Web字体应用指南最佳实践修炼之道(上)
 据说把名字取得特别长更容易被搜索到。
据说把名字取得特别长更容易被搜索到。
故事的起源,要从UED界两大种族前端设计师和视觉设计师的爱恨说起。
下面是设计师的视觉稿:

下面是前端开发出来的真实效果:
于是战争爆发了:

像这种视觉效果不一致问题,在日常开发中比比皆是。最近遇到的比较多的是字体问题,开了写轮眼的设计师经常抱怨手机上的字体跟设计稿不一致,前端只能无奈的回一句手机上没这字体啊...然而实际情况远比这个复杂,正义的王二小见此情况决定挺身而出,踏上了Web字体修真之路,来寻找传说中的最优解。
从0开始
这将是一次冒险,我们从0开始探索网页中的文字是如何一步步呈现在我们眼前的。计算机的数据,本质上都是由01组成的序列,不同的序列可以传达不同的信息,而同样的序列通过不同的编码和解码方式也会传达不同的信息。
我们所看到的网页,都是从服务端网络传输而来的一个个数据包通过浏览器解析而成,网络传输其实是一个很复杂的编码解码过程,你可能听过数据段,报文,分组,数据包,数据帧等关键词,这些术语其实只是OSI模型中各个层对数据单位的不同划分,最底层的表示还是以bit为单位的01。假设浏览器现在要渲染一段文本,它从服务端收到的数据包有一段信息是这样的(当然为了简化,除去报文头等信息,假设下面这段信息就页面上要展示的文本信息):
这是一串字节流,浏览器得到它的第一件事自然是解码,那么第一个问题,编码方式很多种,浏览器怎么知道用哪种方式去解码呢?
编码与解码
我们所熟知的编码方式有ASCII,GB2321,UTF-8,UTF-16等等,对于浏览器来说,它会按照以下规则去寻找数据的编码类型:
-
Web 服务器返回的 HTTP 头中的 Content-Type: text/html; charset="xxx"。其中charset="xxx"就是编码方式,当浏览器拿到这个信息之后,就能愉快的解码了;
-
如果服务端没有指定编码方式,浏览器会去网页文件的head中查找<meta charset="xxx">信息,来确定编码方式。
-
如果还没找到,那浏览器就只能自行判断编码了,或者让用户设置解码方式。
可以看到,前两步信息都是确定的,只有第三步是无法确定编码方式的。所以为了让你的页面能正常展示出来,一定得要在前两步就设定好charset编码方式,以便于浏览器以你期望的方式解码。
现代网页通常都使用utf-8的编码方式,所以我们就以此为例。utf-8是unicode字符集的一种实现方式,unicode本质上就是一个表,一个将二进制数据映射到各种文字符号的表,这个表野心很大,想要囊括世界上所有文字符号,并且他也实现了自己的目标,所以它也成了网络世界应用最广泛的一个表。
假设上面那串字节流采用了utf-8编码,那么根据utf-8字节流到unicode的编码规则:
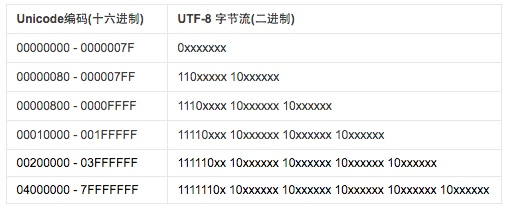
可以看到上面那段字节流全都是1110xxxx 10xxxxxx 10xxxxxx的形式,那么根据表中第三行映射关系,应该是3个utf-8字节对应1个unicode编码,将三个字节中的16个x用两个字节表示,然后转化成十六进制的unicode表示,最终可得到以下结果:
11100101 10001010 10101000 -> 01010010 10101000 -> /u52a8 11100110 10000100 10011111 -> 01100001 00011111 -> /u611f 11100101 10110000 10001111 -> 01011100 00001111 -> /u5c0f 11100101 10001001 10001101 -> 01010010 01001101 -> /u524d 11100111 10101011 10101111 -> 01111010 11101111 -> /u7aef
得到unicode编码之后,我们就可以根据unicode字符表找到对应的文字符号,最终得到了以下结果:
/u52a8/u611f/u5c0f/u524d/u7aef -> 动感小前端
如果对最终的结果不确定,可以反向验证一下:
escape('动感小前端') // "%u52A8%u611F%u5C0F%u524D%u7AEF"
得出的unicode字符数值完全一致,看来计算没错,那么紧接着第二个问题来了,浏览器该如何去展示它?就好比我知道你的名字叫什么,但并不知道怎么写一样。
寻找字体
字体的渲染是一个很复杂的过程,首先我们需要知道在Web世界中存在着五大字体家族,江湖人称font-family:serif、sans-serif、monospace、cursive和fantasy。在这五大家族下面,又演变出各个不同的字体,比如宋体,微软雅黑,Arial,Helvetica等等。同样的文字,在不同的字体下面会呈现出不同的效果:

但是,不管是什么字体,他们本质上都是一个表。你可以把这个表理解成三个部分:
-
轮廓:用来记载字符的形状;
-
编码:用来记载字符内部编号与字符形状以及unicode编码之间的映射关系;
-
封装:将上面这些东西封装成特定的文件格式
想要深入了解字体内部原理,请走支线剧情 《Fonts & Encodings》
浏览器在渲染字体时,首先会把这些文字分为不同语言的小段,然后依次确定该用哪一种字体,确定之后按照字符的unicode编码在字体中匹配相应的轮廓,并最终渲染在屏幕上。通常我们都会给页面指定一套字体规则:
font-family: Helvetica, STXihei, "Microsoft YaHei", Arial, SimSun,sans-serif;
浏览器会按照字体声明的顺序依次去寻找系统中已安装的字体,如果找到了就按照该字体渲染,没找到则依次往后查找,如果最后还是没找到,则使用浏览器设置的 神秘的默认字体 。
渲染排版
确定了字体之后,浏览器就真的要去渲染了。如果你以为把字体设置的一样就能万事大吉了,那就太天真了。即使是相同的字体,不同的环境下渲染出来的结果也是不一样的!就好比同样是须佐能乎,不同人产生的形态也是不一样的,先看两张图:


这是同一个页面在不同环境下的显示效果,其实如果在真实环境下看的话基本看不出来差别,但是对比一看差别还是很明显的。MBP下是retina屏,显示效果更细腻一些,而MBA下则更厚重些。放大来看,MBP下字体边缘有灰色的边缘(灰度渲染),而MBA下则是彩色的边缘(次像素渲染)。
可以看到,同样是Mac系统+Chrome浏览器,只是版本号稍微不同,渲染效果就会有所差别。更别说在Windows和Android上了。那么造成这种差异的原因是什么呢?
排版引擎
不同浏览器有着不同的渲染引擎,不同的操作系统上面也有不同的文字排版引擎,而浏览器在渲染页面文本的时候都会调用系统的文字排版引擎。不同的排版策略就会造成不同的渲染结果。
Mac使用的排版引擎为CoreText,Windows7为DirectWrite/GDI,Windows XP则使用GDI。我们不会深入探索各个排版引擎的原理(想要深入了解Web字体渲染知识,可以去 Typekit 上了解更多),只需要知道不同的渲染引擎可能会造成字体有细节上的差异。即使是同一种渲染引擎,采用不同的渲染策略,比如灰度渲染和亚像素渲染,得出的效果也是不一样的。
Core Text 渲染引擎

DirectWrite渲染引擎

GDI渲染引擎,开启标准抗锯齿

GDI渲染引擎,无抗锯齿

由此可看出排版引擎渲染策略的差异是造成字体显示效果不一致的根本原因之一,但是这种差异非常之小,对于普通用户来说,根本不会注意到这些细节,所以前端工程师大可不必为此操心。
至此,我们终于走完文字从0渲染到屏幕上的整个过程。
诸子百家
之前有提到,当浏览器没有找到所声明的字体时,会使用默认字体。问题就在于,这个默认字体到底是什么字体呢?不同设备之间的默认字体又分别是什么?影响默认字体的因素又有哪些呢?
在旧PC时代,统治人类的主要是windows和mac两大阵营,我们扳着手指头都能列出各大平台和浏览器上的默认字体。但是到了如今的无线乱世,安卓的开源让每个设备厂商都可能会有自己独特的默认字体,这对网页的视觉统一性又带来了巨大的挑战。
裸奔字体
裸奔字体就是你的页面不设置任何样式,浏览器呈现出的默认字体,我写了个小 demo ,你可以点击试试看你浏览器上面的裸奔字体是啥,也可以扫码看看手机上的情况:

在 CrossBrowserTesting 上跑了一下效果如下:
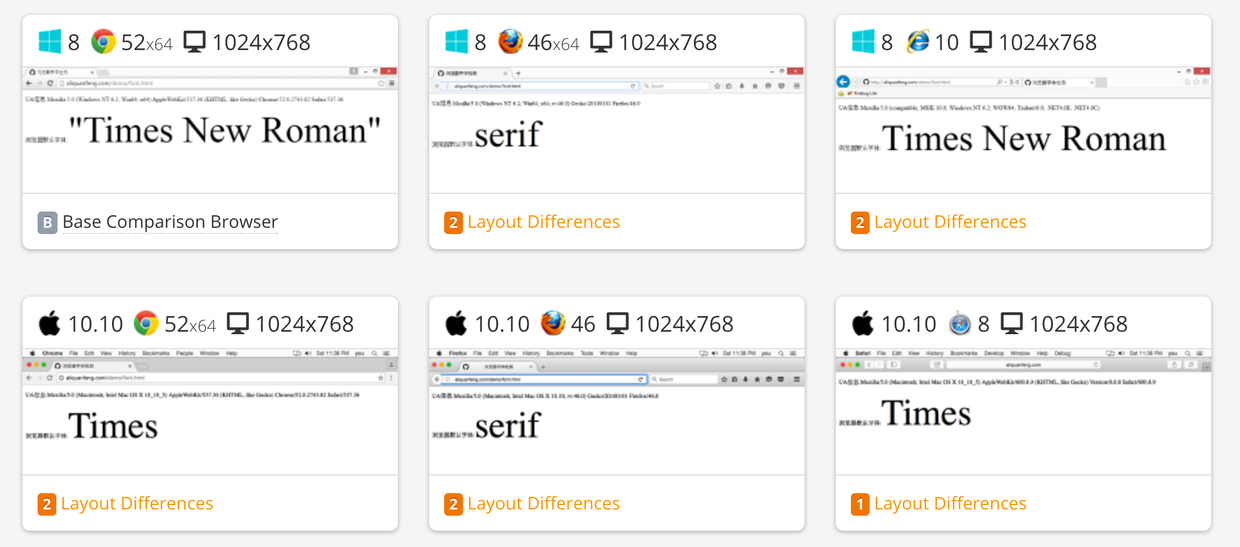 而在本人真机下的效果:
而在本人真机下的效果:

很明显能看出,裸奔字体千变万化,根本不靠谱!
安全字体
好在,现在已经没有人裸奔了,一般都会在页面中手动声明一下字体,比如百度首页是这样的:
body{font: 12px arial;} // 写的这么精简是为了省流量么...
谷歌首页是这样:
body{font-family: arial,sans-serif;} // 好歹加了字体族
天猫首页是这样的:
body{font: 12px/1.5 tahoma,arial,"/5b8b/4f53";}
淘宝首页是这样的:
body{font: 12px/1.5 tahoma,arial,'Hiragino Sans GB','/5b8b/4f53',sans-serif;}
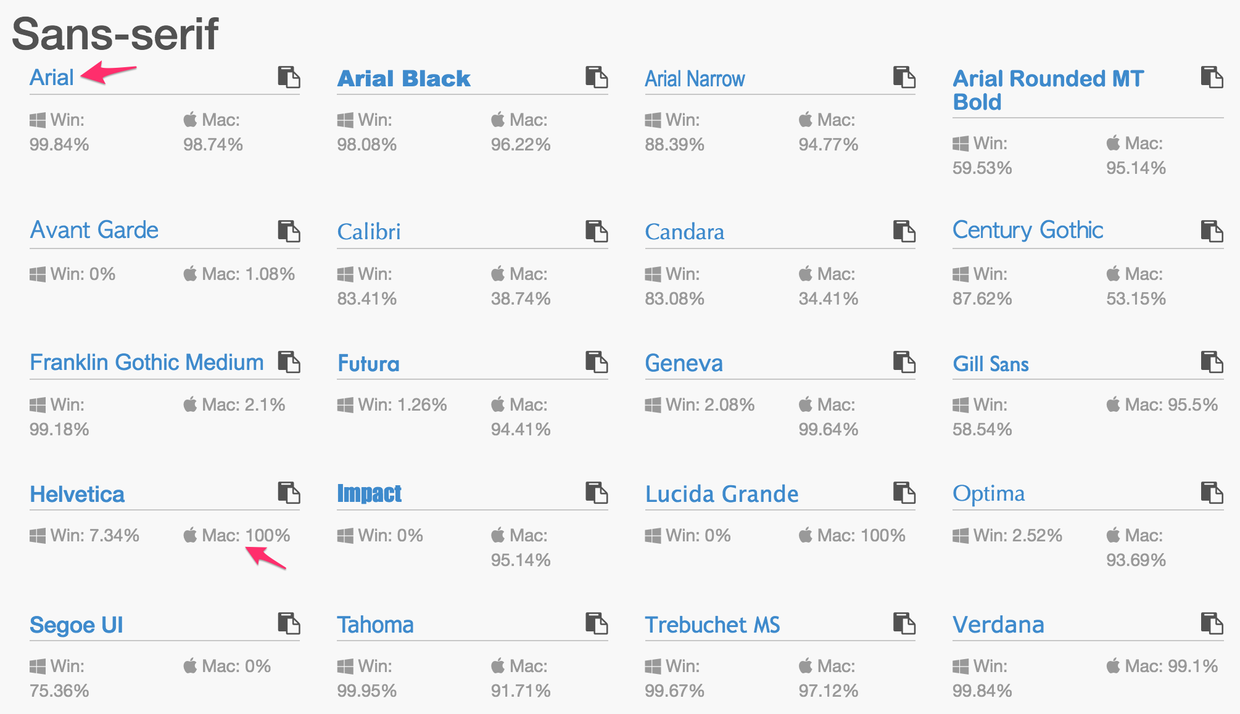
上面四种写法可能都有自己的考虑,但仅从终端字体表现的角度来看,很明显淘宝的写法更专业。Arial可谓是支持性最广的字体了,所以大家都用上了,这种被大多数系统所默认支持的字体,就是Web安全字体。
CSS Font Stack 上有对Web安全字体的整理,建议设计师们在作图的时候多考虑一下,这样能一定程度上降低视觉差异。并且某些字体其实长得还是蛮像的,你还可以使用安全字体来代替长相相似的非安全字体。
到目前为止,我们所做的一切考虑就是让页面字体效果在不同终端下尽可能保持一致,初步结论就是要使用安全字体,然而设计师并不这样想。设计师一般会使用逼格比较高的非安全字体,比如兰亭细黑,苹方字体。一旦浏览器发现系统没有这些字体,就会不断降级,最坏的情况,就是一直降级到默认字体。所以通常我们会在font-family最后加上一个默认的字体族,比如sans-serif,这样浏览器在最坏的情况下也能使用特定的字体族,并在该字体族下选择一名指定字体来展示。
那么在这些指定的种族背后,被选中的孩子们到底都有谁呢?
神秘的默认字体
首先系统会默认安装一些字体,维基上有对Win/Mac内置字体的整理:
-
Windows 字体列表
-
Mac OS X 字体列表
然后当你安装软件时,有可能会附带安装一些字体,这样你系统上能支持的字体又变多了。在上面那份列表中,Win/Mac共同支持的字体只有Arial, Verdana, Tahoma, Trebuchet MS, Georgia等少数Web安全字体,对于Win/Mac平台实际字体效果分析,请参考此文:
跨平台字体效果浅析: https://isux.tencent.com/5058...
重点说下无线端, iOS Fonts 和 iOS Font List 网站整理了一份各个版本的iOS字体清单,可以很方便的查出各版本支持情况:
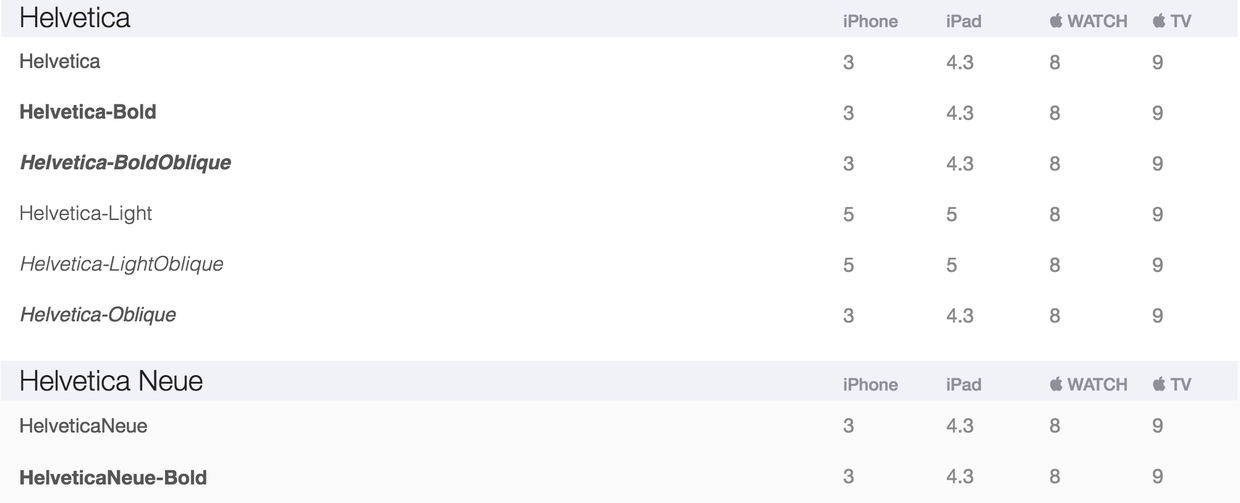
Helvetica字体完美支持:
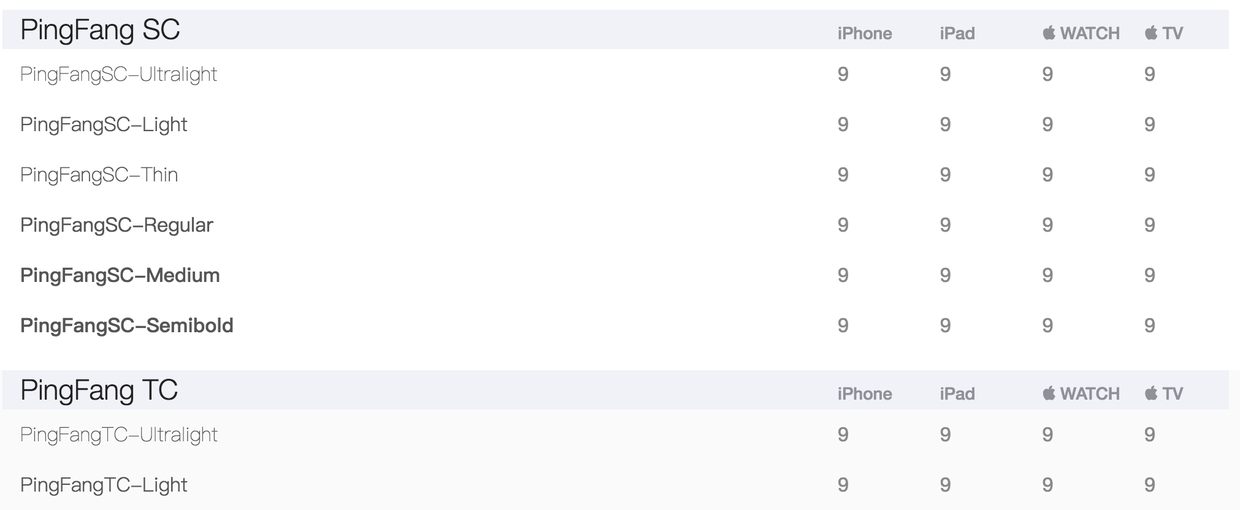
苹方字体从iOS 9 才开始支持:
虽然方便,但毕竟第三方网站,不排除数据有误的情况,于是附上官网声明的字体清单:
-
iOS 5:字体列表
-
iOS 6:字体列表
-
iOS 7:字体列表
对于安卓, 原生的安卓 使用的是Droid Sans(英文/数字)和Droidsansfallback(中文),4.0后修改为Google的开源字体Roboto。而非原生安卓,实在没有总结性可言。比如小米和华为用了方正兰亭黑,锤子则使用了华文黑体,并且同一厂商下的不同手机品牌,同一品牌的不同型号默认字体都可能不同,不做展开。
一张图总结一下:
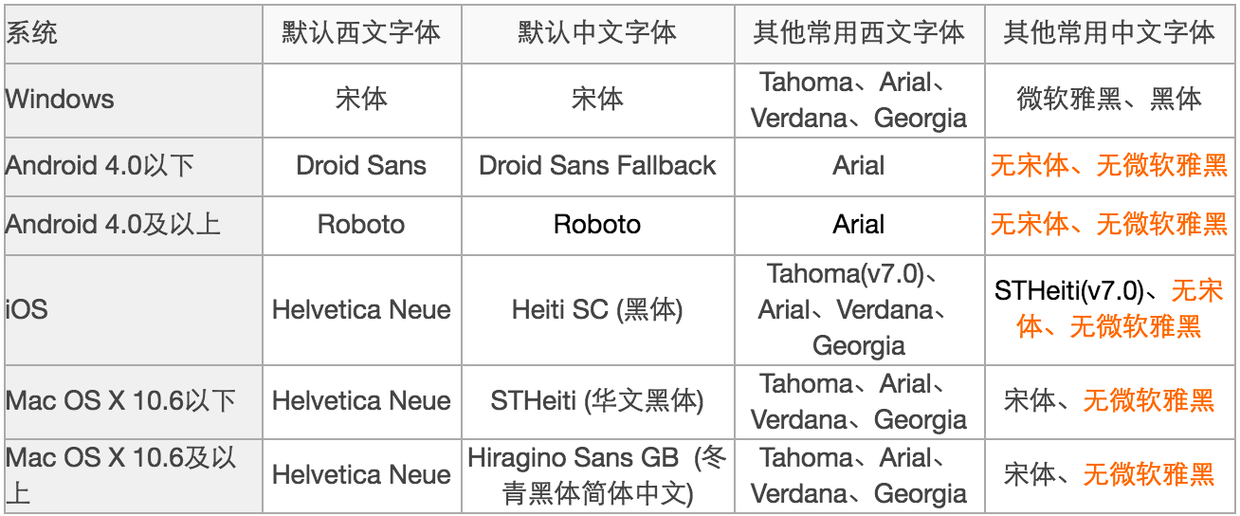
哦,忘了还有Windows Phone,WP默认英文字体是Segoe,中文字体在WP8以前是雅黑,WP8之后是方正等线体。
哦,忘了还有YunOS,貌似是方正兰亭细黑...
强大的自定义字体
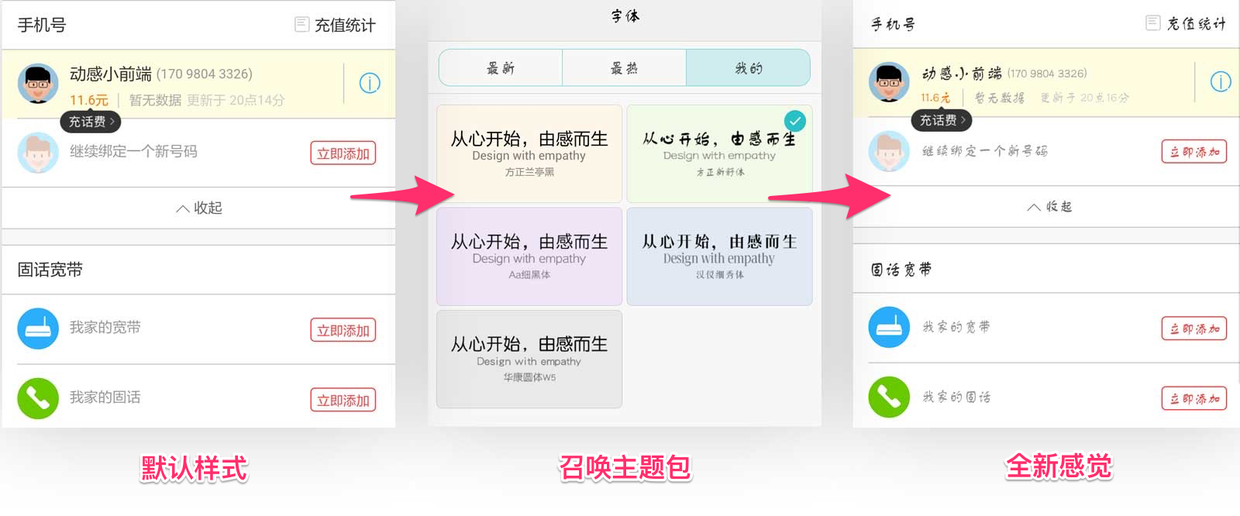
是的,用户可以选择自己喜欢的字体。你永远不知道用户会干什么,什么安全字体,默认字体,一个主题包下来全都是浮云:
用户修改系统字体:
当然这不是最绝的,换个字体最多样子变了,最绝的是用户开启老人机模式,放大字体!
普通-放大模式对比:
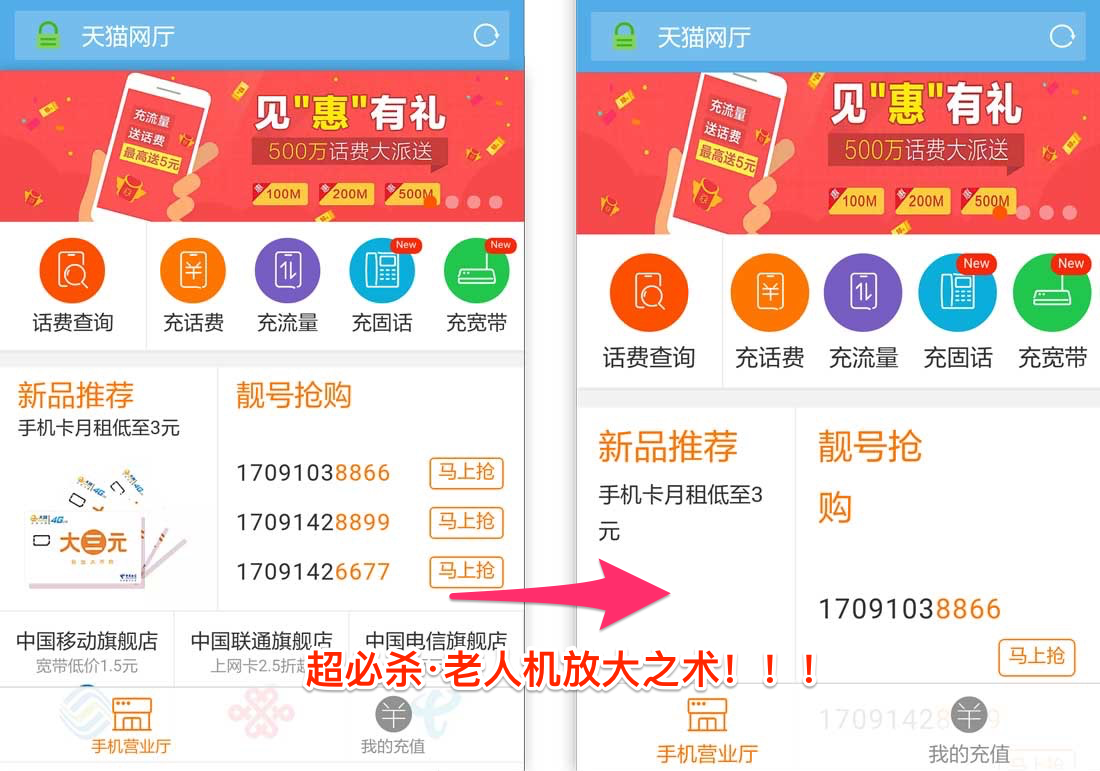
这两招一出,基本会给设计师和前端造成10000+伤害,不过我们仍然可以做点什么:
-
严格控制页面布局,字体超出部分截断,保证页面正常显示;
-
监测页面缩放情况并给予用户提示;
-
页面自适应或者,针对老人模式单独开发一套页面。
小结
看到这里王二小已经残血,稍微修整总结一下,字体表现不一致的根本原因有:
-
排版引擎渲染策略差异(影响小,不可规避)
-
各终端默认字体设置差异(影响中,可规避)
-
用户手动设置自定义字体(影响大,不可控)
目前为止我们能做的就是尽量使用Web 安全字体,针对不同终端对font-family字体选择顺序进行优雅降级,并设置默认字体族来规避风险。
但只做到这些还远远不够,我们完全处于被动状态,一切都依赖于终端环境的字体情况,并且还没考虑到字体格式,中英混排,字体动画,字体优化,Web标准技术等方面。接下来我们要主动出击,站在巨人的肩膀上去各个击破,打怪升级,去寻找Web字体应用最佳实践之道。
冒险越来越深入了,等待王二小的将会是什么呢?请看下集:

参考资料
以下是相关参考资料,若想深入了解,建议仔细研读。
Web 字体的选择和运用
https://blog.coding.net/blog/...
网页字体优化
https://developers.google.com...
字体的各个概念术语
http://www.zhihu.com/question...
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

