巨杉案例:基于日志的大数据运维管理平台
在电信行业,运营商构建了非常多的应用系统为广大消费者提供各种特色服务,有一些系统的功能由于在业务操作的上下文中,涉及到多个业务系统的子功能,需要多个系统共同提供服务才能正常工作,导致任何系统出现异常都会影响到其余的系统,对企业形象和社会造成非常恶劣的影响。
而各业务系统的应用日志是了解业务系统是否正常运行的最直接可靠的窗口,通过统一收集、分类应用日志,并实现日志分析,可实现如下价值:
- 加强网络运营效率:收集各类设备和应用的关联行为,分析网络通信服务质量,实现系统运维监控,提升网络工作效率,改善客户使用体验。
- 合理配置渠道资源:针对不同类型与喜好特点的客户群体,按渠道投放差异化的产品和服务,提高渠道利用效率。
- 客户画像与精确营销:记录客户在各种渠道的行为和接触信息,预测客户行为动机,从而准确地推送个性化的服务和产品。
因此,电信运营商对于应用日志的监控力度非常大,一旦出现异常信号,需要及时通知操作人员进行问题定位与问题解决。但这种方式只能进行问题的事后补救处理,不能预先发现应用系统的隐藏问题。而且由于日志数据是典型的文本类半结构化大数据,传统的关系型数据库无法满足海量日志数据的存储与实时查询分析需求。
1.用户业务需求
- 业务问题溯源查询,响应时间3秒内
- 基于日志的错误信息分析
- 日志关联匹配分析
- 基于日志的系统问题探索和预警
- 多维度分析结果的聚集与实时展现
2.业务与技术挑战
原解决方案
如下图所示,用户在项目初期基于Hadoop HDFS及Greenplum构建日志监控系统,并将原始日志文件保存在NAS文件系统中。
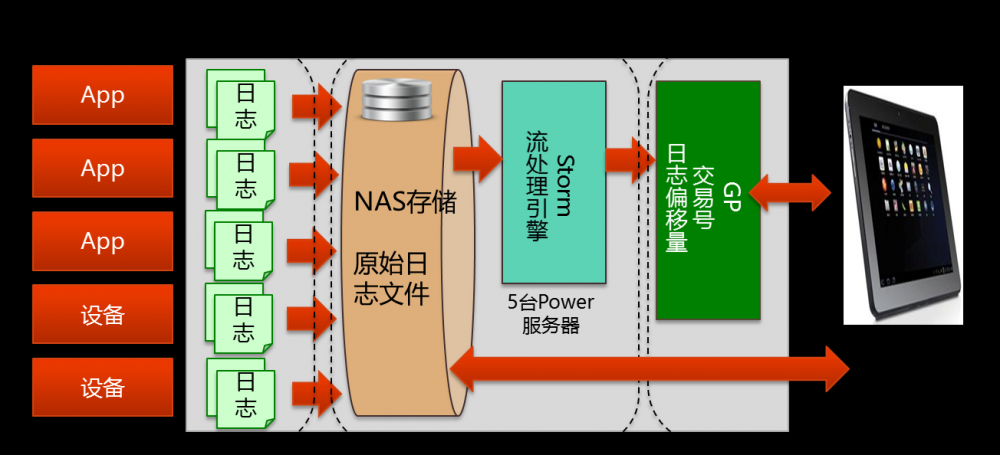
然后通过流处理引擎将日志中的每个交易号对应的日志报文对应文件的偏移记录(位置)转换成一个格式化记录,并将生成的数据保存在 GP(Greenplum) 中。

用户如果希望查询某个交易号的明细日志,需要先到GP 库中查找这个交易号对应在哪个文件中,并且知道了它在文件的偏移情况,打开文件,跳转到对应的偏移上,才能看在完整的明细日志。
原方案存在问题与不足如下:
- 当应用日志数据量越来越大时,流处理引擎、GP 和NAS 的管理会越加复杂、困难。
- 将日志存放在NAS 的方法,Hadoop分布式计算框架很难与其整合,无法使用简单工具(如Hive等)进行日志分析。
3.解决方案
用户基于SequoiaDB数据库+Hadoop框架重构了智能日志分析系统,在已有日志监控系统基础上增加智能日志分析功能,可自动根据应用日志分析错误隐患,提高应用的纠错能力。
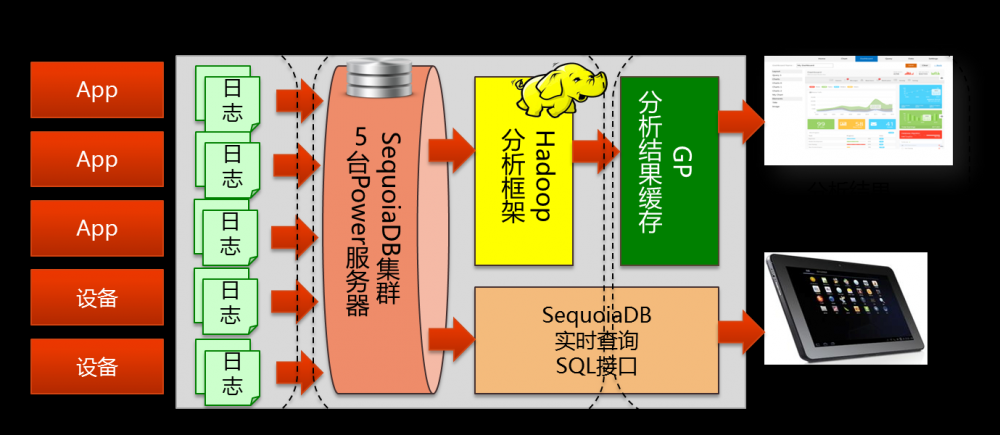
如上图所示,数据采集端将新增数据实时加载到SequoiaDB数据库集群中,系统定时触发程序每隔5分钟启动Hadoop MapReduce分析程序,分析结果通过GP进行多维分析查询展现,当系统出现操作异常或者是用户违规操作时,立刻通过进行系统操作告警。业务人员用户可在Web操作界面通过SQL接口实时查询应用日志,实现对错误信息的实时定位。
在此系统架构中,SequoiaDB巨杉数据库发挥三大作用:
- 海量应用日志的数据存储:大量的原始日志保存到SequoiaDB数据库中,并按时间、交易号两个字段均匀的分布到五个节点服务器的各自数据磁盘中。由于SequoiaDB数据库原生就支持数据备份功能,保证数据安全的同时,解决了数据灾备问题。
- 向Hadoop提供分析的原始数据:SequoiaDB数据库能与Hadoop深度整合, MapReduce程序能无缝对接SequoiaDB数据源进行高效的迭代计算,也可以通过Hive SQL对分布的日志数据进行检索,完成并行分布式计算。
- 实时SQL查询:用户在查询某个交易号的明细日志,只需以SQL形式提交相应的交易号,SequoiaDB数据库即按索引机制进行索引匹配,实时反馈出完整的日志报文,实现基于交易号的实时查询,将处理流程大大简化。
4.项目成果
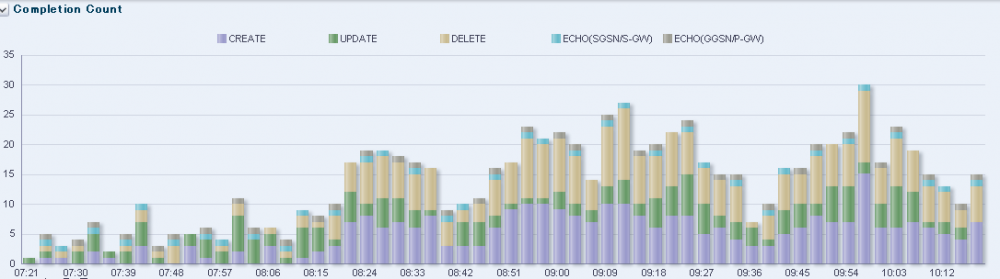
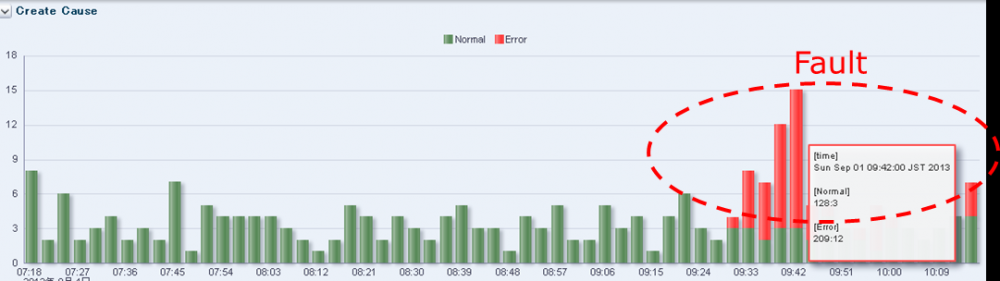
智能运维监控
系统很好地满足了对应用日志数据的实时统计及异常检测的功能需求。
运维简单方便
相比起单纯的HDFS文件系统,SequoiaDB数据库在实现了对应用日志数据的集中统一存储的同时,满足了全量日志实时SQL查询及向分析程序输送数据的需求。
相比于引入HBase,Impala, Storm, Pig等框架的方法,基于SequoiaDB数据库的方案运维简单,开发方便,管理快捷,功能完善。
2016年9月22日-23日, SDCC2016大数据技术&架构实战峰会 将在杭州举行,两场峰会大牛讲师来自阿里、京东、苏宁、唯品会、美团点评、游族、饿了么、有赞、Echo等知名互联网公司,共同探讨海量数据下的应用监控系统建设、异常检测的算法和实现、大数据基础架构实践、敏捷型数据平台的构建及应用、音频分析的机器学习算法应用,以及高可用/高并发/高性能系统架构设计、电商架构、分布式架构等话题与技术。
9月5日-18日是八折优惠票价阶段,5人以上团购或者购买两场峰会通票更有特惠,限时折扣,预购从速(票务详情链接)。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

