用Python进行梯度提升算法的参数调整
引言
或许之前你都是把梯度提升算法(Gradient Boosting Model)作为一个“黑箱”来用,那么现在我们就要把这个黑箱打开来看,里面到底装着什么玩意儿。
提升算法(Boosting)在处理偏差-方差权衡的问题上表现优越,和装袋算法(Bagging)仅仅注重控制方差不同,提升算法在控制偏差和方差的问题上往往更加有效。在这里,我们提供一个对梯度提升算法的透彻理解,希望他能让你在处理这一问题上更加胸有成竹。
这篇文章我们将会用Python语言实践梯度提升算法,并通过调整参数来获得更加可信的结果。
提升算法的机制
提升算法是一个序列型的集成学习方法,它通过把一系列弱学习器集成为强学习器来提升它的预测精度,对于第t次要训练的弱学习器,它会更加重视之前第t-1次预测错误的样本,相反给预测正确的样本更低的权重,我们用图来描述一下:
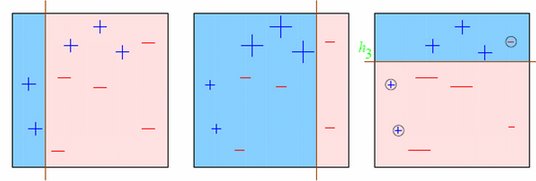
- 图一:生成的第一个弱分类器
- 所有的样本拥有相同的权重(用大小表示)。
- 决策边界成功预测了2个+样本和5个-样本。
- 图二:生成的第二个弱分类器
- 在图一中被正确分类的样本给予了一个更小的权重,而错分类样本权重更大。
- 这个分类器更加重视那些权重大的样本并把它们正确分类,但是会造成其他样本的错分类。
图三也是一样的,这个过程会循环多次直到最后,然后把所有的弱学习器基于他们的准确性赋予权重,并最终集成为强学习器。
梯度提升算法的参数
梯度提升算法的参数可以被分为三类:
- 决策树参数:单独影响每个弱学习器(决策树)的参数
- 提升算法参数:影响提升算法运行的参数
- 其他参数:整个模型中的其他参数
决策树参数
下面是对决策树参数的详细介绍,在这里我们用的是Python的scikit-learn包,或许和R语言的一些包不同,但是他们蕴含的思想是一致的。
- 分支最小样本量 :一个节点想要继续分支所需要的最小样本数。
- 叶节点最小样本量 :一个节点要划为叶节点所需最小样本数,与上一个参数相对应。
- 最小叶节点相对权重 :和上一个参数类似,只不过按照权重的定义转变为分数的形式。
- 树最大深度 :树的层次,树越深越有过拟合的风险。
- 最大叶节点量 :叶节点的最大数目,和树最大深度可以相互替代。
- 最大特征子集量 :选择最优特征进行分支的时候,特征子集的最大数目,可以根据这个数目在特征全集中随机抽样。
在定义下面两类参数之前,我们先来看一下一个二分类问题的梯度提升算法框架:
- 生成初始模型
- 从1开始循环迭代
2.1 根据上一个运行的结果更新权重
2.2 用调整过的样本子集重新拟合模型
2.3 对样本全集做预测
2.4 结合预测和学习率来更新输出结果 - 生成最终结果
这是一个非常朴素的梯度提升算法框架,我们刚才讨论的哪些参数仅仅是影响2.2这一环节里的弱学习器模型拟合。
提升算法参数
- 学习率 :这个参数是2.4中针对预测的结果计算的学习率。梯度提升算法就是通过对初始模型进行一次次的调整来实现的,学习率就是衡量每次调整幅度的一个参数。这个参数值越小,迭代出的结果往往越好,但所需要的迭代次数越多,计算成本也越大。
- 弱学习器数量 :就是生成的所有的弱学习器的数目,也就是第2步当中的迭代次数,当然不是越多越好,因为提升算法也会有过拟合的风险。
- 样本子集所占比重 :用来训练弱学习器的样本子集占样本总体的比重,一般都是随机抽样以降低方差,默认是选择总体80%的样本来训练。
其他参数
诸如 损失函数(loss) 、 随机数种子(random_state) 等参数,不在本文调整的参数范围内,大多是采用默认状态。
模型拟合与参数调整
我们用的是从Data Hackathon 3.x AV hackathon下载的数据,在预处理以后,我们在Python中载入要用的包并导入数据。
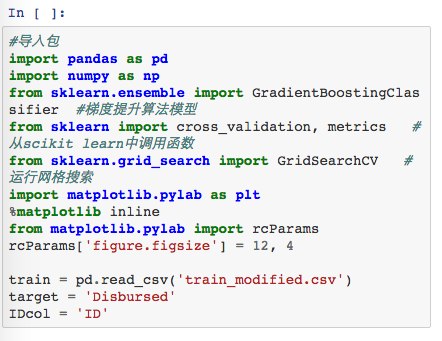
我们先定义一个函数来帮助我们创建梯度提升算法模型并实施交叉验证。

我们首先创建一个基准模型,在这里我们选择AUC作为预测标准,如果你有幸拟合了一个好的基准模型,那你就不用进行参数调整了。下图是拟合的结果:
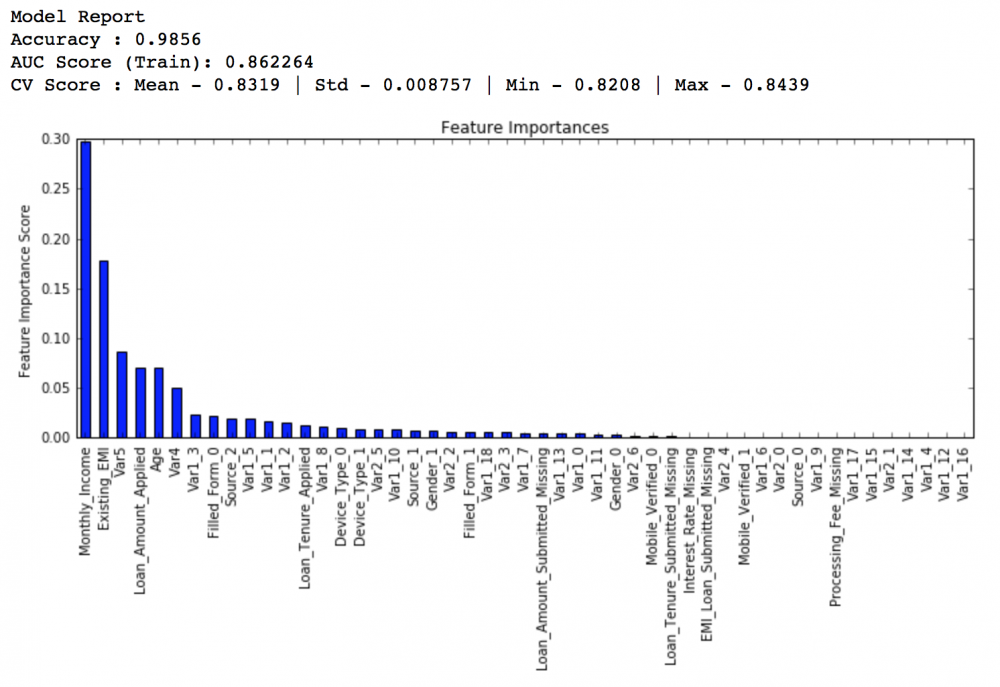
所以平均下来的交叉验证得分是0.8319,我们要让模型表现得更好一点。
参数调整的典型方法
事实上,我们很难找到一个最佳的学习率参数,因为往往小一点的学习率会训练更多的弱学习器从而使得集成起来的学习器表现优越,但是这样也会导致过度拟合的问题,而且对于个人用的电脑来说,计算成本太大。
下面的参数调整的思路要能够谨记于心:
- 先选择一个相对较高的 学习率 ,通常就是默认值0.1但是一般0.05到0.2范围内的数值都是可以尝试使用的。
- 在学习率确定的情况下,进一步确定要训练的 弱学习器数量 ,应该在40到70棵决策树之间,当然选择的时候还要根据电脑的性能量力而行。
- 决定好学习率和弱学习器数目后,调整 决策树参数 ,我们可以选择不同的参数来定义每一棵决策树的形式,下面也会有范例。
- 如果这样训练的模型精度不够理想,降低当前的学习率、训练更多的弱学习器。
调整弱学习器数量
首先先看一下Python默认的一些参数值: 分支最小样本量=500 ; 叶节点最小样本量=50 ; 树最大深度=8 ; 样本子集所占比重=0.8 ; 最大特征子集量=特征总数平方根 。这些默认参数值我们要在接下来的步骤中调整。我们现在要做的是基于以上这些默认值和默认的0.1学习率来决定弱学习器数量,我们用 网格搜索(grid search) 的方法,以10为步长,在20到80之间测试弱学习器的最优数量。

输出结果显示,我们确定60个弱学习器时得分最高,这个结果恰巧比较合理。但是情况往往不都是如此:如果最终结果显示大概在20左右,那么我们应该降低学习率到0.05;如果显示超过80(在80的时候得分最高),那么我们应该调高学习率。最后再调整弱学习器数量,直到进入合理区间。
调整决策树参数
确定好弱学习器数量之后,现实情况下常用的调参思路为:
- 调整 树最大深度 和 分支最小样本量 。
- 调整 叶节点最小样本量 。
- 调整 最大特征子集量 。
当然上述调参顺序是慎重决定的,应该先调整那些有更大影响的参数。 注意: 接下来的网格搜索可能每次会花费15~30分钟甚至更长的时间,在实战中,你可以根据你的计算机情况合理选择步长和范围。
首先我们以2为步长在5到15之间选择树最大深度,以200为步长在200到1000内选择分支最小样本量,这些都是基于我本人的经验和直觉,现实中你也可以选择更大的范围更小的步长。

从运行结果来看,选择深度为9、分支最小样本量为1000时得分最高,而1000是我们所选范围的上界,所以真实的最优值可能在1000以上,理论上应该扩大范围继续寻找最优值。我们以200为步长在大于1000的范围内确定分支最小样本量,在30到70的范围内以10为步长确定叶节点最小样本量。

最终我们得到了分支最小样本量为1200,叶节点最小样本量为60。这个时候我们阶段性回顾一下,看之前的调参效果。

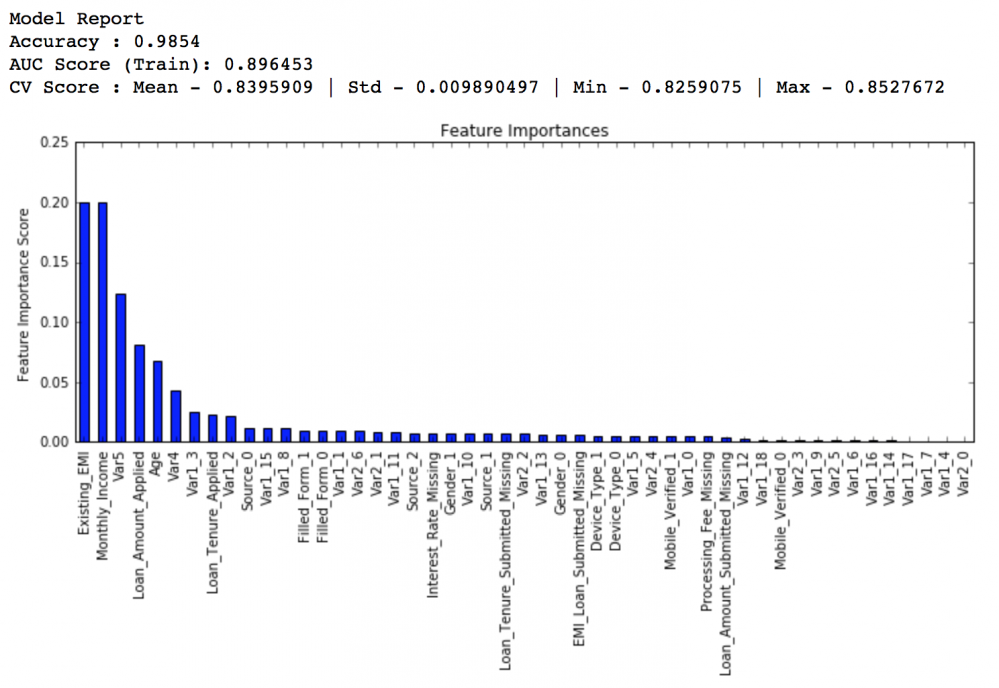
如果你对比了基准模型和新模型的特征重要程度,你会发现我们已经能够从更多的特征中获其价值,现在的模型已经学会把凝视在前几个特征的目光分散到后面的特征。
现在我们再来调整最后的决策树参数—最大特征量。调整方式为以2为步长从7到19。
最终结果显示最优值是7,这也是算法默认的平方根,所以这一参数的默认值就是最好的。当然,你也可以选择更小的值来测,毕竟7同时是我们所选的范围下界,但我选择安于现状。接下来我们调整子集所占比重,候选值为0.6、0.7、0.75、0.8、0.85、0.9。
从结果来看,0.85是最优值。这样我们就获得了所有的调整后的决策树参数。最后看一下我们的调参结果:
- 分支最小样本量 :1200
- 叶节点最小样本量 :60
- 树最大深度 :9
- 最大特征子集量 :7
- 样本子集所占比重 :85%
调整学习率
现在我们的任务是重新降低学习率,寻找一个低于默认值0.1的学习率并成比例地增加弱学习器的数量,当然这个时候弱学习器的数目已经不再是一开始调整后那个最优值了,但是新的参数值会是一个很好的基准。
当树增多的时候,交叉验证寻找最优值的计算成本会更大。为了让你对模型表现有个直观的把握,我计算了接下来每次调试后模型的 private leaderboard得分 ,这个数据是不开源的,所以你没有办法复制,但是它对你理解有帮助。
首先我们降低学习率到0.05,弱学习器数量增加到120个:

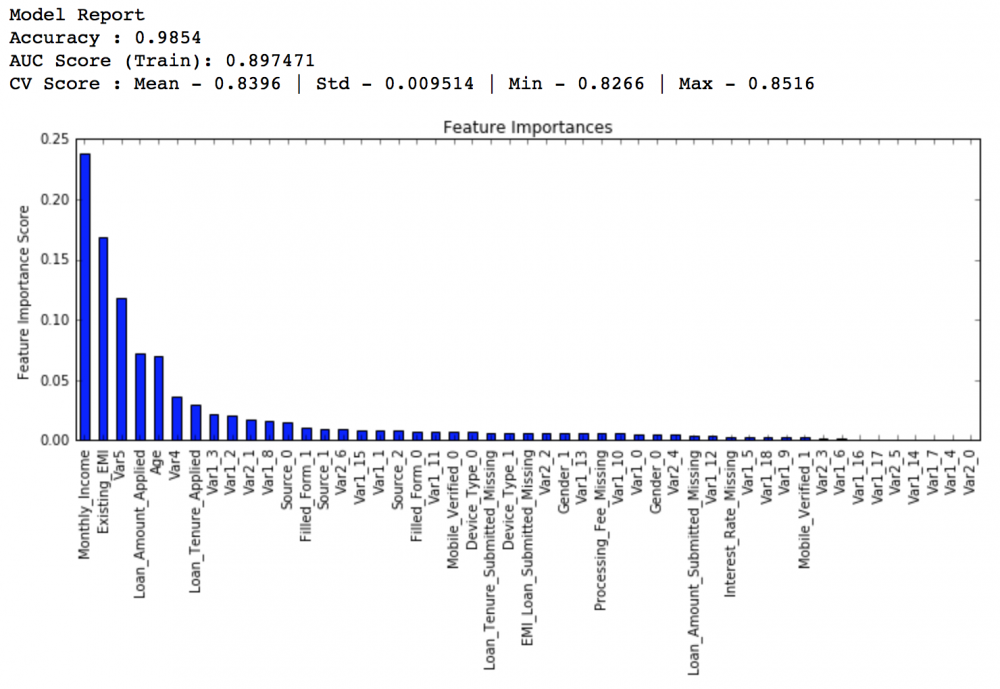
private leaderboard得分:0.844139
学习率降低到0.01,弱学习器数量增加到600个:
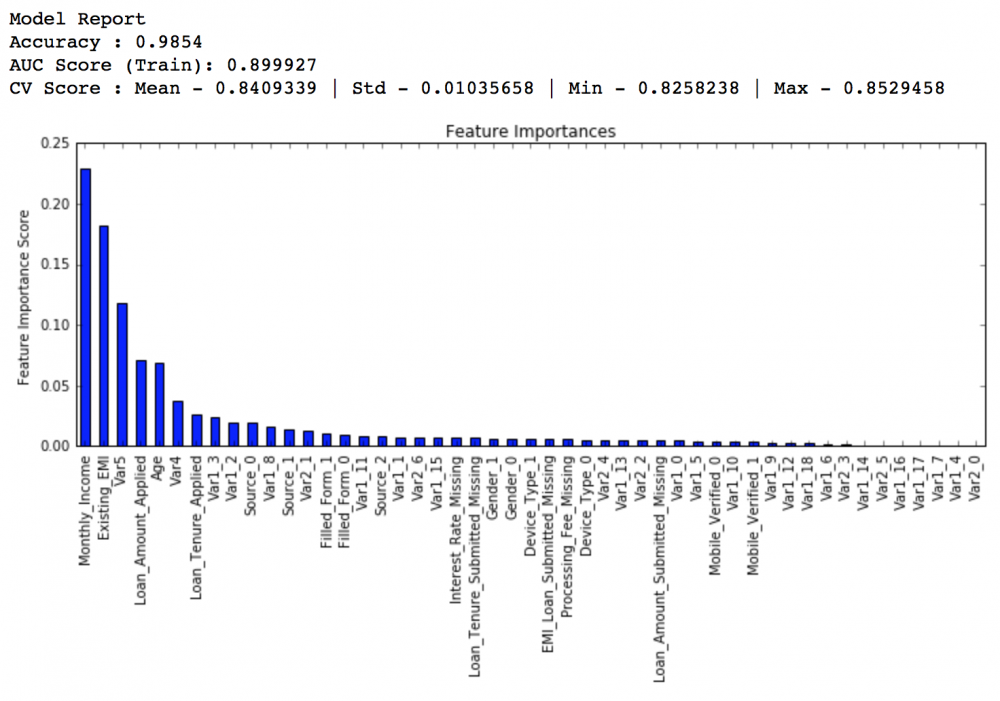
private leaderboard得分:0.848145
学习率降低到0.005,弱学习器数量增加到1200个:
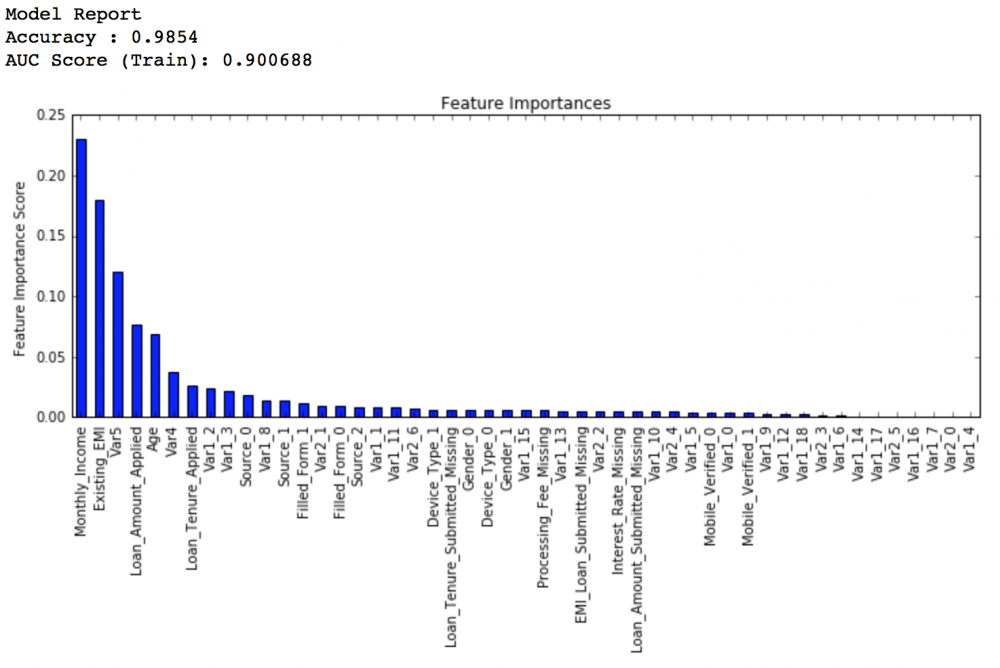
private leaderboard得分:0.848112
可以看到得分降低了一点点,我们再做一次调整,只把弱学习器数量增加到1500个:
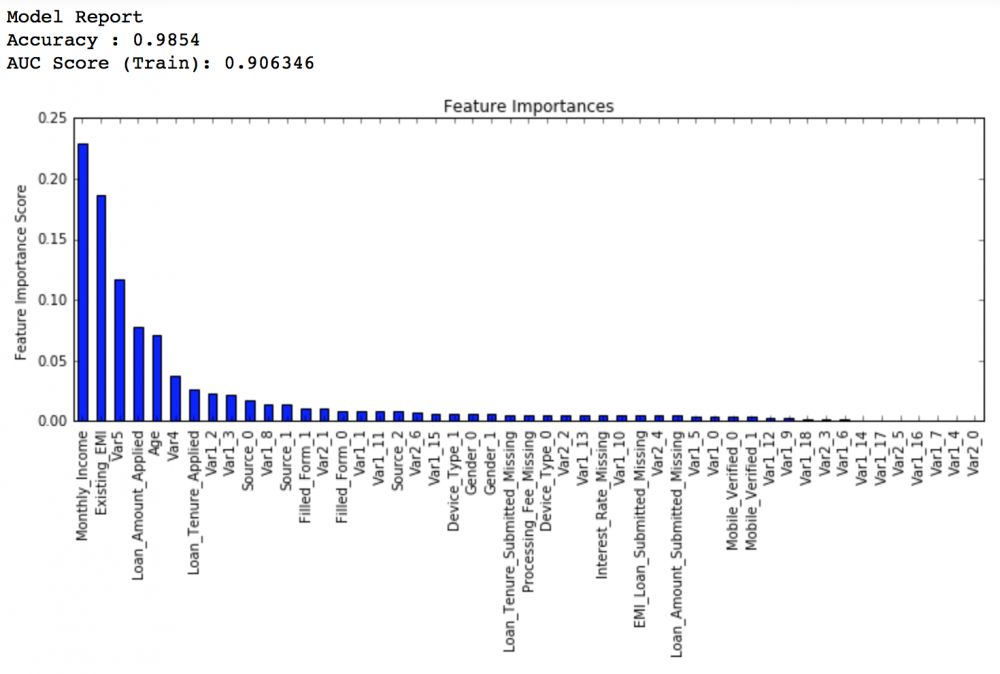
private leaderboard得分:0.848747
到此为止,我们可以看到得分由0.844到0.849,可以视为是比较显著的变化。所以最终我们确定的学习率为0.005,弱学习器数量为1500,当然这个计算成本是很高的。
结语
本文基于优化梯度提升算法模型,分为三个部分:首先介绍了提升算法的思想,接下来讨论了梯度提升算法的参数分类,最后是模型拟合和参数调整,并结合Python予以示例。关于详细的代码等资料可以去作者的 GitHub 上寻找。
原文作者:Aarshay Jain
译者:Teacup
原文链接: https://www.analyticsvidhya.com/blog/2016/02/complete-guide-parameter-tuning-gradient-boosting-gbm-python/
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

