隆重推荐Winston – 事件驱动的诊断和补救平台
Netflix通过一系列微服务造就了你所喜爱的产品。这些微服务的运维由不同团队和相应的工程师联手负责,我们并没有集中组建一个负责确保所有服务正常运行的运维团队。相反,我们会在工具方面进行大量投入,以帮助Netflix工程师确保所有服务高可用、高弹性地运行。今天我们想谈谈最近为Netflix工程师开发的一个工具: Winston 。
问题所涉及领域
假设Netflix有一个典型的中间层微服务,这是一个单一用途的服务,托管在AWS平台。该服务使用Jenkins构建,使用 Spinnaker 部署,并使用 Atlas 监控。在各种度量指标的基础上,我们使用Atlas堆栈语言配置了警报,Atlas可支持在出现警报后触发一系列预定义操作,主要可用于执行实例级别的补救(终止实例,重启动,从服务目录中移除等)、升级(通过邮件、传呼机),或发布至 SQS 以便进一步集成。
为降低复杂性并管理Atlas自身的弹性,上述范围之外其他已经得到支持的操作并不在Atlas框架的优先考虑范围内。这种自定义的诊断和补救措施被我们称之为Runbook。Runbook的托管和执行通常以下列形式进行:
- 向通过维基/文档记录这些Runbook的人,或负责编写相关工具和脚本的人发送邮件或传呼提醒。
- 通过自定义的微服务监听SQS中针对Atlas提供的集成点,并运行Runbook。
上述方法各有不足之处。上报给具体人员,让他们手工执行重复的任务,这种做法不能让工程师的宝贵时间得到最充分利用。没人喜欢三更半夜被传呼吵醒然后按照文档规定执行相关操作,或执行那些本可以通过脚本或工具轻松搞定的任务。
构建自定义的微服务,意味着应用程序团队必须付出额外的精力以确保这些服务能实现足够高的可用性和弹性,另外还需要构建与Atlas或所用其他监控工具的集成,管理部署生命周期和依赖项的淘汰周期,同时还要担心安全性和可靠性等问题。工程师不应该仅仅为了托管并执行业务逻辑中所嵌套的脚本,就处理这些与基础架构有关的冗繁任务。
Winston正是为了帮助工程师在无须管理基础架构和相关核心功能的前提下实现Runbook的自动化运行。也许你会好奇,Winston这个名字源自电影“低俗小说”中一个角色Winston Wolfe,电影中此人会通过“Runbook”解决各种问题,并为解决问题的过程创造一种受控的安全环境。
拯救者Winston来也
Winston为Netflix工程师提供了一种事件驱动的Runbook自动化平台。按照设计,该平台可以托管 Runbook ,并作为对警报等运维事件的响应运行这些Runbook。Winston的目标是为开发者提供Tier-1支持,帮助开发者免除重复的诊断和补救任务,在遇到相关事件后自动执行必要操作。
用户可以根据自己的实际用例通过提供下列参数配置Winston:
- 代码形式的Runbook(该平台的第一版仅支持在Runbook中使用Python代码)。
- 一个或多个触发该Runbook的事件(例如Atlas警报)。
随后Winston会提供下列功能,帮助Netflix工程师更轻松地构建、管理并运行自己的Runbook。
自助服务接口 - Winston Studio
最开始,我们的目标是让Winston成为工程师的自助服务工具。为改善该平台的易用性,使其更易于用作各种尝试和迭代,我们为用户创建了一种简单直观的界面。Winston Studio为新增自动化Runbook的加入、现有Runbook的配置、生产环境运行后的日志查看,以及Runbook的调试与生命周期管理提供了一站式解决方案。
下图是Netflix实时数据基础架构团队针对一个脱机的Kafka代理进行排错和补救时自动运行Runbook的屏幕截图。如图所示,用户可以编写代码让自己的Runbook自动运行,配置事件触发Runbook的执行,配置故障通知设置,此外也可以手工运行这套自动化机制对改动进行测试,随后再进行部署。
(点击放大图像)
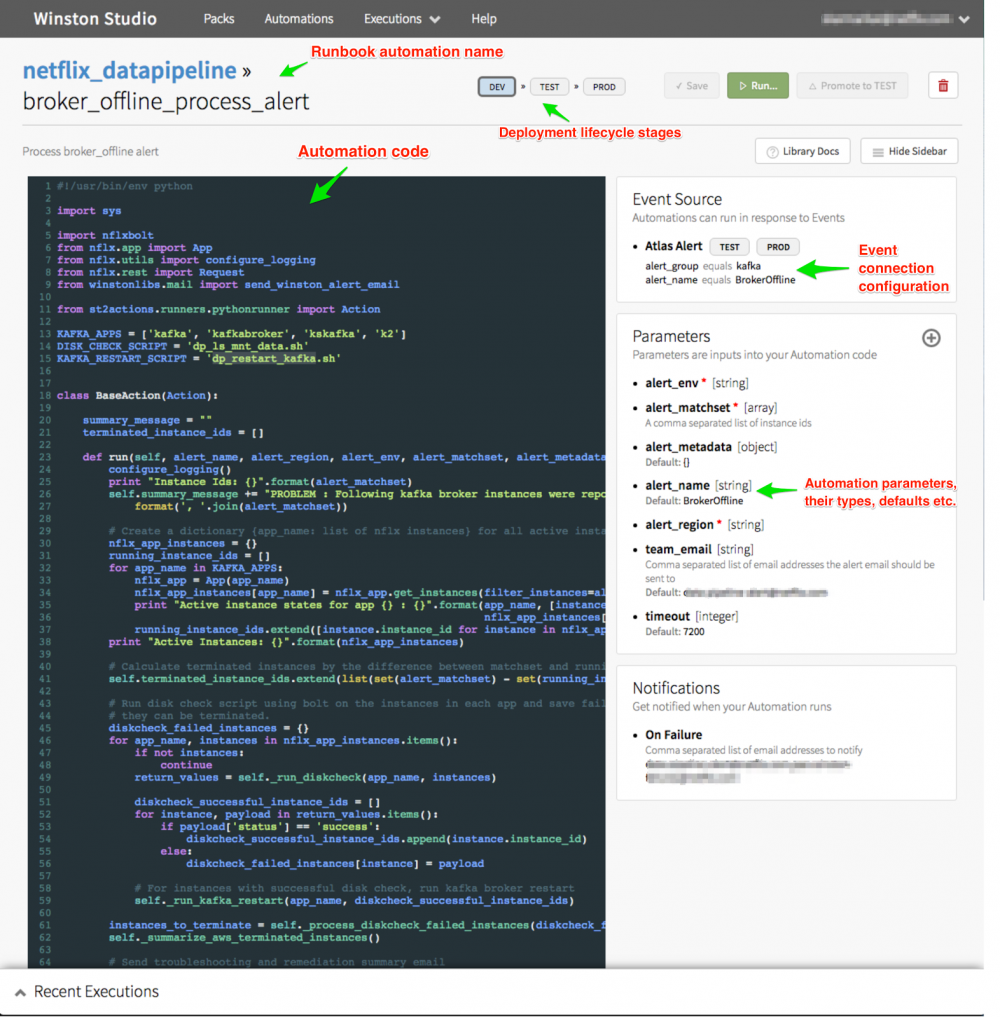
用户还可以通过Winston Studio查看上次执行状态以及具体的执行细节,如下图所示。
(点击放大图像)

Runbook生命周期管理
Winston针对Runbook的部署和管理方式提供了必要的辅助。该平台可支持为特定Runbook创建多个版本,每个版本针对一个环境(开发/测试/生产)。Winston中所有Runbook都存储在我们的代码持久化存储系统Stash中。该系统支持版本控制和必要的安全模式,很适合存储Runbook这样的代码。每个团队可在Stash中创建专用隔离仓库,每个环境(开发/测试/生产)都在仓储中呈现为专用分支。Winston还提供了自动化的推进(Promotion)和部署管线。推进可由工程师通过Studio手工触发,部署则可通过每次在Studio中推进或更新Runbook后触发。Runbook会在数分钟内跨越所有四个AWS地区部署给所有三个区域中全部的Winston实例。
HA部署
Winston可通过地区隔离和堆栈隔离的方式部署。地区隔离可避免地区故障(us-east-1地区故障不会影响us-west-2地区的执行)。堆栈隔离可将测试环境与关键的生产环境相互隔离,并可在将Runbook部署到生产环境前通过隔离的环境对其进行测试。我们还提供了开发环境,可在将Runbook部署到测试环境之前对其进行开发和手工测试。
如下图所示,计算和持久存储是相互隔离的。为实现数据弹性,以及在主要数据库故障后实现自动化的故障转移,我们使用了MongoDB副本集。同一地区和环境的多个实例会共享同一个MongoDB集群。Winston Studio只在部署时使用,正常运行时不需要,因此我们选择将Studio托管在一个单独的地区,但为了避免实例故障会将多个实例运行在同一个负载平衡器之后。
(点击放大图像)
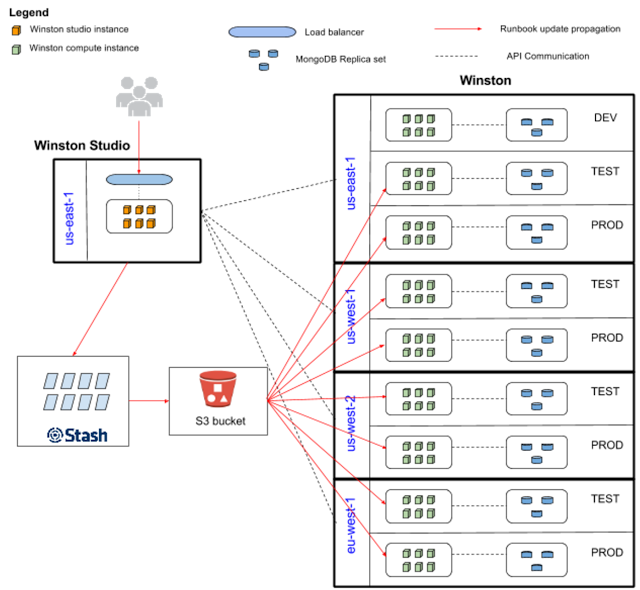
Winston Studio和Winston的部署
你可能会觉得S3 Bucket和Winston DEV集群之间缺少Runbook更新的传播路径(红色箭头)。不需要这个路径的原因在于,我们在Winston Studio和Winston DEV计算实例之间使用了共享的文件系统。这样当需要通过Winston Studio对Runbook进行多次更新和测试时有助于实现更快速的迭代。
仔细查看Winston的一个计算实例(如下图所示)可以发现,其中使用了一个SQS传感器处理传入的事件,并通过规则引擎将事件连接至Runbook,并通过操作执行器(Runner)执行不同Runbook,如下图所示。
(点击放大图像)
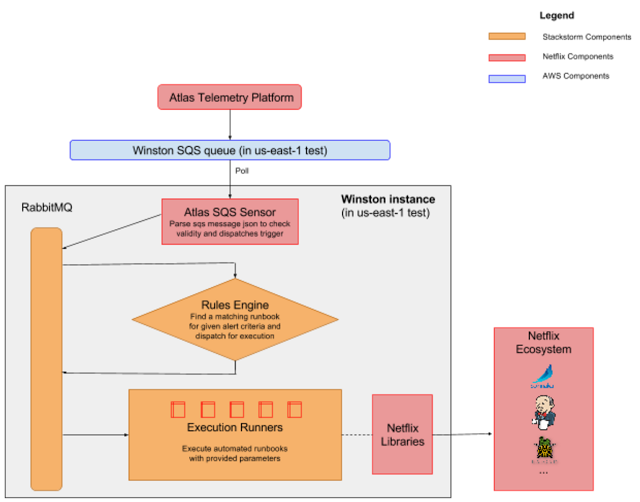
Winston实例的详细结构
集成
Winston通过与Atlas集成可充当管理事件传入管线的事件源。其中Atlas使用SQS操作作为集成钩子,并提供了大量外向集成API以便与Netflix生态系统通信,若有必要工程师可将其用在自己的Runbook中。这是一种持久的API,目的在于让自动化机制更易于编写。
支持技术
虽然Winston服务器是一种承载Runbook编排结果的好方法,但我们还需要通过某种方式执行实例级别的Runbook。我们构建了一个基于REST,名为BOLT的异步脚本运行器,该运行器以守护进程(Daemon)的形式运行在每个应用的每个AWS实例中,并为实例级别Runbook的托管和执行提供了所需平台。BOLT提供了一种自动化部署管线,并可通过BOLT Runbook进行迭代。
使用情况
我们在今年初将Winston部署到生产环境。目前共有7个团队参与到Winston的相关工作中,一共创建了22个不同的Runbook。平均来说我们每小时通过Winston执行Runbook 15次。以前这些执行需要工程师介入,因此必须以手工方式发起或跳过。目前常用的使用模式主要可分为下列几个类别:
- 误报筛选 – 来自Atlas的Squelch警报可使用具体服务所指定的自定义诊断步骤,这样有助于减少为了通知有关人员发送的传呼和电话数量。
- 诊断 – 收集上下文信息并提供给值班的工程师。
- 补救 – 在安全的前提下应用缓解措施以快速解决问题,让服务重新恢复正常运行状态。
- 代理(Broker) - 将警报事件传递到负责进行诊断和缓解的现有工具,并作为Runbook工作的一部分管理协议和数据模型的转换。
构建或是购买
刚发起该项目时,我们研究过是否要自行构建自定义解决方案,或是继续使用现有工具。在创建了原型,与业内同行进行交流,并分析了市面上不同解决方案后,我们选择使用一种“混合”的做法,在重新使用现有开源解决方案的同时针对缺少的功能构建自定义软件。我们决定使用 StackStorm 作为托管和执行Runbook的底层引擎。选择StackStorm原因在于该技术所提供的一些关键特性:
- 与我们试图解决的问题(事件驱动的Runbook自动化)非常匹配。
- 该技术是开源的,这样我们就可以非常详尽地审阅代码和体系结构质量。
- 高度可插拔(Pluggable)的体系结构意味着我们可以轻松地将其与Netflix环境集成。
- 产品团队为该产品提供了出色的,快速响应的支持。
通过使用StackStorm,我们无须“重新发明车轮”即可快速上手。这样即可更加专注于Netflix最需要的功能和集成方式,大幅降低将该平台投放市场所需的时间。
后续发展
我们希望对自己的产品进行大量改进和完善,不仅为了提高运维弹性,而且希望以此为基础为用户提供更多功能。目前一些关键的完改进类型如下。
弹性
- 我们正在通过容器技术设法为不同的执行提供更多资源(内存/CPU)和安全隔离。
- 我们打算为通过该平台传输的事件提供最低程度的保障。目前在一些情况下由于场景故障事件会被弃用。
功能
- Polyglot – 我们希望能够用更多语言创建Runbook(尤其希望支持Java)。
- 更多自助式功能 – 在事件和Runbook之间支持一对多和多对一关系以及自定义参数映射。
- 安全性 – 补救措施的自动化和杂乱的运用会造成相当大的破坏,我们希望设法提供更安全的功能(例如速率限制、跨事件关联)。
我们的目标是继续促进该平台在Netflix内部的应用,希望通过不断的尝试和完善,可以让该产品对Netflix服务的可用性产生更大、更有益的影响,并能让Netflix工程师的工作变得更简单。
总结
本文谈到了诸如Winston这样的产品对Netflix的意义,以及重新使用开源项目并自行开发必要工具以便快速落实该项目的方法。同时还介绍了Winston的高层次体系结构、部署模式、功能,以及目前的使用情况。
对Netflix和整个行业来说,软件的自动化诊断和补救依然是一个利基领域(Niche area)。我们的目标在于继续完善Netflix在这一领域的发展路径,为MTTR和开发者的生产力产生实质影响。Winston是这一努力方向上的举措之一,为工程师提供了一个恰当的平台,帮助他们为重复的任务实现自动化执行。如果这一领域以及我们所采用的方法让你兴奋,欢迎随时联系,我们很乐意与你展开合作。
作者: Sayli Karmarkar 和 Vinay Shah ,代表诊断和补救工程(DaRE)团队, 阅读英文原文 : Introducing Winston - Event driven Diagnostic and Remediation Platform
感谢杜小芳对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

