原因。
logloss的计算公式为:
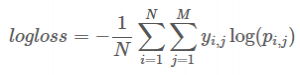
其中
N是测试数据集中的样本个数
M是类别的个数,对手写数字识别来说,M=10
P(i,j)是第i个样本预测为j类的概率
如果第i个样本属于分类j,则y(i,j)=1,否则y(i,j)=0,这个是真实的分类结果
例如0.0,0.0,0.0,1.0,0.0,0.0,0.0,0.0,0.0,0.0表示这个数字是3
所以logloss的真实含义用中文来解释就是:对每个测试样本,预测为正确结果的概率,取自然对数,累加求平均。
举例
有5个测试样本
第一种情况,每个测试样本预测为正确结果的概率为0.5,则准确率为100%
第二种情况,有4个样本预测为正确结果的概率为1,另外一个样本预测为正确结果的概率为0.1,则准确率为80%
第二种准确率相比第一种情况在下降,但是对比一下logloss的值,可以发现情况2的分数更好一些(越接近于0越好)
情况1:5×log0.5/5=-0.693
情况2:(0+0+0+0+log0.1)/5=-0.46
也就是说,logloss鼓励更加确切的预测,而不鼓励模棱两可的预测,也不鼓励高精度搞准确性
实际计算中,为了避免log0的情况出现,对预测的概率做了一个处理max(min(p.ix[i][j],1 – 1e-15),1e-15)
Examples -------- >>> fromsklearnimportmetrics >>> metrics.log_loss(["spam", "ham", "ham", "spam"], # doctest: +ELLIPSIS ... [[.1, .9], [.9, .1], [.8, .2], [.35, .65]]) 0.21616...
实际上,自己实现一个计算logloss的算法也不是一件很难的事情,源代码实现的例子如下,其中p是测试结果,y是真实结果
importpandasas pd
importnumpyas np
p = pd.read_csv('testingrst.csv',header=None)
y = pd.read_csv('result_0_1.csv',header=None)
sum=0
for i in xrange(p.shape[0]):
for j in xrange(10):
sum = sum + y.ix[i][j]*np.log(max(min(p.ix[i][j],1 - 1e-15),1e-15))
if (i%1000==0):
print i,sum
sum = sum /p.shape[0]
printsum
4. AUC
在上面的概念解释中,召回率实际上就是真正率。下面再定义另外一个概念,伪正率=FP/(FP+TN),也就是说真正的反例中,有多少被错误的识别为正例。
由于很多分类器,例如逻辑回归,随机森林,还有决策树等预测的结果不只是一个简单的label,而是预测一个样本是正例的概率。这样实际应用中就可以根据实际需要设定一个阈值,例如0.1,只要大于该值,就预测为正例,所有小于或者等于该阈值的都预测为反例。“宁可枉杀千人,不可使一人漏网”就是这个意思,降低判断的标准,只要有一点点可疑,就判断为正例。相反,如果为了避免冤枉好人,则可以将阈值设置为0.9,也就是只有非常肯定的时候,才判断为正例。
当取很多个不同的阈值的时候,将真正率和伪正率的值,绘制到一个坐标系中,就得到了ROC曲线,如下图所示,其中横轴是伪正率,纵轴是真正率。这条曲线下面的面积就是AUC。理想情况下AUC=1,伪正率为0的情况下,真正率为1。对角线上的虚线表示随机猜测的结果,也就是随机猜测时,真正率和伪正率基本上是相同的,AUC=0.5 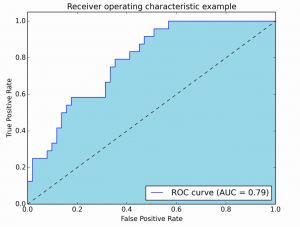
Examples -------- >>> importnumpyas np >>> fromsklearn.metricsimportroc_auc_score >>> y_true = np.array([0, 0, 1, 1]) >>> y_scores = np.array([0.1, 0.4, 0.35, 0.8]) >>> roc_auc_score(y_true, y_scores) 0.754.1 为什么使用ROC曲线 ?
既然已经这么多评价标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化,但是ROC曲线却可能保持相对稳定
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

