
揭开机器学习的面纱
你周围的人是否都在谈论着“机器学习”?而你是否也听说过一些算法技术却仍旧缺乏一个全局的认识?本文也许就是一个好的起点……
智力的新纪元
在科学界,机器学习是目前很热门的话题。通过把计算机和人类的能力相结合,一些相当复杂甚至是难以想象的问题正在被逐个突破。
如今的机器可以更容易地处理不断产生的大量数据,也能够对复杂的科学发现进行破译。另一方面,研究人员已经承认机器学习具有用于广泛领域的潜力,并且最终可以付诸实践。
当开始着手研究机器学习,我们会发现这其中很多的算法技术对于统计学家、工程师、程序员、数学家和金融工程师而言也许并不陌生。这是因为这些算法技术实际上已经被研究很多年了。“机器学习”是一个相对而言的新名词,但对于数据科学家而言这并不是一个完全陌生的领域。
本文汇总了原作者在研究初时遇到的一些有趣的实例,从而有助于理解机器学习的相关内容是如何联系在一起,并列出其知识体系各部分之间的不同之处,最终针对现有的项目,选择最佳的方案。
虽然本文并没有提出什么新的观点,甚至算不上专业,但原作者希望本文可以帮助那些对入门机器学习仍有疑惑的人。

“机器学习”是什么?
在机器学习领域,我们让机器自主学习。他们通过给定数据集里的案例进行学习。人们只需要利用机器得到的结论去改善方案、提高效率、实现自动化流程和任务。
让我们引用该领域两位巨擘的话来更精确地解释:
“机器学习是让计算机在不被明确编程的情况下运作的科学。” ——安德鲁·吴(Coursera)
“一种计算机程序,如果它的任务记为T,用P来测度性能,并通过经验E来改善的话,它就会不断地从经验E中学习,从而满足某类任务T和性能指标P。”——汤姆·米歇尔(1997)
我曾经听说过这个!
听起来,“机器学习”(简称为ML)和你之前了解的其他科学十分相似。现在,让我们看看它们之间究竟有什么不同。
或许,你对“人工智能”(简称为AI)更加熟悉。人工智能是通过复制人类的基本意识来开发系统项目从而独立完成预设好的目标的科学。很大程度上,机器学习可以算作是通过创造算法来调整机器行为从而接近经验数据的人工智能。
很多机器学习的内容来源于统计学科,只不过叫法不同罢了。与传统的统计学科不同,在机器学习中机器不对数据做推断,它得到的结论也不会被最初的诸多假设所限定。回想一下你在统计学中听到了多少次“假设X服从正态分布”或者“给定独立同分布的随机变量”。你有想过这些假设在现实中真的可能成立吗?
然而,机器学习方法的一个缺点在于我们很难得到对变量之间关系的直观解释,而这恰恰是统计推理所擅长的。为了实现更精确的预测,机器学习得到的模型会变得相当复杂以至于难以去解释。
失去解释性是绝大多数数据科学家不愿意见到的,但这也是为了解决复杂问题必须付出的代价。通常来说,在机器学习中最重要的是解决整个问题而不需要去分析细节。你能够不依赖其他技术发现数据背后隐藏的信息吗?尝试在下面这个色彩丰富的图中找出隐藏的三个物体,你能看到什么?

“机器学习”和“数据挖掘”也很相似。然而数据挖掘主要是为了发现数据中未知的模式和关系,机器学习则是在实际应用中通过先前得来的信息来处理新的数据集。
问题的关键在于平衡好性能和解释性的关系,比如说,预测准确性 vs 解释性。
如果你仍旧对机器学习与其他学科的异同留有困惑,你可以在 “这里” 和 "这里" 找到机器学习和人工智能、统计、数据挖掘、深度学习的比较。
揭开机器学习的面纱
理解机器学习和学习如何入门最好的方法莫过于理解其知识体系各部分之间的不同之处。熟悉机器学习的人可能知道机器学习的主要模式就是监督学习和无监督学习了。
简而言之,监督学习就是我们已经通过之前已知的数据知道结果了。
此时,我们想建立一个模型来预测未知数据的结果。我们将已有的数据和结果输入机器,让它从这两者之间的关系中不断学习从而建立模型。
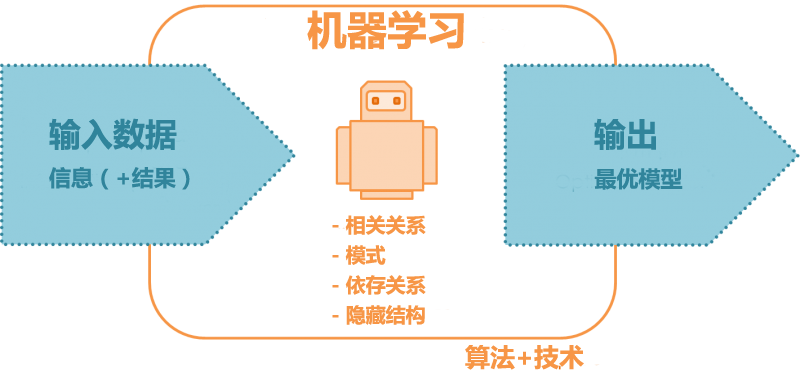
在无监督学习中,我们则是希望发现数据中未知的结构或者是趋势。原数据不含任何的标签,但我们希望可以对数据进行整合(分组或者聚类),或是简化数据(降维、移除不必要的变量或者检测异常值)。
我们进一步区分这两个模式的子类别,并在下图中展示出来:
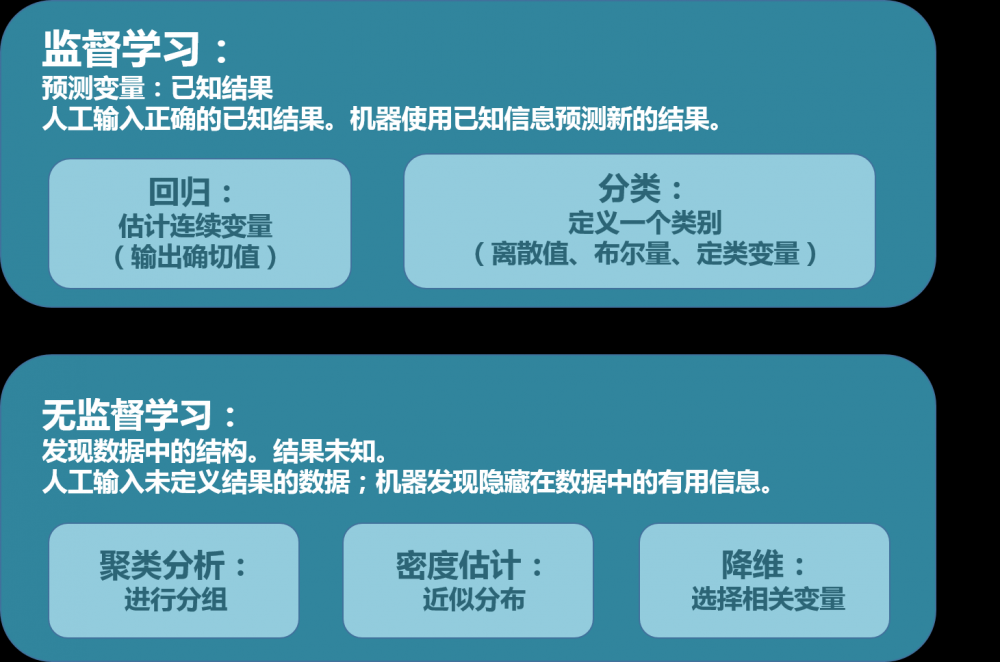
监督学习可以根据预测变量的类型再细分。如果预测变量是连续的,那这就属于回归问题。
而如果预测变量是独立类别(定性或是定类的离散值),那这就属于分类问题了。
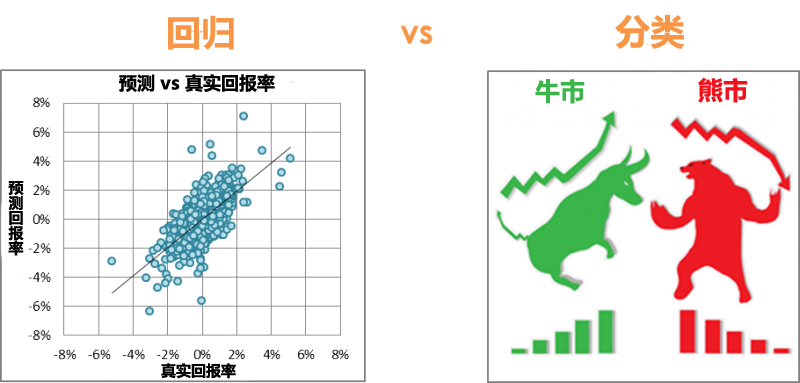
举例来说,如下两图所示:
- 预测 S&P500 指数下周的回报率。由于回报率是连续变量,这就是回归问题。
- 预测欧元兑美元的趋势是上升还是下降。这里只有两种可能性:牛市或熊市。这就是分类问题。
无监督学习可以再细分为聚类分析、密度估计和降维。
聚类分析中,数据通过相似性或者距离来分组。密度估计中,模式和数据用分布函数或是定义的形状表示。降维中,通过移除重复或者不必要的变量实现更简洁的数据结构。
我们也可以根据学习的类型和所需解决的问题对特定的方法进行分类,如下图所示:
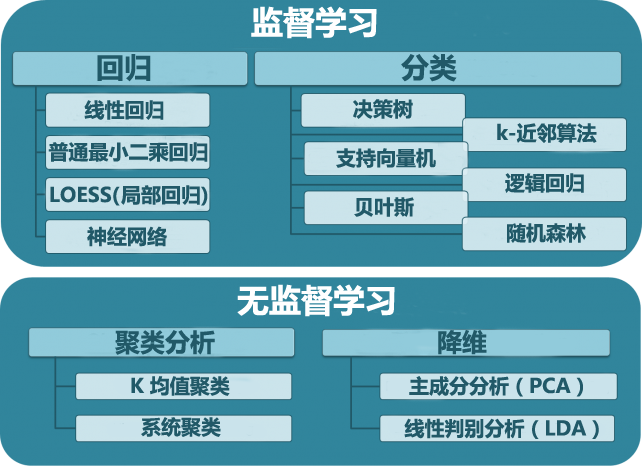
“MLmastery” 和 “analyticsV” 等博文对机器学习主要的算法做了清晰实用的解释。
其他细节
机器学习技术在应用之前使用“训练+检验”的模式(通常被称作”交叉验证“)。
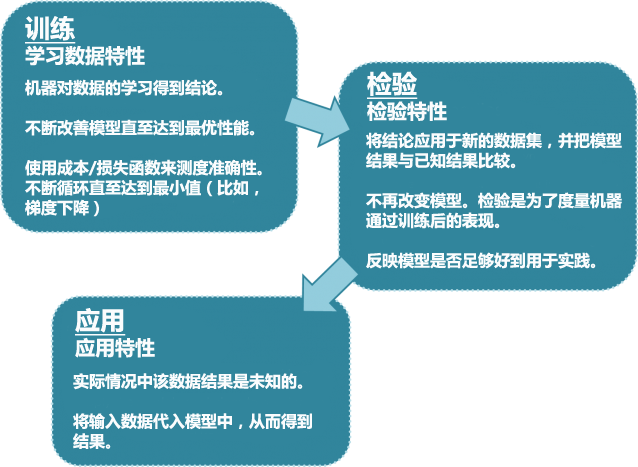
机器会不断地尝试参数的组合,因此我们要警惕“过拟合”和“运行时间”的问题。在训练阶段过高的准确性往往会造成过度优化,以至于在检验阶段会有较差的结果。同时,为了减小成本函数到足够的水平,算法也会花很长时间直至收敛到最终的结果。
关于实际应用
机器学习可谓是无处不在,在日常生活中有大量相关实例,只是我们没有意识到。比如说,机器学习被用于搜索引擎、过滤垃圾邮件、面部识别、社交网络分析、市场细分、数据分析、欺诈检测和风险分析等。
泛泛而谈是不足以说明问题的。通过将机器学习用于金融领域的实例,我们能看到将这些复杂的算法用于实际会带来多大的便利。
无监督学习技术可以用于分析和理解金融数据。比如说, 主成分分析(PCA) 可以用于资产配置, K 均值 可用来债券市场回报率的聚类, 其他聚类方法 可以再现 S&P 500指数的组成, ISOMAPS 算法可以分类不同行业的股票。
监督学习技术则非常适合用于分析金融数据。它可以实现预测和帮助制定投资风险策略。举例来说, 近邻算法 、 神经网络 、 决策树 、 随机森林 和 贝叶斯 这些都可以用来监测股市的市场变动趋势。
更多相关链接
不知道从何开始?可以尝试 “在Coursera上的机器学习课程” 或者用Python的 ”tool scikit-learn“ 。当然,你也可以在 ”Kaggle“ 上进行学习,”泰坦尼克号''实例很适合初学者。
想知道究竟什么算法才适合解决你的问题?不如去看看 “scikit learn” 和 “Azure” 。
如果你想开始编程并尝试一些实例, “caret Package” 中包含大量的相关细节、函数和案例。你也可以从 ”Python and R codes“ 中学到机器学习主要的算法。
不喜欢本文?想了解更多或想换个角度看? "detailed post" 介绍了机器学习的入门知识,或是阅读 "innovative introductory visualisation" 。
在机器学习中有很多不同的词实际上代表同一样东西。下图是对于输入和输出变量的常见的一些表达方式:
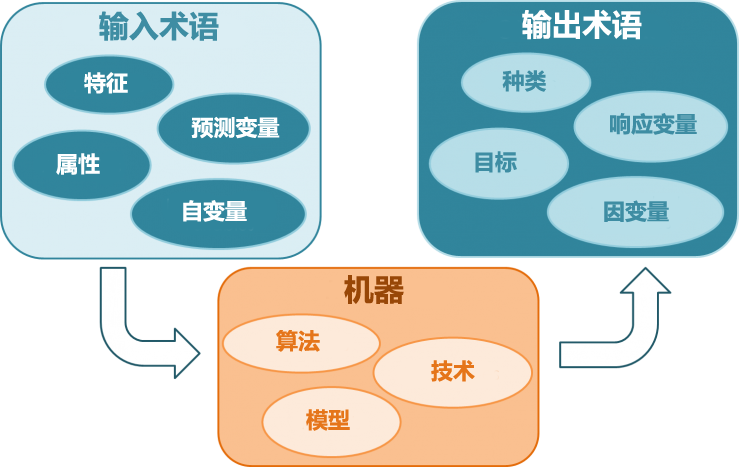
你也可以在 "Glossary" 找到更多与机器学习相关的术语。
原文链接: Machine Learning: A Brief Breakdown
原文作者: libesa
译作者: Vector
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

