自己动手做聊天机器人 二十五-google的文本挖掘深度学习工具word2vec的实现原理

词向量是将深度学习应用到NLP的根基,word2vec是如今使用最广泛最简单有效的词向量训练工具,那么它的实现原理是怎样的呢?本文将从原理出发来介绍word2vec
请尊重原创,转载请注明来源网站www.shareditor.com以及原始链接地址
你是如何记住一款车的
问你这样一个问题:如果你大脑有很多记忆单元,让你记住一款白色奥迪Q7运动型轿车,你会用几个记忆单元?你也许会用一个记忆单元,因为这样最节省你的大脑。那么我们再让你记住一款小型灰色雷克萨斯,你会怎么办?显然你会用另外一个记忆单元来记住它。那么如果让你记住所有的车,你要耗费的记忆单元就不再是那么少了,这种表示方法叫做localist representation。这时你可能会换另外一种思路:我们用几个记忆单元来分别识别大小、颜色、品牌等基础信息,这样通过这几个记忆单元的输出,我们就可以表示出所有的车型了。这种表示方法叫做distributed representation,词向量就是一种用distributed representation表示的向量
localist representation与distributed representation
localist representation中文释义是稀疏表达,典型的案例就是one hot vector,也就是这样的一种向量表示:
[1, 0, 0, 0, 0, 0……]表示成年男子
[0, 1, 0, 0, 0, 0……]表示成年女子
[0, 0, 1, 0, 0, 0……]表示老爷爷
[0, 0, 0, 1, 0, 0……]表示老奶奶
[0, 0, 0, 0, 1, 0……]表示男婴
[0, 0, 0, 0, 0, 1……]表示女婴
……
每一类型用向量中的一维来表示
而distributed representation中文释义是分布式表达,上面的表达方式可以改成:
性别 老年 成年 婴儿
[1, 0, 1, 0]表示成年男子
[0, 0, 1, 0]表示成年女子
[1, 1, 0, 0]表示老爷爷
[0, 1, 0, 0]表示老奶奶
[1, 0, 0, 1]表示男婴
[0, 0, 0, 1]表示女婴
如果我们想表达男童和女童,只需要增加一个特征维度即可
word embedding
翻译成中文叫做词嵌入,这里的embedding来源于范畴论,在范畴论中称为morphism(态射),态射表示两个数学结构中保持结构的一种过程抽象,比如“函数”、“映射”,他们都是表示一个域和另一个域之间的某种关系。
范畴论中的嵌入(态射)是要保持结构的,而word embedding表示的是一种“降维”的嵌入,通过降维避免维度灾难,降低计算复杂度,从而更易于在深度学习中应用。
理解了distributed representation和word embedding的概念,我们就初步了解了word2vec的本质,它其实是通过distributed representation的表达方式来表示词,而且通过降维的word embedding来减少计算量的一种方法
word2vec中的神经网络
word2vec中做训练主要使用的是神经概率语言模型,这需要掌握一些基础知识,否则下面的内容比较难理解,关于神经网络训练词向量的基础知识我在《 自己动手做聊天机器人 二十四-将深度学习应用到NLP 》中有讲解,可以参考,这里不再赘述。
在word2vec中使用的最重要的两个模型是CBOW和Skip-gram模型,下面我们分别来介绍这两种模型
CBOW模型和Skip-gram模型
CBOW全称是Continuous Bag-of-Words Model,是在已知当前词的上下文的前提下预测当前词
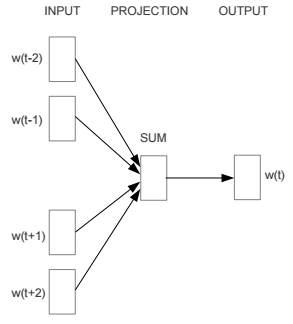
CBOW模型的神经网络结构设计如下:
输入层:词w的上下文一共2c个词的词向量
投影层:将输入层的2c个向量做求和累加
输出层:一个霍夫曼树,其中叶子节点是语料中出现过的词,权重是出现的次数
我们发现这一设计相比《 自己动手做聊天机器人 二十四-将深度学习应用到NLP 》中讲到的神经网络模型把首尾相接改成了求和累加,这样减少了维度;去掉了隐藏层,这样减少了计算量;输出层由softmax归一化运算改成了霍夫曼树;这一系列修改对训练的性能有很大提升,而效果不减,这是独到之处。
基于霍夫曼树的Hierarchical Softmax技术
上面的CBOW输出层为什么要建成一个霍夫曼树呢?因为我们是要基于训练语料得到每一个可能的w的概率。那么具体怎么得到呢?我们先来看一下这个霍夫曼树的例子:
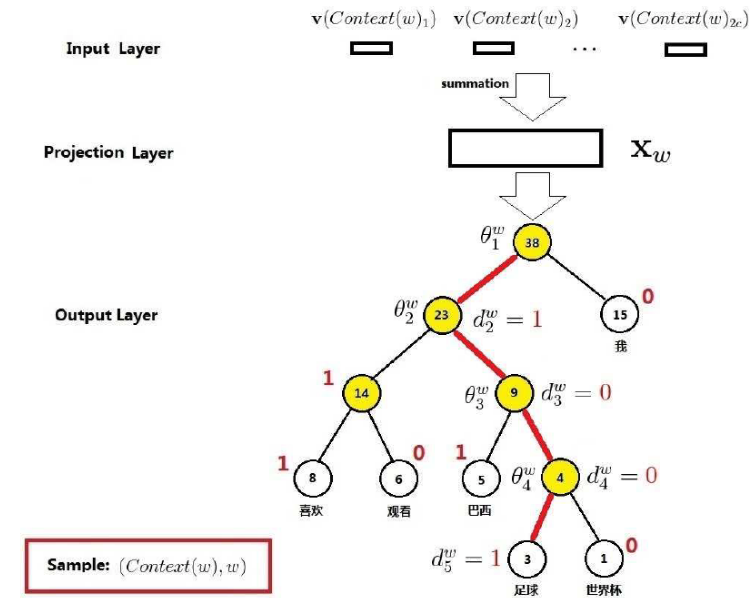
在这个霍夫曼树中,我们以词足球为例,走过的路径图上容易看到,其中非根节点上的θ表示待训练的参数向量,也就是要达到这种效果:当在投射层产出了一个新的向量x,那么我通过逻辑回归公式:
σ(xTθ) = 1/(1+e^(-xTθ))
就可以得出在每一层被分到左节点(1)还是右节点(0)的概率分别是
p(d|x,θ) = 1-σ(xTθ)
和
p(d|x,θ) = σ(xTθ)
那么就有:
p(足球|Context(足球)) = ∏ p(d|x,θ)
现在模型已经有了,下面就是通过语料来训练v(Context(w))、x和θ的过程了
我们以对数似然函数为优化目标,盗取一个网上的推导公式:
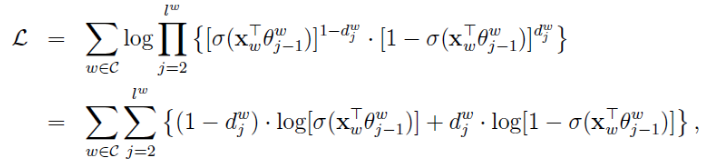
假设两个求和符号里面的部分记作L(w, j),那么有
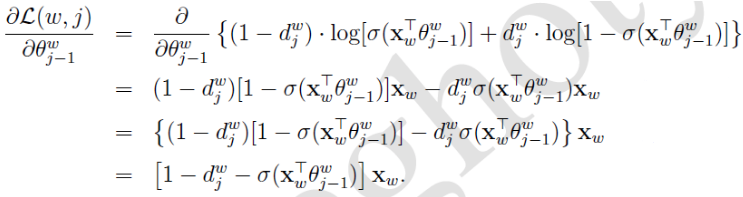
于是θ的更新公式:
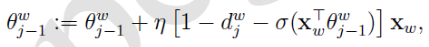
同理得出x的梯度公式:
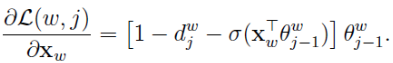
因为x是多个v的累加,word2vec中v的更新方法是:
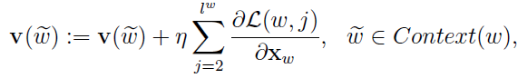
想想机器学习真是伟大,整个模型从上到下全是未知数,竟然能算出来我真是服了
请尊重原创,转载请注明来源网站www.shareditor.com以及原始链接地址
Skip-gram模型
Skip-gram全称是Continuous Skip-gram Model,是在已知当前词的情况下预测上下文
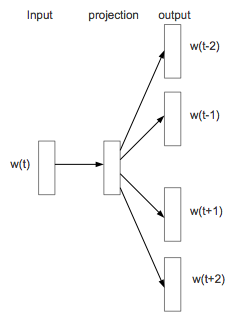
Skip-gram模型的神经网络结构设计如下:
输入层:w的词向量v(w)
投影层:依然是v(w),就是一个形式
输出层:和CBOW一样的霍夫曼树
后面的推导公式和CBOW大同小异,其中θ和v(w)的更新公式除了把符号名从x改成了v(w)之外完全一样,如下:
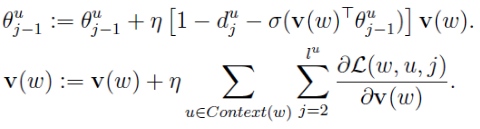
体验真实的word2vec
首先我们从网上下载一个源码,因为google官方的svn库已经不在了,所以只能从csdn下了,但是因为还要花积分才能下载,所以我干脆分享到了我的git上( https://github.com/warmheartli/ChatBotCourse/tree/master/word2vec ),大家可以直接下载
下载下来后直接执行make编译(如果是mac系统要把代码里所有的#include <malloc.h>替换成#include <sys/malloc.h>)
编译后生成word2vec、word2phrase、word-analogy、distance、compute-accuracy几个二进制文件
我们先用word2vec来训练
首先我们要有训练语料,其实就是已经切好词(空格分隔)的文本,比如我们已经有了这个文本文件叫做train.txt,内容是"人工 智能 一直 以来 是 人类 的 梦想 造 一台 可以 为 你 做 一切 事情 并且 有 情感 的 机器 人"并且重复100遍
执行
./word2vec -train train.txt -output vectors.bin -cbow 0 -size 200 -window 5 -negative 0 -hs 1 -sample 1e-3 -thread 12 -binary 1
会生成一个vectors.bin文件,这个就是训练好的词向量的二进制文件,利用这个文件我们可以求近义词了,执行:
./distance vectors.bin
Enter word or sentence (EXIT to break): 人类
Word: 人类 Position in vocabulary: 6
Word Cosine distance
------------------------------------------------------------------------
可以 0.094685
为 0.091899
人工 0.088387
机器 0.076216
智能 0.073093
情感 0.071088
做 0.059367
一直 0.056979
以来 0.049426
一切 0.042201
</s> 0.025968
事情 0.014169
的 0.003633
是 -0.012021
有 -0.014790
一台 -0.021398
造 -0.031242
人 -0.043759
你 -0.072834
梦想 -0.086062
并且 -0.122795
……
如果你有很丰富的语料,那么结果会很漂亮
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

