SeaJS从入门到原理
最近项目中抛弃传统的 <script> 而改用 SeaJS 这样的 JS 模块加载器了,确实模块加载器对于代码的可维护性带来了较大的提升。
1、前言
SeaJS 是一个模块加载器,模块加载器需要实现两个基本功能:
- 实现模块定义规范,这是模块系统的基础。
- 模块系统的启动与运行。
下文会围绕模块定义规范以及模块系统的启动与运行两方面进行讲解,最后理清一下模块加载大体流程,以及说明与RequireJS的主要区别。
2、define
2.1、CMD规范
CMD 规范的前身是Modules/Wrappings规范。
SeaJS更多地来自 Modules/2.0 的观点,同时借鉴了 RequireJS 的不少东西,比如将Modules/Wrappings 规范里的 module.declare改为 define 等。
SeaJS遵循的CMD(Common Module Definition) 模块定义规范就是属于Modules/2.0流派阵营。
在 CMD 规范中, 一个模块就是一个文件 。代码的书写格式如下:
define(factory)
- factory 为对象、字符串时,表示模块的接口就是该对象、字符串。
- factory 为函数时,表示是模块的构造方法。执行该构造方法,可以得到模块向外提供的接口。factory默认会传入三个参数:require、exports 和 module。
// factory 为对象
define({"foo":"bar"});
// factory 为函数
define(function(require, exports, module) {
// 模块代码
});
2.2、Modules/Transport 规范
SeaJS 只支持 CMD 模块的话,没法实现 JS 文件的合并了,所以SeaJS 还支持一种 Transport 格式。
Transport 格式其实就是加上了名字的 CMD 模块,SeaJS 在遇到这种模块时通过定义的 id 来缓存模块:
define(id?, deps?, factory)
id:模块标识。
deps:一个数组,表示模块依赖。
在用普通压缩工具压缩时,如果项目需要支持 IE,务必写上第一个参数id或通过工具提取 id;而且如果项目对性能有要求,上线后需要合并文件,也确保手工写上 id 参数。
如何理解:SeaJS 只支持 CMD 模块的话,没法实现 JS 文件的合并了?
没有id的两个模块JS文件a.js和b.js合并成一个文件index.js如下:
// a.js
define(function(require, exports){
exports.add = function(a, b){
returna + b;
};
});
// b.js
define(function(require){
vara =require('./a');
varc = a.add(1,2);
alert(c);
});
首先,CMD 规范 中一个模块就是一个文件,一个文件里面定义了两个,所以出现异常也不奇怪了。
另外,CMD 模块没有显式地指定该模块的 id,同时SeaJS 会用这个 JS 文件的 URL 作为它的 id ,并缓存 id 与 模块之间的关系,因此 只有最后一个定义的 CMD 模块会被识别 ,因为前面定义的模块都被它覆盖了。
实际上在版本 1.3.1 之前,有一个特性叫做 firstModuleInPackage ,即当一个文件里有多个 define 时,默认将第一个define里的模块作为主模块进行返回。由于各种原因作者去掉了这个特性。
3、factory参数
3.1、factory参数的使用如下:
// 所有模块都通过 define 来定义
define(function(require, exports, module){
// 通过 require 引入依赖,获取模块 a 的接口
vara =require('./a');
// 调用模块 a 的方法
a.doSomething();
// 通过 exports 对外提供接口foo 属性
exports.foo = 'bar';
// 对外提供 doSomething 方法
exports.doSomething = function(){};
// 错误用法!!!
exports = {
foo: 'bar',
doSomething: function(){}
};
// 正确写法,通过module.exports提供整个接口
module.exports = {
foo: 'bar',
doSomething: function(){}
};
});
3.2、require:Function
-
require是一个函数方法,用来获取其他模块提供的接口,而且是同步往下执行。require的模块不能被返回时,应该返回null。
-
require.async(id, callback?):用来在模块内部异步加载模块,并在加载完成后执行指定回调。require的模块不能被返回时,callback应该返回null。callback接受返回的模块作为它的参数。
-
require.resolve(id):不会加载模块,只返回解析后的绝对路径。
注意事项:
- factory第一个参数必须命名为 require 。
例外:在保证 id 和 dependencies 的预先提取下,可以调用任何普通 JS 压缩工具来进行压缩,require 参数可以被压缩成任意字符,或者在工具中定义不要压缩 require 参数;建议采用配套的构建工具spm来压缩、合并代码。 - 不要重命名 require 函数,或在任何作用域中给 require 重新赋值。
- require 的参数值必须是字符串直接量。
为什么那么死规定?!
首先你要知道SeaJS 是如何知道一个模块的具体依赖的。SeaJS 通过 factory.toString() 拿到源码,再通过正则匹配 require 的方式来得到依赖信息。这也是必须遵守 require 书写约定的原因。
有时会希望可以使用 require 来进行条件加载,如下:
if(todayIsWeekend) {
require("play");
} else{
require("work");
}
在浏览器端中,加载器会把这两个模块文件都下载下来。 这种情况下,推荐使用 require.async 来进行条件加载。
3.3、exports:Object
用来在模块内部对外提供接口。
exports 仅仅是 module.exports 的一个引用。在 factory 内部给 exports 重新赋值时,并不会改变 module.exports 的值。因此给 exports 赋值是无效的,不能用来更改模块接口。
3.4、module:Object
- module.uri:解析后的绝对路径
- module.dependencies:模块依赖
- module.exports:暴露模块接口数据,也可以通过 return 直接提供接口,因个人习惯使用。
对 module.exports 的赋值需要同步执行,慎重放在回调函数里,因为无法立刻得到模块接口数据。
4、模块标识id
模块标识id尽量遵循路径即 ID原则,减轻记忆模块 ID 的负担。
模块标识id会用在 require、 require.async 等加载函数中的第一个参数。
三种类型的标识:
-
相对标识:以 . 开头(包括.和..),相对标识 永远相对当前模块的 URI 来解析 。
-
顶级标识: 不以点(.)或斜线(/)开始 , 会相对模块系统的基础路径 (即 SeaJS配置 的 base 路径) 来解析。
seajs.config({
base:'http://code.jquery.com/'
});
// 在模块代码里:
require.resolve('jquery');
// 解析为 http://code.jquery.com/jquery.js
- 普通路径:除了相对和顶级标识之外的标识都是普通路径,相对当前页面解析。绝对路径和根路径也是普通路径。绝对路径比较容易理解。根路径是以“/”开头的,取当前页面的域名+根路径,如下所示:
// 假设当前页面是 http://example.com/path/to/page/index.html
require.resolve('/js/b');
// 解析为 http://example.com/js/b.js
如上所示, /js/b 可省略后缀.js,但是”.css” 后缀不可省略。
SeaJS 在解析模块标识时,除非在路径中有问号(?)或最后一个字符是井号(#),否则都会自动添加 JS 扩展名(.js)。
5、模块系统的启动与运行
通过define定义许多模块后,得让它们能跑起来,如下:
<scripttype="text/javascript"src="../gb/sea.js"></script>
<script>
seajs.use('./index.js');
</script>
直接使用 script 标签同步引入sea.js文件后,就可以使用seajs.use(id, callback?)在页面中加载模块了!
最佳实践:
- seajs.use 理论上只用于加载启动,不应该出现在 define 中的模块代码里。
- 为了让 sea.js 内部能快速获取到自身路径,推荐手动加上 id 属性:
<scriptsrc="../gb/sea.js"id="seajsnode"></script>
讲到seajs.use,当然要提一下Sea.js 的调试接口。
- seajs.cache:Object,查阅当前模块系统中的所有模块信息。
- seajs.resolve:Function,利用模块系统的内部机制对传入的字符串参数进行路径解析。
- seajs.require:Function,全局的 require 方法,可用来直接获取模块接口。
- seajs.data:Object,查看 seajs 所有配置以及一些内部变量的值。
- seajs.log:Function,由 seajs-log 插件提供。
- seajs.find:Function,由 seajs-debug 插件提供。
6、 模块加载大体流程
模块加载大体流程:
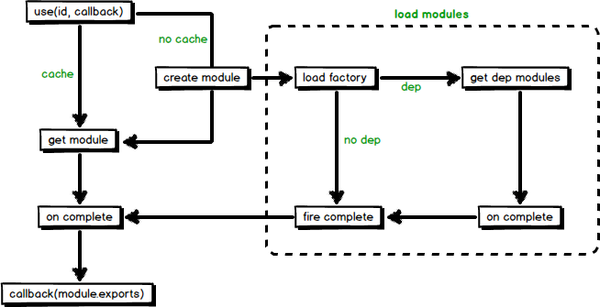
文字描述:
- 通过 use 方法来加载入口模块,并接收一个回调函数, 当模块加载完成, 会调用回调函数,并传入对应的模块作为参数。
- 从缓存或创建并加载 来获取到模块后,等待模块(包括模块依赖的模块)加载完成会调用回调函数。
- 在图片虚线部分中,加载factory及分析出模块的依赖,按依赖关系递归执行 document.createElement(‘script’) 。
7、与RequireJS的主要区别
7.1、遵循的规范不同
RequireJS 遵循 AMD(异步模块定义)规范,SeaJS 遵循 CMD (通用模块定义)规范。
7.2、factory 的执行时机不同
SeaJS 按需执行依赖 避免浪费,但是require时才解析的行为对性能有影响。
SeaJS是异步加载模块的没错, 但执行模块的顺序也是 严格按照模块在代码中出现(require)的顺序 。
RequireJS更遵从js异步编程方式, 提前执行依赖 , 输出顺序取决于哪个 js 先加载完 (不过 RequireJS 从 2.0 开始,也改成可以延迟执行)。如果一定要让 模块B 在 模块A 之后执行,需要在 define 模块时申明依赖,或者通过 require.config 配置依赖。
如果两个模块之间突然模块A依赖模块B:SeaJS的懒执行可能有问题,而RequireJS不需要修改当前模块。
当模块A依赖模块B,模块B出错了:如果是SeaJS,模块A执行了某操作,可能需要回滚。RequireJS因为尽早执行依赖可以尽早发现错误,不需要回滚。
define(['a','b'],function(A, B){
//运行至此,a.js 和 b.js 已下载完成
//A、B 两个模块已经执行完,直接可用
returnfunction(){};
});
7.3、聚焦点有差异
SeaJS努力成为浏览器端的模块加载器,RequireJS牵三挂四,兼顾Rhino 和 node,因此RequireJS比SeaJS的文件大。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

