MySQL列转行巧录数据
开发同学让我帮忙看看一个数据怎么录合适。
原始的数据如下,要录入到数据库里。
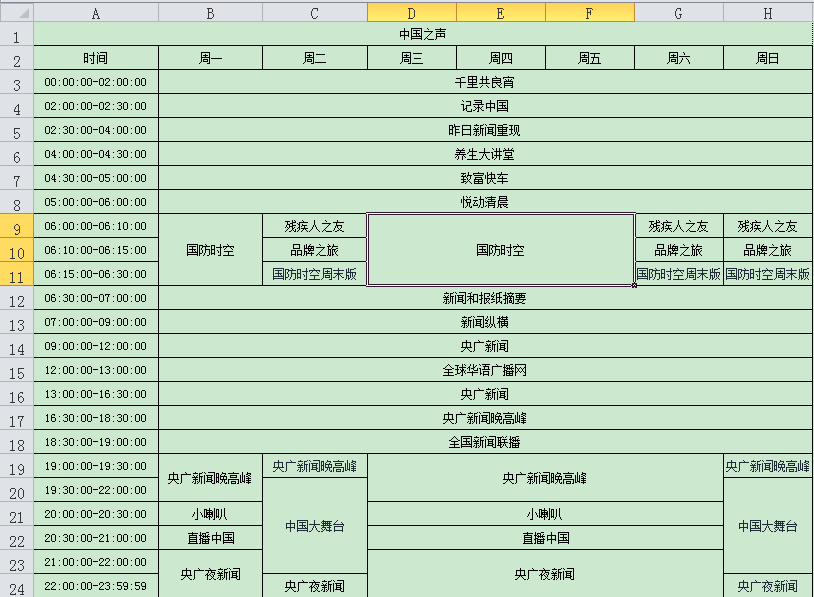
先取消Excel的单元格合并.
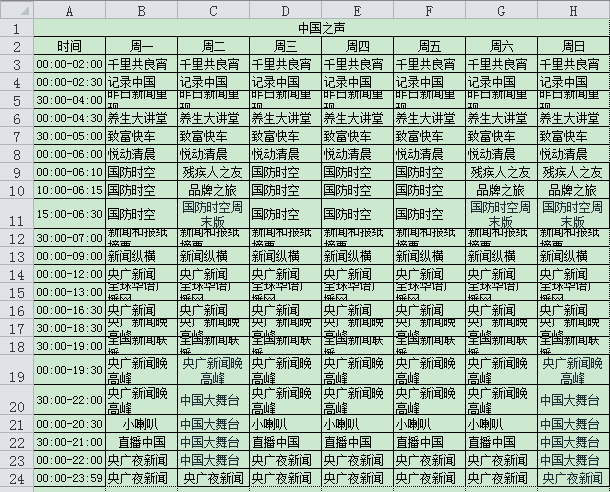
删除第一行和第二行的数据,这些都是标题.
然后导出CSV文件,
使用文本文件编辑器打开CSV,替换 - 为 ,

然后 德塔贝斯 建个表。
再将CSV数据导入.
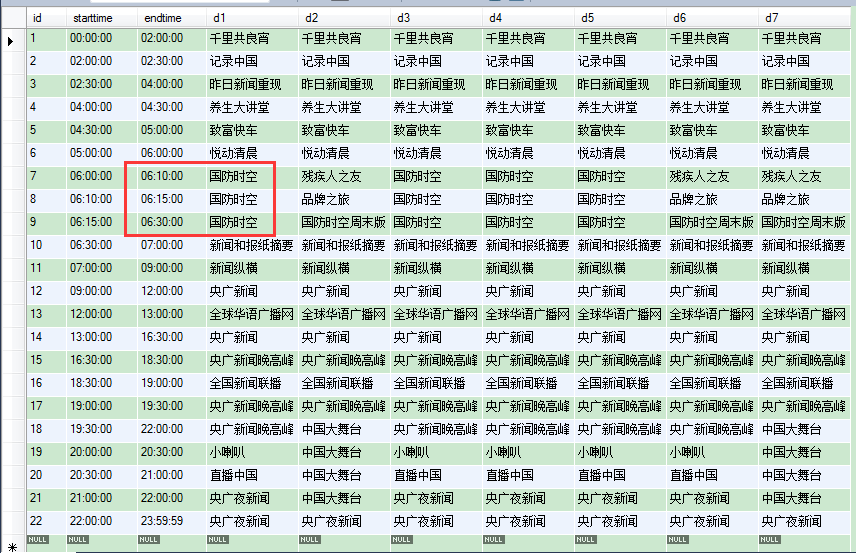
类似于红框的部分,都是连续的节目,需要合并时间段。
下表是模拟开发同事最终录入数据的表。
录入的SQL
查看结果
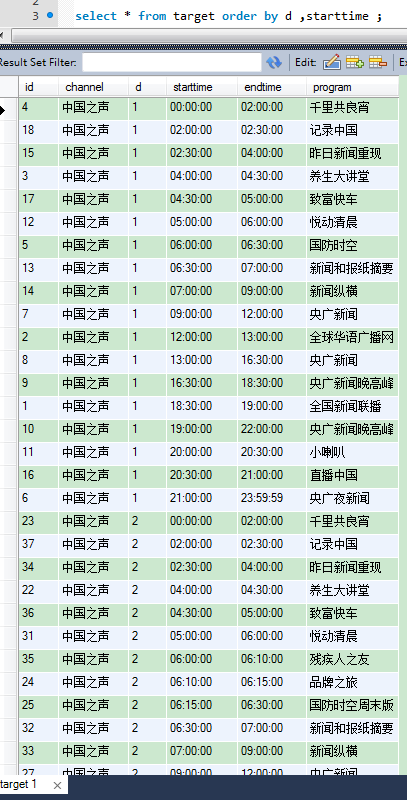
这个方法看着步骤比较多,其实还是很省事儿的.
主要的工作就是把Excel导入数据库,导入之后的合并,使用同一个SQL改改就好。没啥工作量。
否则使用JAVA解析,还需要自己合并时间段.也不是一个轻松的事情.
该同学需要录入 这种Excel 大致20多个..我觉得我这个方法核心步骤可以复用,应该还是很有效率的。
原始的数据如下,要录入到数据库里。
先取消Excel的单元格合并.
删除第一行和第二行的数据,这些都是标题.
然后导出CSV文件,
使用文本文件编辑器打开CSV,替换 - 为 ,
然后 德塔贝斯 建个表。
再将CSV数据导入.
-
create table t(
-
id int primary key auto_increment,
-
starttime time,
-
endtime time,
-
d1 varchar(20),
-
d2 varchar(20),
-
d3 varchar(20),
-
d4 varchar(20),
-
d5 varchar(20),
-
d6 varchar(20),
-
d7 varchar(20)
- );
类似于红框的部分,都是连续的节目,需要合并时间段。
下表是模拟开发同事最终录入数据的表。
-
create table target(
-
id int primary key auto_increment,
-
channel varchar(32) comment '电台名称',
-
d int comment '1-7 表示星期一或者星期二...',
-
starttime time comment '节目开始时间',
-
endtime time comment '节目结束时间',
-
program varchar(32) comment '节目名称'
- );
录入的SQL
- insert into target(channel,d,program,starttime,endtime)
- select '中国之声',1,d1,min(starttime),max(endtime) from (
- SELECT @gid := @cgid, @cgid := t.d1, if(@gid = @cgid, @rank,@rank := @rank + 1) AS rank, t.* from
- (select id,starttime,endtime,d1 from t order by id) t ,(SELECT @gid := 1, @cgid := 1, @rank := 0) t2
- ) t4 group by d1,rank
- union all
- select '中国之声',2,d2,min(starttime),max(endtime) from (
- SELECT @gid := @cgid, @cgid := t.d2, if(@gid = @cgid, @rank,@rank := @rank + 1) AS rank, t.* from
- (select id,starttime,endtime,d2 from t order by id) t ,(SELECT @gid := 1, @cgid := 1, @rank := 0) t2
- ) t4 group by d2,rank
- union all
- select '中国之声',3,d3,min(starttime),max(endtime) from (
- SELECT @gid := @cgid, @cgid := t.d3, if(@gid = @cgid, @rank,@rank := @rank + 1) AS rank, t.* from
- (select id,starttime,endtime,d3 from t order by id) t ,(SELECT @gid := 1, @cgid := 1, @rank := 0) t2
- ) t4 group by d3,rank
- union all
- select '中国之声',4,d4,min(starttime),max(endtime) from (
- SELECT @gid := @cgid, @cgid := t.d4, if(@gid = @cgid, @rank,@rank := @rank + 1) AS rank, t.* from
- (select id,starttime,endtime,d4 from t order by id) t ,(SELECT @gid := 1, @cgid := 1, @rank := 0) t2
- ) t4 group by d4,rank
- union all
- select '中国之声',5,d5,min(starttime),max(endtime) from (
- SELECT @gid := @cgid, @cgid := t.d5, if(@gid = @cgid, @rank,@rank := @rank + 1) AS rank, t.* from
- (select id,starttime,endtime,d5 from t order by id) t ,(SELECT @gid := 1, @cgid := 1, @rank := 0) t2
- ) t4 group by d5,rank
- union all
- select '中国之声',6,d6,min(starttime),max(endtime) from (
- SELECT @gid := @cgid, @cgid := t.d6, if(@gid = @cgid, @rank,@rank := @rank + 1) AS rank, t.* from
- (select id,starttime,endtime,d6 from t order by id) t ,(SELECT @gid := 1, @cgid := 1, @rank := 0) t2
- ) t4 group by d6,rank
- union all
- select '中国之声',7,d7,min(starttime),max(endtime) from (
- SELECT @gid := @cgid, @cgid := t.d7, if(@gid = @cgid, @rank,@rank := @rank + 1) AS rank, t.* from
- (select id,starttime,endtime,d7 from t order by id) t ,(SELECT @gid := 1, @cgid := 1, @rank := 0) t2
-
) t4 group by d7,rank;
查看结果
这个方法看着步骤比较多,其实还是很省事儿的.
主要的工作就是把Excel导入数据库,导入之后的合并,使用同一个SQL改改就好。没啥工作量。
否则使用JAVA解析,还需要自己合并时间段.也不是一个轻松的事情.
该同学需要录入 这种Excel 大致20多个..我觉得我这个方法核心步骤可以复用,应该还是很有效率的。
正文到此结束
热门推荐










相关文章



Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

