关于高可用的系统
 在《 这多年来我一直在钻研的技术 》这篇文章中,我讲述了一下,我这么多年来一直在关注的技术领域,其中我多次提到了工业级的软件,我还以为有很多人会问我怎么定义工业级?以及一个高可用性的软件系统应该要怎么干出来?这样我也可以顺理成章的写下这篇文章,但是没有人问,那么,我只好厚颜无耻的自己写下这篇文章了。哈哈。
在《 这多年来我一直在钻研的技术 》这篇文章中,我讲述了一下,我这么多年来一直在关注的技术领域,其中我多次提到了工业级的软件,我还以为有很多人会问我怎么定义工业级?以及一个高可用性的软件系统应该要怎么干出来?这样我也可以顺理成章的写下这篇文章,但是没有人问,那么,我只好厚颜无耻的自己写下这篇文章了。哈哈。
另外,我在一些讨论高可用系统的地方看到大家只讨论各个公司的技术方案, 其实,高可用的系统并不简单的是技术方案,一个高可用的系统其实还包括很多别的东西,所以,我觉得大家对高可用的系统了解的还不全面,为了让大家的认识更全面,所以,我写下这篇文章 。
理解高可用系统
首先,我们需要理解什么是高可用,英文叫High Availablity( Wikipedia词条 ),基本上来说,就是要让我们的计算环境(包括软硬件)做到full-time的可用性。在设计上一般来说,需要做好如下的设计:
- 对软硬件的冗余,以消除单点故障。任何系统都会有一个或多个冗余系统做standby
- 对故障的检测和恢复。检测故障以及用备份的结点接管故障点。这也就是failover
- 需要很可靠的交汇点(CrossOver)。这是一些不容易冗余的结点,比如域名解析,负载均衡器等。
听起似乎很简单吧,然而不是,细节之处全是魔鬼,冗余结点最大的难题就是对于有状态的结点的数据迁移和数据一致性的保证(无状态结点的冗余相对比较简单)。冗余数据所带来的一致性问题是魔鬼中的魔鬼:
- 如果系统的数据镜像到冗余结点是异步的,那么在failover的时候就会出现数据差异的情况。
- 如果系统在数据镜像到冗余结点是同步的,那么就会导致冗余结点越多性能越慢。
所以,很多高可用系统都是在做各种取舍,这需要比对着业务的特点来的,比如银行账号的余额是一个状态型的数据,那么,冗余时就必需做到强一致性,再比如说,订单记录属于追加性的数据,那么在failover的时候,就可以到备机上进行追加,这样就比较简单了(阿里目前所谓的异地双活其实根本做不到状态型数据的双活)。
下面,总结一下高可用的设计原理:
- 要做到数据不丢,就必需要持久化
- 要做到服务高可用,就必需要有备用(复本),无论是应用结点还是数据结点
- 要做到复制,就会有数据一致性的问题。
- 我们不可能做到100%的高可用,也就是说,我们能做到几个9个的SLA。
高可用系统的解决方案
我在《分布式系统的事务处理》中引用过下面这个图:这个图来自来自:Google App Engine的co-founder Ryan Barrett在2009年的Google I/O上的演讲《 Transaction Across DataCenter 》(视频: http://www.youtube.com/watch?v=srOgpXECblk )
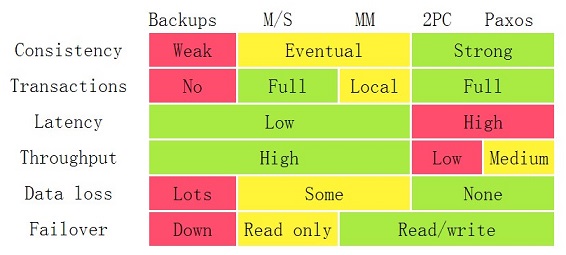
这个图基本上来说是目前高可用系统中能看得到的所有的解决方案的基础了。M/S、MM实现起来不难,但是会有很多问题,2PC的问题就是性能不行,而Paxos的问题就是太复杂,实现难度太大。
总结一下各个高可用方案的的问题:
- 对于最终一致性来说,在宕机的情况下,会出现数据没有完全同步完成,会出现数据差异性。
- 对于强一致性来说,要么使用性能比较慢的 XA系 的两阶段提交的方案,要么使用性能比较好,但是实现比较复杂的Paxos协议。
注:这是软件方面的方案。当然,也可以使用造价比较高的硬件解决方案,不过本文不涉及硬件解决方案。
另外,现今开源软件中,很多缓存,消息中间件或数据库都有持久化和Replication的设计,从而也都有高可用解决方案,但是开源软件一般都没有比较高的SLA,所以,如果我们使用开源软件的话,需要注意这一点。
高可用方案的示例
下面,我们来看一下MySQL的高可用的方案的SLA(下图下面红色的标识表示了这个方案有几个9):
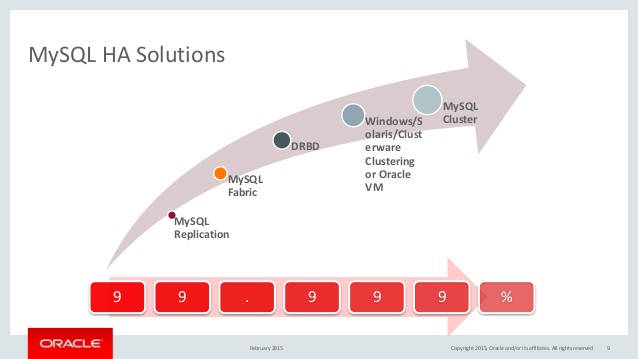
图片来源: MySQL High Availability Solutions
简单解释一下MySQL的这几个方案(主要是想表达一个越多的9就越复杂)
- MySQL Repleaction就是传统的异步数据同步或是半同步Semi-Sync(只要有一个slave收到更新就返回成功)这个方式本质上不到2个9。
- MySQL Fabric简单来说就是数据分片下的M/S的读写分离模式。这个方案的的可用性可以达到99%
- DRBD通过底层的磁盘同步技术来解决数据同步的问题,就是RAID 1——把两台以上的主机的硬盘镜像成一个。这个方案不到3个9
- Solaris Clustering/Oracle VM ,这个机制监控了包括硬件、操作系统、网络和数据库。这个方案一般会伴随着节点间的“心跳机制”,而且还会动用到SAN(Storage Area Network)或是本地的分布式存储系统,还会动用虚拟化技术来做虚拟机的迁移以降低宕机时间的概率。这个解决方案完全就是一个“全栈式的解决方案”。这个方案接近4个9。
- MySQL Cluster是官方的一个开源方案,其把MySQL的集群分成SQL Node 和Data Node,Data Node是一个自动化sharing和复制的集群NDB,为了更高的可用性,MySQL Cluster采用了“完全同步”的数据复制的机制来冗余数据结点。这个方案接近5个9。
那么,这些2个9,3个9,4个9,5个9是什么意思呢?又是怎么来的呢?请往下看。
高可用性的SLA的定义
上面那些都不是本文的重点,本文的重点现在开始,如何测量系统的高可用性。当然是SLA,全称 Service Level Agrement ,也就是有几个9的高可用性。
工业界有两种方法来测量SLA,
- 一个是故障发生到恢复的时间
- 另一个是两次故障间的时间
但大多数都采用第一种方法,也就是故障发生到恢复的时间,也就是服务不可用的时间,如下表所示:
| 系统可用性% | 宕机时间/年 | 宕机时间/月 | 宕机时间/周 | 宕机时间/天 |
|---|---|---|---|---|
| 90% (1个9) | 36.5 天 | 72 小时 | 16.8 小时 | 2.4 小时 |
| 99% (2个9) | 3.65 天 | 7.20 小时 | 1.68 小时 | 14.4 分 |
| 99.9% (3个9) | 8.76 小时 | 43.8 分 | 10.1 分钟 | 1.44 分 |
| 99.99% (4个9) | 52.56 分 | 4.38 分 | 1.01 分钟 | 8.66 秒 |
| 99.999% (5个9) | 5.26 分 | 25.9 秒 | 6.05 秒 | 0.87 秒 |
比如,99.999%的可用性,一年只能有5分半钟的服务不可用。
就算是3个9的可用性,一个月的宕机时间也只有40多分钟,看看那些设计和编码不认真的团队,把所有的期望寄托在人肉处理故障的运维团队, 一个故障就能处理1个多小时甚至2-3个小时,连个自动化的工具都没有,还好意思在官网上声明自己的SLA是3个9,这不是欺骗大众吗?。
影响高可用的因素
老实说,我们很难计算我们设计的系统有多少的可用性,因为影响一个系统的因素实在是太多了,除了软件设计,还有硬件,还有每三方的服务(如电信联通的宽带SLA),当然包括“建筑施工队的挖掘机”。所以,正如SLA的定义, 这不仅仅只是一个技术指标,而是一种服务提供商和用户之间的contract或契约,并不简简单单的只是一个技术方案 。 这种工业级的玩法,就像飞机一样,并不是把飞机造出来就好了,还有大量的无比专业的配套设施、工具、流程、管理和运营 。
简而言之,就是能持续提供可用服务的级别,不过,工业界中,会把服务不可用的因素分成两种:一种是有计划的,一种是无计划的。
无计划的宕机原因
从下图(图片来自Oracle的 《 High Availability Concepts and Best Practices 》)中,
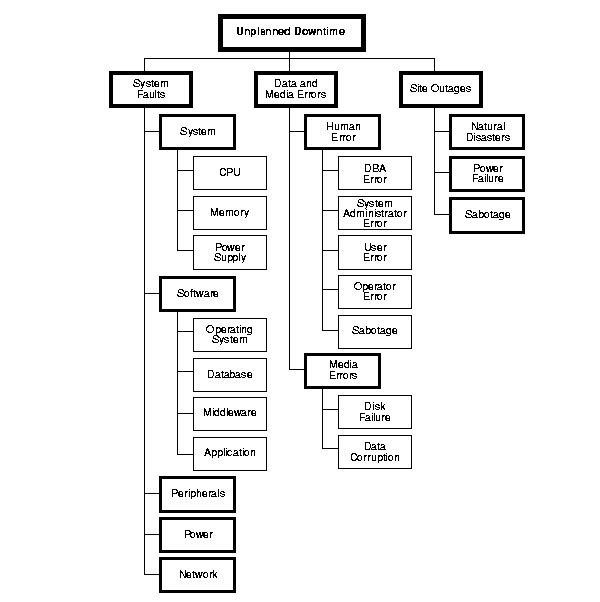 有计划的宕机原因
有计划的宕机原因
下图是有计划的宕机原因(图片来自Oracle的 《 High Availability Concepts and Best Practices 》)
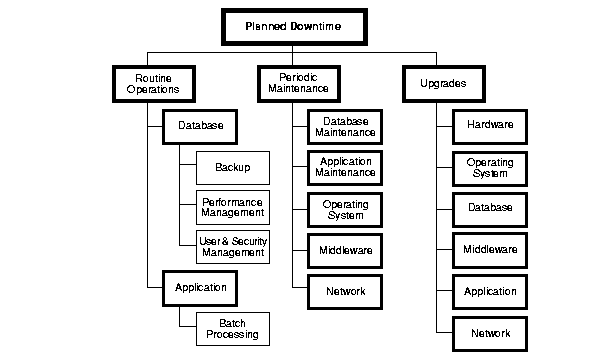
我们可以看到,上面的宕机原因包括如下:
无计划的
- 系统级的故障 – 包括主机、操作系统、中间件、数据库、网络、电源以及外围设备
- 数据和中介的故障 – 包括人员误操作、硬盘故障、数据乱了
- 还有:自然灾害、人为破坏、以及供电问题。
有计划的
- 日常任务:备份,容量规划,用户和安全管理,后台批处理应用
- 运维相关:数据库维护、应用维护、中间件维护、操作系统维护、网络维护
- 升级相关:数据库、应用、中间件、操作系统、网络、包括硬件升级
真正决定高可用系统的本质原因
从上面这些会影响高可用的SLA的因素,你看到了什么?如果你还是只看到了技术方面或是软件设计的东西,那么你只看到了冰山一角。我们再仔细想一想, 那个5个9的SLA在一年内只能是5分钟的不可用时间,5分钟啊,如果按一年出5次故障,你也得在一分钟内恢复故障,让我们想想,这意味着什么?
如果你没有一套科学的牛逼的软件工程的管理,没有牛逼先进的自动化的运维工具,没有技术能力很牛逼的工程师团队,怎么可能出现高可用的系统啊。
是的, 要干出高可用的系统,这TMD就是一套严谨科学的工程管理 ,其中包括但不限于了:
- 软件的设计、编码、测试、上线和软件配置管理的水平
- 工程师的人员技能水平
- 运维的管理和技术水平
- 数据中心的运营管理水平
- 依赖于第三方服务的管理水平
深层交的东西则是——对工程这门科学的尊重:
- 对待技术的态度
- 一个公司的工程文化
- 领导者对工程的尊重
所以,以后有人在你面前提高可用,你要看的不是他的技术设计,而还要看看他们的工程能力,看看他们公司是否真正的尊重工程这门科学。
其它
就像汽车一样,如果汽车的生产商只能做到3个9的可用性,也就是每天你的汽车要抛锚1分多钟,你是不是觉得想当的不靠谱?生命安全都得不到保障了。所以,人家把汽车的可用性做到好多个9,这完全不是找几个技工来做汽车的节奏,这就是一个严谨的科学化的工业生产的节奏。
有好些非技术甚至技术人员和我说过,做个APP做个网站,不就是找几个码农过来写写代码嘛。等系统不可用的时候,他们才会明白,要找技术能力比较强的人,但是, 就算你和他们讲一万遍道理,他们也很难会明白写代码怎么就是一种工程了,而工程怎么就成了一门科学了。其实,很多做技术的人都不明白这个道理 。
包括很多技术人员也永远不会理解,为什么要做好多像Code Review、自动化运维、自动化测试、持续集成之类这样很无聊的东西。就像我在《 从Code Review 谈如何做技术 》中提到的,阿里很多的工程师,架构师/专家,甚至资深架构师都没有这个意识,当然,这不怪他们,因为经历决定思维方式,他们的经历的是民用级的系统,做的都是堆功能的工作,的确不需要。
看完这些,最后让我们都扪心自问一下,你还敢说你的系统是高可用的了么?嘿嘿嘿 ;-)
(全文完)
 关注CoolShell微信公众账号可以在手机端搜索文章
关注CoolShell微信公众账号可以在手机端搜索文章
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

