Kafka In Action 1
Kafka 简介
准备写一个Kafka系列,用于了解分布式消息系统的架构。
在大数据的时代, 所有的信息都是有用的(用户行为data, 应用性能记录,日志文件,事件消息等等),所以相应的对于消息中间件也产生其他的需求:
a. 基本保证,需要持续化消息,任何消息都不能丢失,并且可以存储大量的消息。
b. 面对大量的client,可以支持相当高的并发查询和写入
c. 分布式部署,可以横向扩展
d. 实时性,producer产生了消息,consumer必须立刻可以查看。
针对这样的一些需求,Kafka就孕育而生了。下面kafka简单消费者生产者的图
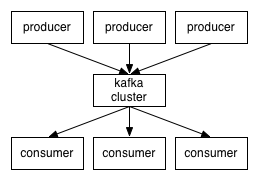
Kafka Architecture
首先简单介绍Kafka几个关键的组件:
Topic: topic可以简单理解消息的一个分类, producer发送消息和consumer消费消息都会依赖这个topic, topic可以分为多个partition, partition可以理解一个topic消息的量太大,对它进行拆分,这样就可以提高并发消费的能力。
Broker: 一个kafka的集群含有多个server, 每个server就含有一个或者多个broker, 每次topic的创建都会有与broker相关,每次produer发布消息和consumer消费消息都会跟broker打交道。
Producer: Produer发布消息针对某个topic,会选择这个topic里面的一个合适的partition,进行发送。
Consumer: Consumer就是注册某个topic, 然后接受发布的消息
ZooKeeper: ZooKeeper用来协调Broker和consumers, 并且管理broker和consumer存活。
kafka可以部署多种cluster模式:
- 单个节点 —> 单个broker cluster
- 单个节点 —> 多个broker cluster
- 多个节点 —> 多个broker cluster
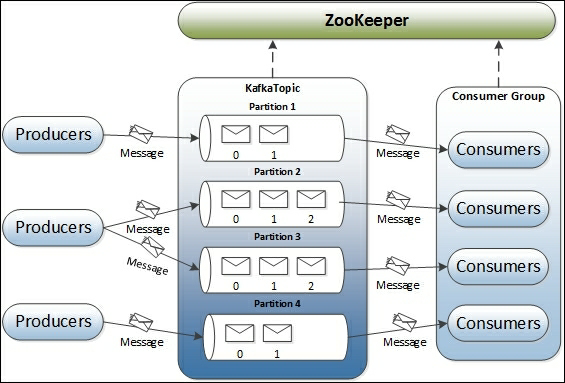
Kafka 重要模块简介
Partition
首先来看看重要的Partition,
针对Kafka的topic, Partition就是map到的一个逻辑log,这个log由多个segment file组成的,每个partition都含有有序的,一组不可变的消息。当一个消息从producer发送到partition的时候,broker就会把这个message加到最后一个segment里面。当达到了一定message的时候或者一定的时间,就会把segment flush到磁盘,一旦segment被flush了,这时候consumer就可以去消费了。
所有Partition里面的message, 都被赋值了一个offset, 用来唯一标识一个message在partition里面.
每个Partion可以配置多个replicated在多个server间用来做fault tolerance.
每个Partition要么充当着 leader, 或者 充当着 follwers的角色,leader就全心全意地负责读写请求,然而follower则是异步地从leader那边同步信息过来。
Kafka动态维护一个ISR(in-sync replicas)的集合,这种ISR里面partition几乎都是和leader同步,如果follower挂掉了或者没有跟leader及时同步,则会从in-sync里面移除。
当一条消息提交,意味着所有in-sync里面的follwoer都同步了,这意味着无需担心leader挂掉,数据丢失的情况。当然producer是可以选择是否等待消息提交。
当leader当掉的时候,在ISR里面的follower就会自动变成新的leader,这个ISR的信息就是维护在zookeeper里面的,zookeeper随时监控着这些partition的生存情况。
Consumer
Kafka Consumer的设计根据传统的消息平台consumer, consumer group都一样。
每个topic的消息都会被一个consumer groups里面的consumer消费,意识说一个consumer group里面有多的consumer的时候,只会有一个consumer接受到一个topic消息。如果想要一个topic的消息被多个consumer消费,那么这个consumer需要在不同的consumer group里面。
consumer总是从一个特定的partition里面顺序的消费,然后保存一个offset,来显示这个consumer消费了多少的消息。根据Kafka的设计,broker是无状态的,所以任何消费的信息都是保存在consumer端的,broker并不保存这条记录被谁消费。
所以Kafka有以下三种消息保证:
- 消息不会被重发,但是可能丢失
- 消息可以能被重发,但是绝不丢失
- 消息且只会被发送一次
假设consumer处理消息分为三个阶段,读取消息,处理消息,然后保存更新offset,
那么我们看下第一种情况,consumer接受到了消息,然后更新offset, 在没有处理消息前就crash掉了,接着另外一个consumer来接受的时候,发现offset已经被更新,然后就去取下一条消息,这时候上一条消息就被丢弃了。第二种情况,consumer同样接受到了消息,但是先去处理了消息,但是在没有保存offset之前就crash掉了,接着另外一个consumer来接受的时候,发现offset还是以前那个,这时候就会再去拉取一次,这样就造成了重复投递了。第三种情况,其实保证处理消息和更新offset在同一个事务中,这时候就可以保证只会投递一次。
Summary
简单介绍了Kafka的架构,以前我最搞不懂的是,如何做到replication, 只要明白kafka的replication是针对partition的,而且是ISR进行leader, follower的同步,并且整个kafka的并发能力取决于partition的个数.
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

