Guava 是个风火轮之函数式编程
前言
函数式编程 是一种历久弥新的编程范式,比起 命令式编程 ,它更加关注程序的执行结果而不是执行过程。Guava 做了一些很棒的工作,搭建了在 Java 中模拟函数式编程的基础设施,让我们不用多费手脚就能享受部分函数式编程带来的便利。
Java 始终是一个面向对象(命令式)的语言,在我们使用函数式编程这种黑魔法之前,需要确认:同样的功能,使用函数式编程来实现,能否在 健壮性 和 可维护性 上,超过使用面向对象(命令式)编程的实现?
Function
Function 接口是我们第一个介绍的 Guava 函数式编程基础设施。
下面这段代码是去掉注释之后的 Function 接口。
@GwtCompatible public interface Function<F, T> { @Nullable T apply(@Nullable F input); @Override boolean equals(@Nullable Object object); } 实例化这个仿函数接口要求至少要实现 apply 方法。只有在需要判断两个函数是否等价的时候才覆盖实现 equals 方法。
下面我们通过一个简单的函数定义的例子看看 Function 接口的用法。
Function<Double, Double> sqrt = new Function<Double, Double>() { public Double apply(Double input) { return Math.sqrt(input); } }; sqrt.apply(4.0);//2.0 这里我们通过实例化一个匿名类的方式来完成了仿函数的定义、初始化和赋值。
注意到仿函数始终不是一个函数,而是一个对象,我们只能调用这个对象的方法来模拟函数调用。
这种 Function 接口的用法和函数式编程中将一个匿名函数赋值给变量的做法类似。当然,更加常见的函数定义方式是显式的声明一个函数然后实现它。
class SqrtFunction implements Function<Double, Double> { public Double apply(Double input) { return Math.sqrt(input); } } new SqrtFunction().apply(4.0);//2.0 从接口定义我们可以看出来,Function 接口模拟的函数只能接收一个参数,这不得不说是一个不小的限制。假如我们希望实现一个接收两甚至多个个参数的函数,我们就不得不做一些额外的工作来绕过这个限制。
下面的例子我们实现一个仅接收两个参数的函数。
Function<SimpleEntry<Double, Double>, Double> power = new Function<SimpleEntry<Double, Double>, Double>() { public Double apply(SimpleEntry<Double, Double> input) { return Math.pow(input.getKey(), input.getValue()); } }; power.apply(new SimpleEntry<Double, Double>(3.0, 2.0));//9.0 最后一个例子是实现一个接收可变参数的函数。由于变长参数实际上是 Java 编译器提供的语法糖,在编译期间会被解语法糖变成对象数组 Object[],而且变长参数无法作为泛型参数,这里直接使用对象数组作为参数。
Function<Double[], Double> sum = new Function<Double[], Double>() { public Double apply(Double[] input) { Double result = 0.0; for (Double element : input) { result += element; } return result; } }; sum.apply(new Double[]{3.0, 4.0, 5.1});//12.1 虽然从代码长度来看,使用 Function 接口来定义函数,需要写更多的代码。实际上,大部分的泛型声明和函数覆盖的代码都是由 IDE 自动生成的,手写的代码不过是 apply 的函数体而已。
Functions
Functions 是 Guava 中与 Function 接口配套使用的工具类,为处理实现了 Function 接口的仿函数提供方便。我们一起看看 Functions 是如何让 Function 接口如虎添翼的。
Functions 是一个方法工厂,提供各种返回 Function 实例的方法。如果我们把 Function 视为函数,那么 Functions 的方法就是高阶函数,因为它能够将函数作为它的返回值。
Functions#toStringFunction 返回这样一个函数 $f(x) = x.toString()$,以对象为入参,以对象的 toString 方法的返回值为返回值。
Functions#identity 返回这样一个函数 $f(x) = x$,以对象为入参,返回对象本身。
Functions#constant 返回一个常函数 $f(x) = a$,入参就是返回的函数的返回值。
Functions#compose 返回一个复合函数 $h(x) = g(f(x))$,以两个函数为入参,返回这两个函数复合之后的函数。例如我们有函数 $f:X /to Y$ 和函数 $g: Y /to Z$,复合之后得到复合函数 $g /circ f:X /to Z$。
想象一个数据处理程序,我们可以实现一个一个函数,让数据流从函数组成的阀门中间依次流过,最终得到想要的结果。我们可以使用复合函数方法将各个函数组合成流水线,当然也可以使用其他方法。
接下来是 3 组以 for 开头的方法,将其他数据结构或者接口的实例转变成 Function 实例。
Functions#forMap(java.util.Map
Functions#forMap(java.util.Map
Functions#forPredicate 以 Guava 的谓词实例为入参,返回一个 Function 实例。后续博文会介绍谓词接口 Predicate。
Functions#forSupplier 以 Guava 的 Supplier 实例为入参,返回一个 Function 实例。后续博文会介绍惰性求值接口 Supplier。
源码分析
下面这张图是 Functions 类的结构。
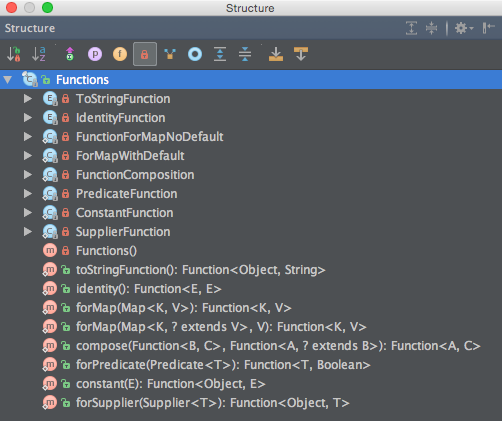
可以看出,Functions 的 8 个公有方法都有对应的内部类作为功能支撑。这 8 个方法的实现大同小异,我们这里选取两个具有代表性的方法进行源码分析。
首先是最简单的 Functions#identity。
public static <E> Function<E, E> identity() { return (Function<E, E>) IdentityFunction.INSTANCE; } // enum singleton pattern private enum IdentityFunction implements Function<Object, Object> { INSTANCE; @Override @Nullable public Object apply(@Nullable Object o) { return o; } @Override public String toString() { return "identity"; } } 注意到 Functions#identity 其实是个常函数,它返回的函数 $f(x) = x$ 可以表示为一个常量或者单例,于是实现中使用了枚举在完成函数定义的同时顺便实现了单例。
接下来是构造复合函数的高阶函数 Functions#compose。
/** * Returns the composition of two functions. For {@code f: A->B} and {@code g: B->C}, composition * is defined as the function h such that {@code h(a) == g(f(a))} for each {@code a}. * * @param g the second function to apply * @param f the first function to apply * @return the composition of {@code f} and {@code g} * @see <a href="//en.wikipedia.org/wiki/Function_composition">function composition</a> */ public static <A, B, C> Function<A, C> compose(Function<B, C> g, Function<A, ? extends B> f) { return new FunctionComposition<A, B, C>(g, f); } Javadoc 里面详细的描述了复合函数的复合方式,参数名的定义也符合数学上对复合函数的常见描述,让人一目了然。最后的 @see 还给出了 WikiPedia 的链接,颇有种旁征博引的感觉。
private static class FunctionComposition<A, B, C> implements Function<A, C>, Serializable { private final Function<B, C> g; private final Function<A, ? extends B> f; public FunctionComposition(Function<B, C> g, Function<A, ? extends B> f) { this.g = checkNotNull(g); this.f = checkNotNull(f); } @Override public C apply(@Nullable A a) { return g.apply(f.apply(a)); } @Override public boolean equals(@Nullable Object obj) { if (obj instanceof FunctionComposition) { FunctionComposition<?, ?, ?> that = (FunctionComposition<?, ?, ?>) obj; return f.equals(that.f) && g.equals(that.g); } return false; } @Override public int hashCode() { return f.hashCode() ^ g.hashCode(); } @Override public String toString() { return g + "(" + f + ")"; } private static final long serialVersionUID = 0; } 复合函数的支撑类的实现也比较直观,FunctionComposition 类内部持有需要复合的两个 Function 实例,然后在复合函数被调用的时候依次调用持有的两个函数。
一个有趣的地方是关于泛型声明,复合的时候需要声明 3 个类型,函数 $f$ 的入参类型 A ,函数 $f$ 的返回值类型(函数 $g$ 的入参类型) B,函数 $g$ 的返回值类型 C。初始化 FunctionComposition 的时候,函数 $f$ 的返回值类型却是 B 或 B 的子类。为什么函数 $f$ 的返回值类型能够放宽到 B 的子类呢?
原因就是“里氏替换原则”,派生类(子类)对象能够替换其基类(超类)对象被使用,所以函数 $f$ 的返回值类型如果是 B 的子类,也能够被函数 $g$ 正确处理。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

