图计算系统进展和展望
文 / 成杰峰,刘勤,李震国
本文为 《程序员》 原创文章,未经允许不得转载,更多精彩文章请 订阅2016年《程序员》
挖掘大规模图数据能增强现有商业业务,甚至产生新的商业模式。然而,这些图数据的规模让图数据挖掘本身成为难题,这些突出的挑战都指向了发展具有高可扩展能力的大规模图计算处理的有效工具。本文先展开叙述图计算技术的几个核心层面,进而介绍华为诺亚方舟实验室的VENUS图计算系统,最后对图计算发展的趋势作简要展望。
背景大量不同个体之间彼此交互产生的数据以图的形式表现,在通信、互联网、电子商务、社交网络和物联网等领域中积累了大量的图数据。其规模巨大并且不断增长。简言之,图由节点(即个体)与边(即个体之间的联系)构成;而图数据是不同领域的数据中有这种图结构的相关部分。由Web网页和页面间的超链接构成的图或者社会网络中的不同用户和用户之间的关系链(见图1)都构成了大规模图数据。据CNNIC统计,仅在中国的Web页面所形成的图规模在2010年就达到600亿节点,并以78.6%的年增长率不断增大。Facebook的社交网络在2011年已超过8亿节点;而腾讯QQ社交网络目前在10亿个节点的规模。在电信工业中,广州市仅一个月内由电话呼叫方和被呼叫方组成的图就操过4.5千万个节点、1.5亿条边。而著名的ClueWeb数据包含全量的Web站点和网页,2012年公布的数据集已经达到1亿个节点、425亿条边,仅是存储边的列表的磁盘文件就超过400GB。
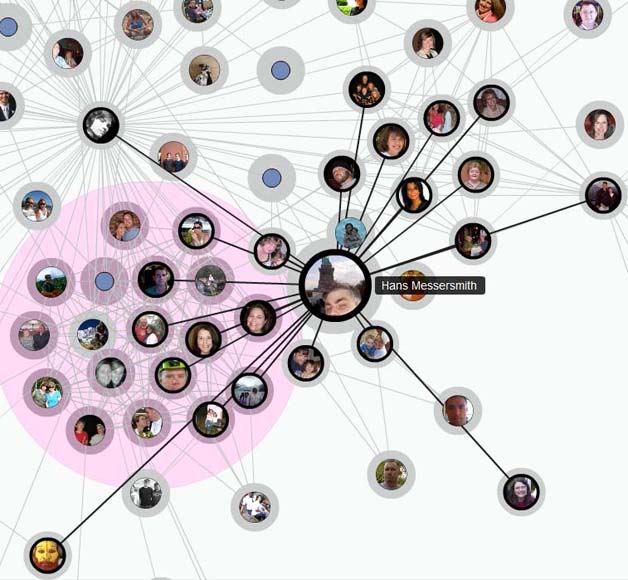
图1 社会网络中的不同用户和用户之间的关系链构成了大规模图数据
非常有价值的是:挖掘这些大规模图数据能增强现有商业业务,甚至产生新的商业模式。然而,这些图数据的规模让图数据挖掘本身成为难题。比如ClueWeb图的全量SimRank计算需要几千年。这些突出的挑战都指向了发展具有高可扩展能力的大规模图计算处理的有效工具。
虽然业界经过多年的实践发展出MapReduce和Spark等主流大数据平台,但图挖掘任务有其本身的独特性:由于数据之间依赖性强,使分布式处理模式需要频繁地在各个机器之间进行数据交换;且图挖掘算法流程本身由多次迭代处理构成。因此,主流大数据平台公认被不适合处理图挖掘任务[1],而基于图计算的大数据分析平台成为了图挖掘和相关机器学习算法的新方法。代表之一是Google提出的Pregel系统[2],Google称20%的数据处理是使用Pregel实现的,图计算是成功的数据挖掘处理框架。然而,Google一直没有将Pregel的具体实现开源,外界争相对Pregel进行模仿实现。2012年,卡内基梅隆大学教授Carlos Guestrin提出了分布式GraphLab框架[3],引起业界的广泛关注。
据Guestrin介绍,GraphLab在推荐系统中有很多应用,其他主要应用领域还包括互联网欺诈侦测和入侵探测等。GraphLab项目剥离出一个独立运作的商业公司GraphLab Inc,由Carlos Guestrin负责。2013年5月,该公司从Madrona Venture Group和NEA募集了675万美元资金并于2015年1月再得到1,850万美元的B轮融资。在2016年8月,这家图计算公司被苹果以2亿美元左右的价格收购。例证了图计算在大数据趋势下的重要性和在人工智能产业发展中的必要性。
本文以下先展开叙述图计算技术的几个核心层面,进而介绍华为诺亚方舟实验室的VENUS图计算系统,最后对图计算发展的趋势作简要展望。
图计算核心技术
随着大规模图数据分析的需要,近几年涌现出了很多图计算系统,其中值得注意的标志性工作有:Pregel[2]、GraphLab[3]和GraphChi[4]等。类似于现有Hadoop/Spark大数据框架通过MapReduce这样的简单接口函数去实现各种分布式集群处理任务,图计算的基本思想是使用“think like a vertex”去抽象表达图挖掘及相关机器学习算法,使得各种数据挖掘任务可以变为编写顶点程序(vertex program)并通过现有的图计算系统执行得以完成。
顶点程序计算更新图中顶点和邻接边的计算状态。而这些计算状态进一步被其他顶点程序执行时调用。图计算系统按BSP并行机制(Pregel)或异步并行机制(GraphLab)在计算集群上调度所有的顶点程序,并加入一定的容错机制,比如快照恢复。这样,图计算任务自动具有容错的并行处理,从而极大地提升数据挖掘算法的可扩展性。
具体些说,图计算系统预定义好的一个虚函数update(),通过对其重载以实现表达用户逻辑的顶点程序。于是,图计算系统将该函数对每一个顶点进行调用。update()方法可以访问使用的是当前顶点及其边的信息,以及入边的顶点及其边的信息;同时可以修改一个顶点以及与它相连的边上的权值。在图计算完成一个算法的多次迭代中,每次迭代就是系统完成一遍在图的每一个顶点上执行更新函数。由于Pregel采用同步执行模式等原因,速度较慢,目前GraphLab和GraphChi已经分别成为了分布式图计算系统和基于磁盘单机图计算系统的业界标杆。
GraphLab是基于内存的分布式图计算系统,一个图被分割成多个子图,每个子图保存在一台计算机的内存中。图的分割采用选取顶点切开图的方式。分开之后,选出来切图的顶点进一步并入所有和这些顶点有邻接关系的不同子图中。这样,每个切图的点就同时有多份保存在多个主机上。所以在每次图计算迭代中,每台主机都执行该主机上的子图内的顶点上的更新函数,每次更新过的顶点的计算结果值都需要同步到其他主机该顶点的备份上去。图数据包括图的顶点和边,以及顶点和边上的值。所以,虽然GraphLab不需要用网络传输图的结构信息,但在计算过程中,GraphLab仍然需要大量的网络开销传输同步顶点的值。
从卡内基梅隆大学的GraphLab项目分派出一个发展很快的分支:GraphChi。它将数据挖掘算法自动转化为基于外存算法和核外处理(out-of-core processing),图不需要被分割成子图就能处理执行vertex-centric计算模型。这样,即使一台PC也能处理大数据分析的任务。在基于磁盘的单机图计算系统GraphChi中,一个图被分割成多个数据片,每个数据片保证可以被放在内存中。每个数据片包含一个完整的子图,包括一个连续的顶点区间和这些顶点的入边与出边。基于磁盘的单机图计算系统的图计算也是由多次迭代组成,每次迭代,系统在每个顶点上执行一次用户定义的更新函数。在每次迭代中,系统依次处理每个数据分片,并在每个数据分片内并行执行更新函数,并行仅是多个线程间的单机并行。
GraphChi解决的一个主要难点是如何使用高效的I/O代价完成数据挖掘算法。由于基于图计算模型的数据挖掘算法的数据是作为图上的信息全部存储到磁盘上,一个迭代通常需要扫描整个图模型的数据存储。一次扫描一共需要读取|E|个数据单元,因为数据是根据图的边来存储,这就是说,一个迭代可能会最多引起|E|个读和写的操作,即2×|E|次磁盘I/O。
为了解决这个问题,GraphChi的核心思想是经过仔细设计边在磁盘上的排列分组以配合图计算模型,使得任何基于这个图计算模型的数据挖掘算法完成一个迭代只需在P2次磁盘读取操作和P2次磁盘写入操作。这种机制被命名为滑动窗口机制(Parallel Sliding Window,PSW),是将图的顶点按顶点ID的区间(interval)分成P份。区间不是均匀的,但数据分片(shard)的大小统一,所以区间大小由其对应的数据分片(shard)大小决定。数据分片就是区间内每一顶点与其相连的所有入边构成的所有子图的集合。这就是说,数据分片包含了图中所有指向区间内顶点的边,这些边的数目在不同数据分片中基本相同。而数据分片的这些边进一步按源顶点的ID升序排列。数据分片的大小选取以主存能容纳最大的数据分片所确定。当计算机主存无法容纳全部图数据进行内存计算的时候,GraphChi这种图数据的磁盘存储设计使得图计算能具有I/O高效的性质。
在一个图计算算法的处理过程中,GraphChi一次读入一个数据分片到主存,从而相应区间内的所有顶点的入边就都可用了。而这些顶点的出边必然存于剩下的P-1个数据分片中。并且由于各个数据分片的边都按源顶点的ID升序排列,这些顶点的出边必然在每一个数据分片内的一个连续区域中。所以,一个顶点区间内的所有同时具有入边和出边的子图都可以由一次数据分片全扫描和P-1次数据分片部分扫描完成。对内存中得到的这些子图,GraphChi把基于不同子图的计算任务并发到多个线程中处理。当所有的计算完成后,所有边上的数据更新都可由当前的数据分片全部写回和剩下的P-1个部分数据分片的写回操作完成。这种方式,GraphChi按照顶点ID的升序依次处理P个数据分片就能完成一次所有的图中的顶点程序的计算,这通常是机器学习算法的一个迭代。所以,任何一个迭代一定能在P2次磁盘读取操作和P2次磁盘写入操作完成。以上过程的顶点程序的计算是严格按照顶点ID由小到大来执行的,因为首先整个顶点区间按照顶点ID升序枚举。而在一个顶点区间内,虽然不同子图的计算任务并发到多个线程中处理,但GraphChi会提前检查是否存在这样的顶点它们的入边同时也是该区间内某顶点的出边,这些边会形成冲突。GraphChi让具有冲突出边的点先执行,从而整个处理都能保证具有确定性(deterministic)的可序列化(serializable)操作。进而保证了程序并行处理的正确性。
分布式计算系统(如GraphX[5]、Giraph[6], Pregel、和GraphLab)可以处理10亿顶点——规模的图数据,然而这些方案也同时需要大规模计算机集群,存在对相当部分用户来说过高的代价。与此同时,基于磁盘的单机图计算系统(如GraphChi、X-Stream[11])提供廉价且有竞争力的处理能力。例如在一个有15亿条边的Twitter社交网络上运行PageRank算法,Spark需要50台计算机(100个CPU)和8.1分钟,而GraphChi只需要1台MacMini和13分钟[4]。华为诺亚自主研发的图计算系统VENUS只需要1台普通PC和5分钟。
诺亚图计算系统VENUS从2013年起,华为诺亚方舟实验室启动了大规模图数据挖掘的研究项目,负责研发图计算系统、图挖掘算法和商用。学术上,该项目已产出了若干研究成果 [7, 8, 9, 10],取得了一定的技术突破;商业上,在华为的业务中获得了重要应用。其中,所开发的图计算系统VENUS成为业界最快的单机图计算平台之一,能高效支撑各种大规模图数据挖掘应用。目前,VENUS系统在华为手机应用市场中分析10亿量级的用户日志数据,支撑了重要的广告推送目标客户选择和手机应用推荐业务。
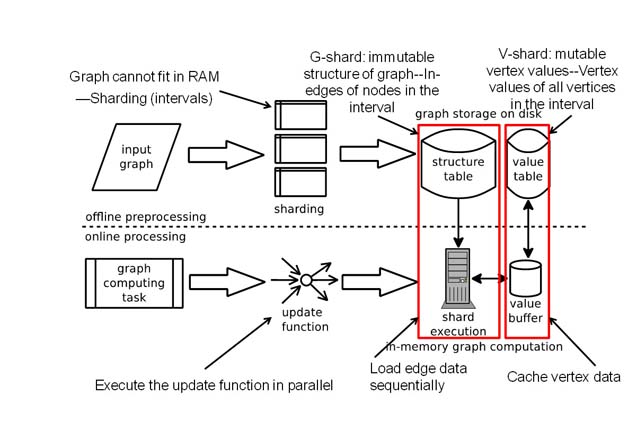
图2 VENUS架构
当前图计算面临几大主要挑战是单机系统具有很高的磁盘IO并且无法有效利用较大的内存;而分布式系统需要处理很难得图分割问题,并且计算过程会产生很高的网络开销以至于成为系统整体的扩展性能瓶颈,GraphLab甚至会出现在增加节点时处理时间反而变长的情形。为了应对这些挑战,VENUS图计算系统从最初设计开始考虑了一种新的扩展模式:纵向扩展+横向扩展。特别考虑在先不往外扩展(scale out)数据的情况下,先充分发挥单个计算节点往上(scale up)图计算系统的能力,再去大规模计算集群上往外扩展(scale out)多节点上的同质的计算。以处理计算量大,复杂度高的图算法。
基于磁盘的流水化计算模型VENUS提出的以顶点为中心流水化图计算模型将基于磁盘的图IO显著降低,极大改善了系统IO瓶颈突出的情况。相对常见的大数据平台如Hadoop和Spark,VENUS的设计理念是往外扩展(scale out)数据,在大规模集群上并发读取大数据,去应对大量数据所需要的大量IO。VENUS有独特的基于外存算法的技术途径,称为基于分级存储的顶点为中心流水化图计算模型,已经在单机上突破图计算系统的可扩展能力,解决了如何有效利用磁盘带宽,减少图计算中访问海量图数据IO的问题。
在基于磁盘的单机图计算系统GraphChi中,一个图被分割成多个数据片,每个数据片保证可以被放在内存中。每个数据片包含一个完整的子图,包括一个连续的顶点区间和这些顶点的入边与出边。图计算由多次迭代组成,每次迭代,系统在每个顶点上执行一次用户定义的更新函数。在每次迭代中,系统依次处理每个数据分片,并在每个数据分片内并行的执行更新函数。在处理一个数据片时,分为3个步骤:第一步是载入(Load),即从磁盘上读入该数据分片;第二步是更新(Update),即数据分片相应的子图上执行更新函数;最后一步是写回(Write),将更新后的子图写回到硬盘上。在GraphChi系统中,在处理每个数据分片前,整个数据片必须作为一个整体同时被载入到内存中,导致图计算与IO无法并行完成,降低了处理速度。此外,在写回阶段,该系统需要传播当前子图中边的更新到其它数据分片,这会产生大量随机IO。
另一个基于磁盘的图计算系统X-Stream提出了以边为中心的图计算模型。在这个模型中,用户需要定义2个更新函数(scatter与gather),而且这2个函数在边而非顶点上执行。每次迭代被分为3个步骤:第一步是发布(scatter):系统顺序扫描全部边,并应用scatter函数为每条边生成一个更新消息;第二步是洗牌(shuffle):系统顺序扫描全部的更新消息,并按照更新消息的目标顶点将消息放入相应数据片的消息缓冲区中;最后一步是收集(gather):系统顺序扫描每个数据片的更新消息,并应用gather函数更新目标顶点。由于scatter和gather函数的执行只依赖于当前扫描到的边或更新消息,并不依赖于相关子图的信息,X-Stream可以使用顺序IO扫描边和更新消息达到流水化处理模式。系统可以将读入操作与计算并行。然而X-Stream需要将中间结果(即更新消息)写回硬盘上,这加倍了顺序IO,产生了额外的计算和数据载入开销。此外,由于以边为中心图计算模型不同于此前的面向顶点模型,现有大量通用的以顶点为中心的图计算算法将不可借用。而且用户需要使用新的图计算抽象方式在X-Stream上实现图算法,其难度会有所增加。并且,一些重要的图算法(如社区发现算法)难以在X-Stream上实现。
VENUS系统同时使用了新的数据分片方法以及新的图计算的外存模型。在该系统中,每一个数据分片被分为v-shard和g-shard两个部分:其中v-shard为一个分片中的顶点数据,数据量较小且需要经常修改;g-shard为分片中图的结构即边数据,数据量较大且不会被修改。VENUS进而在新的数据分片上创造了新的图计算的外存模型:在图计算执行中时,系统对全部g-shard使用顺序磁盘IO去扫描不断从磁盘扫描g-shard磁盘块读入内存,并一直有该s-shard执行所需的某一个v-shard全部存放于内存。如上图所示,处理 g-shard中所有对应的更新函数时,所有相关的所需的顶点数据都已经在内存中对应的v-shard中供直接访问存取。注意到g-shard按磁盘块读入就立刻计算并从内存丢弃,以保证更多的v-shard数据可以进到内存。这样,VENUS能够使用较快的顺序访问IO带宽读取整个图中边的数据(g-shard),而且系统在读入数据的同时也可以及时的进行计算,减少了系统整体的运行时间。
每次从磁盘扫描g-shard的一个磁盘块时,系统首先得到多个不同顶点v的邻接子图Gv,这包括了从g-shard的该磁盘块中取出所有不同v的邻接边,以及从v-shard读取所有邻接顶点的值。然后以多个不同线程,每个线程处理一个邻接子图,去运行基于不同子图部分的分析计算。计算得到一系列新的顶点的值并将其更新到内存的v-shard中。不断按此继续直到处理下一批g-shard和v-shard,当所有的g-shard和v-shard处理完毕,该次迭代结束。总体来说,分别使用基于磁盘的v-shard和g-shard分开存储得到的图计算模型的边和所有顶点的值,避免了现有图计算所有顶点的值按边存储时有多个副本而需要同步更新带来的额外磁盘访问开销,大大降低了现有的基于磁盘的图计算的读写总量。如图3所示,比起现有磁盘图计算系统GraphChi和Xstream[11],VENUS显著减少了图计算中磁盘数据读写的总量:在处理4千1百万顶点和14亿条边的Twitter图时(8GB内存),VENUS比GraphChi和Xstream的写入磁盘数据总量分别小40和50倍。
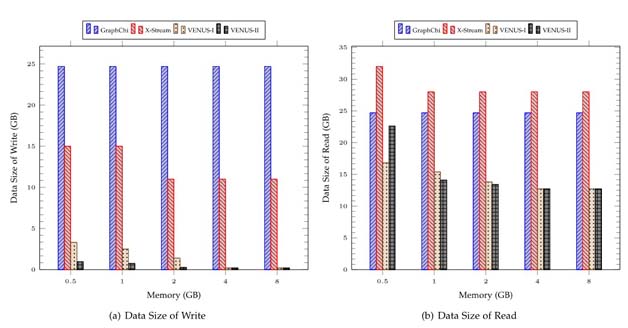
图3 VENUS相对现有系统读写磁盘的开销较小
对该学术思路,数据管理顶级会议ICDE2015评委这样评价:“The proposed techniques streamline vertex-centric processing in a manner that reduces vastly the amount of data written to disk while maintaining a mostly sequential I/O pattern. The paper represents a substantial piece of research on a very practical and timely topic.”。在单机系统中,VENUS性能优于GraphChi和X-Stream,处理时间普遍快3到10倍;对比分布式系统,VENUS单机可以达到与Spark集群(50台,100CPU)接近的效果。针对华为内部某一商业场景要求,VENUS唯一成功处理了2千亿连接的大图(一次迭代需时 81772.1秒)。
另外,在华为手机应用市场中分析任务,我们还发现单机图计算在生产系统部署时的一个额外的优势:由于要分析每日更新的大量日志数据,计算通常需要在夜间几个小时内完成,计算环境中通常有夜间预先安排大量的任务,导致计算资源紧缺。由于现有图计算系统在处理大图时把全图载入内存,需要比较多的服务器,为运行图计算任务设置了较高的条件,难于实施。比如,处理ClueWeb时,每台服务器配置380G内存,Spark最少需要10台,GraphLab最少需要更多的服务器才能处理。而VENUS在这种情况下可以较容易部署使用,发挥了单机处理的优势。

图4 VENUS vs Spark: PageRank on Twitter (41M 顶点,1.4B 边)
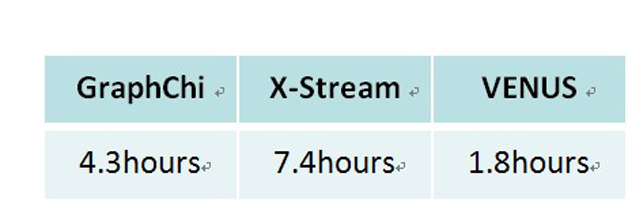
图5 VENUS vs GraphChi: PageRank on clue-web (1B 顶点,43B 边)
趋势展望虽然基于磁盘的单机图计算具有以上诸多优点,但海量的图数据在单台计算机上的读写仍然是一个很大的时间瓶颈,比如使用传统磁盘读取ClueWeb一次的时间就已经要将近2个小时。未来考虑基于分布式文件系统HDFS的磁盘计算具有很大的潜力,但如何设计相关的分布式图计算模型任然比较挑战,相关研究逐步在开展中[12]。此外,现有应用表明一套图系统能同时具有离线的图计算和在线的图数据库查询是具有很大价值的,但这给如何设计图数据库存储模式带来了较大挑战,[13]是一个初步尝试。
在分布式图计算系统中,由于图已经按集群中计算节点的数目被分成同等份数,图计算过程中主机需要不断彼此通信告诉对方自己内存中的计算状态才能使得整体计算向前进行。这样,分图的好坏直接影响到计算过程中产生的网络消息,大量的网络消息会极大的降低图计算的整体性能。据报道,现有内存计算的分布式图计算系统要花50%以上的时间去收发消息。然而,最小代价的均匀多分图问题是很难的NP问题,在多项式时间内是不能求出高效解的。所以,如何扩展分布式图计算系统以减少对大量的内存和网络的使用是分布式图计算领域未来要解决的趋势性问题。
在分布式计算环境下,由于每台主机都有相对充足的磁盘空间可以在本地磁盘完全容纳图数据,VENUS可通过复制在单节点上图计算系统的能力进行分布式扩展。其优势是:计算过程中,系统只需快速的少量顺序磁盘IO读取本次存储的图数据进行计算,不需要不同的主机之间对图数据进行网络通信。并且,这样的分布式图计算可同时在多节点上对同一个图执行同质计算,因为在同一节点上的同一批计算共享了相同的图数据IO调度开销,可以充分的利用多核CPU、FGPA等硬件大规模并行执行多个顶点程序,满足实际应用中对时间效率的需求。
我们先不往外扩展(scale out)数据,先充分发挥单个计算节点往上(scale up)图计算系统的能力,再去大规模计算集群上往外扩展(scale out)多节点上的同质的计算,以处理计算量大,复杂度高的图算法。例如我们在处理大规模图的SimRank算法时,采用的是比较实际的方案,即基于随机游走(random walk)的蒙特.卡罗(Monte-Carlo)。该方案中一项核心计算任务是:对图中的N个节点,我们需要独立地从每个节点出发搜索一条以该节点为源点的随机游走路径。从现有图计算系统直接实现该SimRank算法的角度来看,基于随机游走(random walk)的蒙特.卡罗(Monte-Carlo)算法要求对同一个图进行N次图计算。每次随机游走都从图中每个不同的起始节点开始,每一步随机选取当前节点的一个相邻顶点前进。采用现有的图计算系统实现这个处理时,GraphLab和GraphChi都能直接实现从一个给定的起始节点出发的一次随机游走。其中,随机游走往下一个相邻顶点前进的每一步都需要现有图计算的一次迭代,随即游走路径需要被采样多长,系统就处理多少步迭代完成该次采样。所以,现有标杆分布式图计算系统GraphLab在实现这个算法的最直接的方式是,N次采样就运行N次图计算,每次图计算对应一次采样计算。其计算时间就是一次分布式采样计算时间的N倍。
相比之下,VENUS可通过复制在单节点上图计算到多个不同的主机上同时运行这N次采样。此时,计算集群中每台主机都可见全图,因为我们有相对充足的磁盘空间可以在本地磁盘完全容纳图数据。这种方式同时避免分图才能处理这个棘手的问题。而不同源的随机游走彼此无依赖,可分别在每台主机各自同时计算,不需要不同的主机之间对图数据进行网络通信。这相当于我们往外扩展(scale out)多节点上的同质的随机游走采样计算。由这多个不同的主机上同时运行这N次采样,这样整体时间就是一次单机采样计算时间的N/M倍,这里M为主机的个数。由此可见,该方式具有更佳的扩展性能。
作者简介- 成杰峰,华为诺亚方舟实验室任研究员。工作集中在大规模巨型图的在线搜索、离线分析挖掘算法和图挖掘可扩展系统,发表了JVLDB、TKDE、KDD、VLDB、ICDE等学术论文30余篇。
- 刘勤,华为诺亚方舟实验室研究员。主要研究方向为系统软件、并行与分布式系统。在包括VLDB、ICDE、DSN、CIKM和TKDE等国际著名会议期刊发表多篇学术论文。
- 李震国,华为诺亚方舟实验室图挖掘技术负责人,美国哥伦比亚大学电子工程系博士后。研究领域包括人工智能和机器学习,在NIPS、ICML、CVPR、ICCV、VLDB等相关会议发表多篇学术论文。
参考
[1] What MapReduce can’t do. [url="http://www.analyticsbridge.com/profiles/blogs/what-mapreduce-can-t-do "]http://www.analyticsbridge.com/profiles/blogs/what-mapreduce-can-t-do [/url]
[2] G. Malewicz, M. H. Austern, A.J.C Bik, et al. Pregel: a system for large-scale graph processing. In SIGMOD, 2010
[3] Yucheng Low, Joseph Gonzalez, Aapo Kyrola and et. al. Distributed GraphLab: A Framework for Machine Learning and Data Mining in the Cloud, In VLDB, 2012
[4] Aapo Kyrola, Guy Blelloch and Carlos Guestrin. GraphChi: Large-Scale Graph Computation on Just a PC. In OSDI, 2012.
[5] Joseph Gonzalez, Reynold Xin, Ankur Dave, Daniel Crankshaw, Michael Franklin and Ion Stoica. GraphX: Graph Processing in a Distributed Dataflow Framework. In OSDI, 2014.
[6] Apach Giraph. http://incubator.apache.org/giraph/
[7] Jiefeng Cheng, Qin Liu, Zhenguo Li, Wei Fan, John C.S. Lui and Cheng He. VENUS: Vertex-Centric Streamlined Graph Computation on a Single PC. In ICDE, 2015.
[8] Zhenguo Li, Yixiang Fang, Qin Liu, Jiefeng Cheng, Reynold Cheng and John C.S. Lui. Walking in the Cloud: Parallel SimRank at Scale. In VLDB 2016.
[9] Qin Liu, Zhenguo Li, John C.S. Lui, Jiefeng Cheng. PowerWalk: Scalable Personalized PageRank via Random Walks with Vertex-Centric Decomposition. In CIKM 2016.
[10] Qin Liu, Jiefeng Cheng, Zhenguo Li, John C.S. Lui. VENUS: A System for Streamlined Graph Computation on a Single PC. IEEE Transactions on Knowledge and Data Engineering, 2016.
[11] A. Roy, I. Mihailovic, and W. Zwaenepoel. Xstream: Edge-centric Graph Processing using Streaming Partitions, in SOSP, 2013
[12] A. Roy, L. Bindschaedler, I. Mihailovic, and W. Zwaenepoel. Chaos: Scale-out Graph Processing from Secondary Storage, in SOSP, 2015
[13] Aapo Kyrola. GraphChiDB: Simple Design for a Scalable Graph Database on Just a PC. Tech. Report, 2014.
订阅2016年程序员(含iOS、Android及印刷版)请访问 [url="http://dingyue.programmer.com.cn "http://dingyue.programmer.com.cn [/url]
正文到此结束
- 本文标签: 文件系统 rmi tab 线程 配置 电子商务 软件 src 2015 IO Hadoop 广告 map Google DOM dist 文章 服务器 美国 apr 管理 Android 目标客户 数据挖掘 Action 站点 数据库 HDFS 大数据 程序员 同步 ACE Twitter 备份 集群 Facebook 智能 开源 http 物联网 web 突破 cat NSA 空间 苹果 主机 社交网络 apache ip 资金 数据 时间 开发 统计 scala id update db 互联网 UI 需求 快的 core IOS
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

